这篇文章一次性梳理 Qwen3 系列的全部 17 款模型:从首发到迭代、从旗舰到轻量、从通用到编码,并给出本地与云端的选择与部署建议。

Qwen3 系列发展路线图
第一阶段:首发(2025 年 4 月 29 日)
阿里推出 Qwen3 家族首批 8 款模型,覆盖多档 GPU 要求:
- MoE(专家混合)模型 2 款:Qwen3-235B-A22B、Qwen3-30B-A3B
- Dense(致密)模型 6 款:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B、Qwen3-0.6B
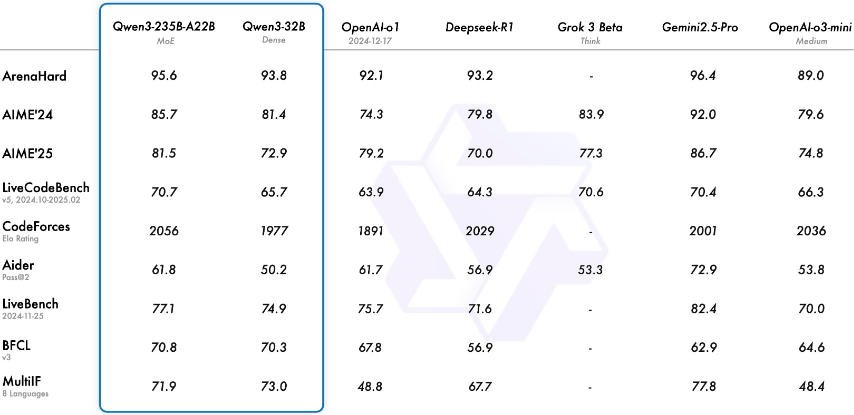
其中 Qwen3-235B-A22B 表现最优:在多项评分中超越 DeepSeek-R1、Qwen32B、OpenAI-o1;与 Gemini-2.5-Pro 的对比中各有胜场,官方给出了详尽对标数据。
Qwen3-30B-A3B 相较上一代 Qwen32B 同样全面升级。
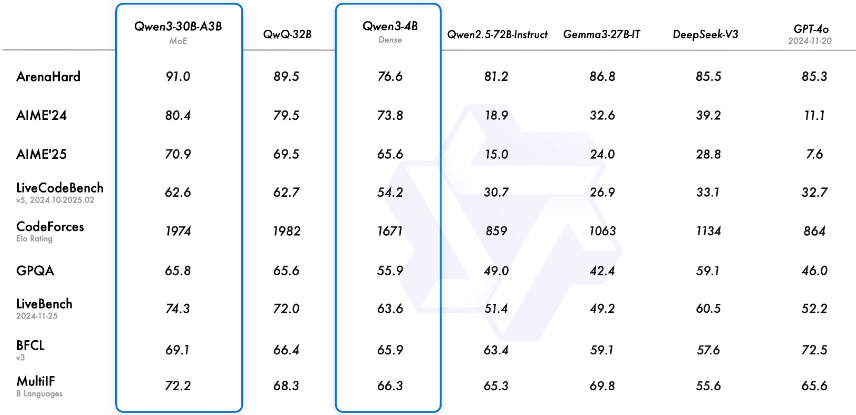
综合官方评测,首批 8 款模型的整体排序大致为:Qwen3-235B-A22B > Qwen3-32B > Qwen3-30B-A3B > …
本地部署建议:24G 显存可运行 Qwen3-32B 与 Qwen3-30B-A3B 的量化版本。
第二阶段:旗舰升级(2025 年 7 月 21 日—8 月 8 日)
Qwen3 迎来六款升级模型,覆盖三条主力尺寸,分别提供 Instruct(非思考)与 Thinking(思考)两种模式:
- Qwen3-235B-A22B-Instruct-2507、Qwen3-235B-A22B-Thinking-2507(基于上一代旗舰 235B 的升级,新的旗舰)
- Qwen3-30B-A3B-Instruct-2507、Qwen3-30B-A3B-Thinking-2507(30B 系列的全面升级)
- Qwen3-4B-Instruct-2507、Qwen3-4B-Thinking-2507(4B 轻量型号的双模式升级)
性能要点:
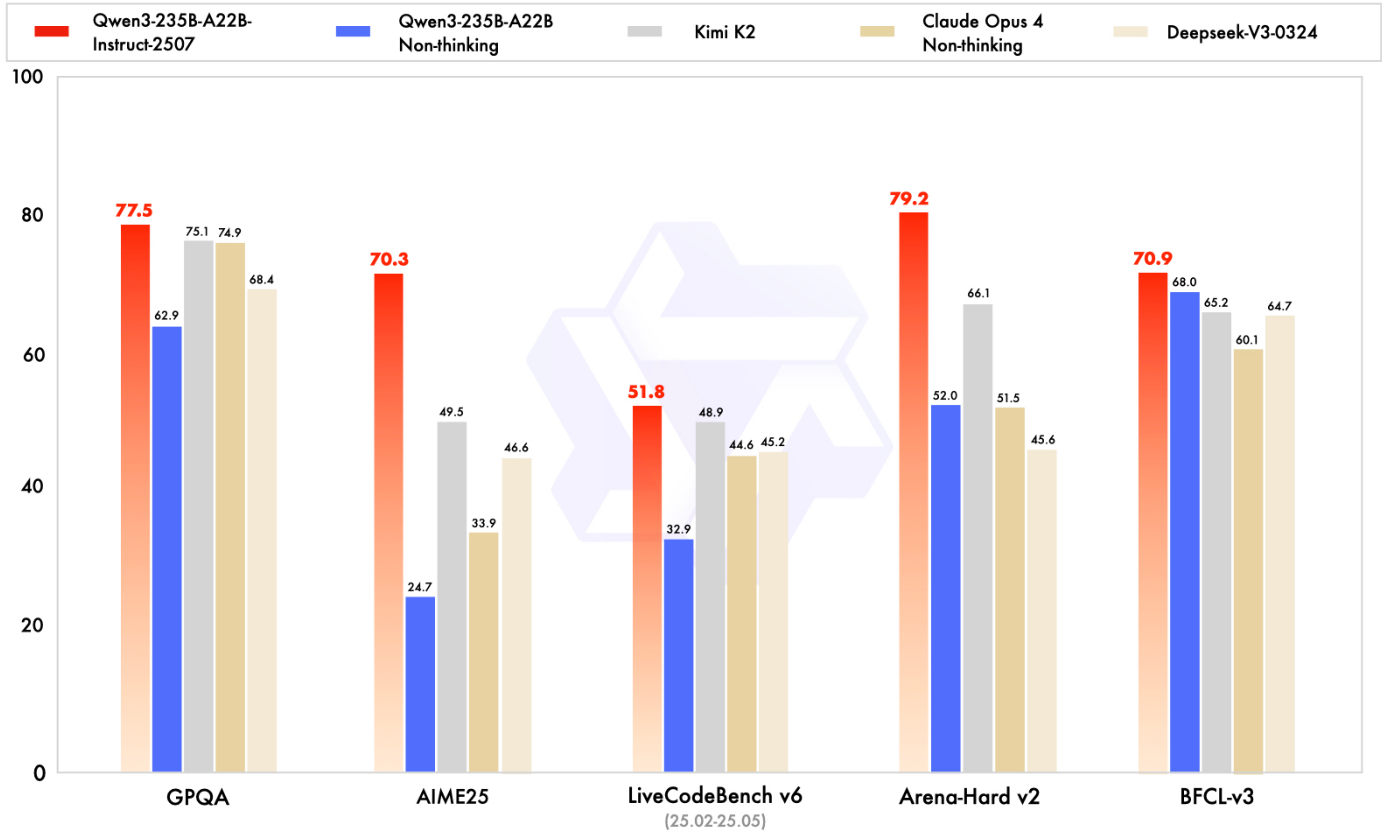
Qwen3-235B-A22B-Instruct-2507 对比开闭源同类,官方评测显示优势明显,可谓“遥遥领先”。
Qwen3-30B-A3B-Thinking-2507 在多数场景超过上一代 Qwen3-235B-A22B 的思考模式表现。
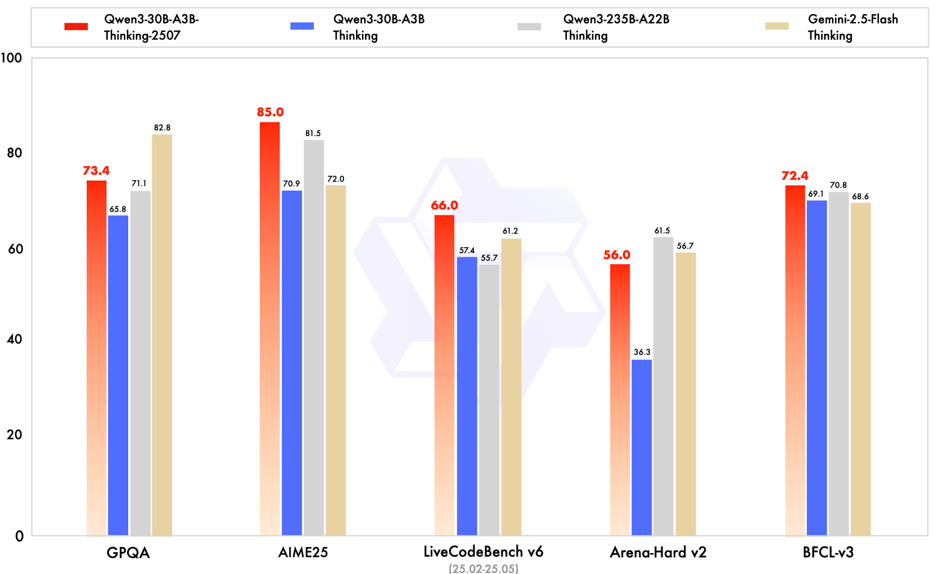
Qwen3-30B-A3B-Instruct-2507 对上一代 Qwen3-235B-A22B 的非思考模式实现全面且显著的超越。
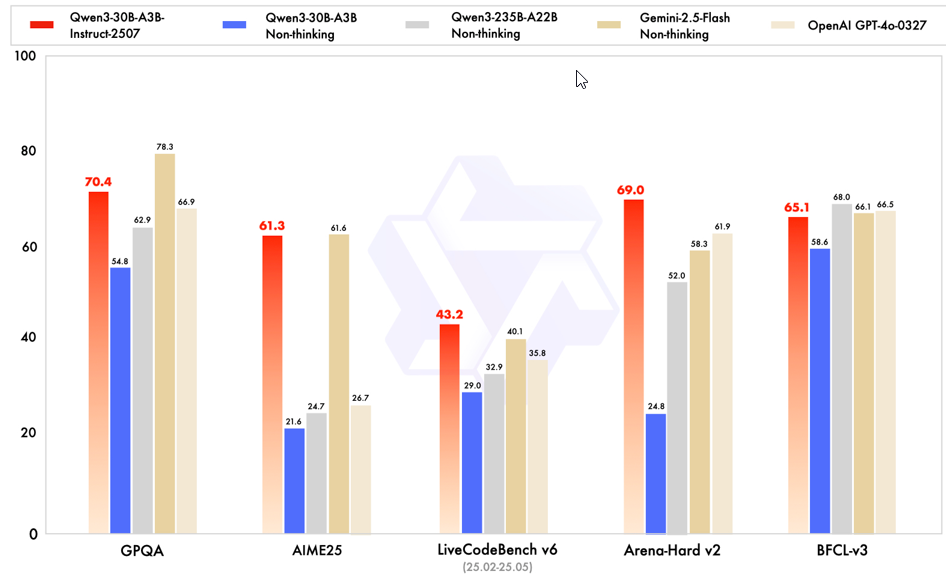
本地部署建议:24G 显存最高可运行 Qwen3-30B-A3B-Instruct-2507 与 Qwen3-30B-A3B-Thinking-2507 的量化版本。
此外,Qwen3 还提供两款垂直编码模型:
- Qwen3-Coder-480B-A35B-Instruct
- Qwen3-Coder-30B-A3B-Instruct
第三阶段:超旗舰预览(2025 年 9 月 5 日)
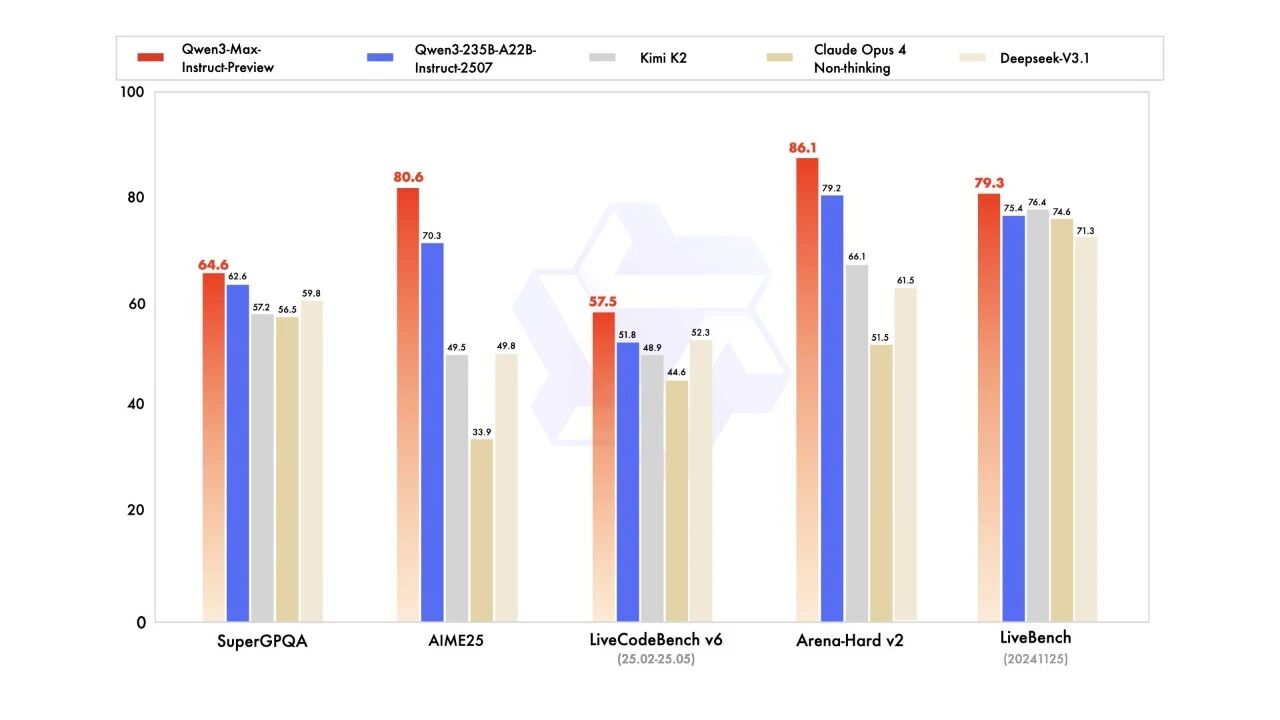
阿里发布当前系列最强模型 Qwen3-Max-Preview,预计很快会推出正式版 Qwen3-Max。该模型参数量达 1 万亿,是同系列 Qwen3-235B-A22B 的四倍。
官方评测显示,Qwen3-Max-Preview 在多个维度超越 Qwen3-235B-A22B-Instruct-2507 / Kimi K2 / Claude Opus4 / Deepseek-V3.1。
目前可在 https://chat.qwen.ai/ 免费体验。
选型与部署:远程与本地怎么选?
- 远程使用:优先选择 Qwen3-Max-Preview。
- 本地使用(24G 显存):推荐 Qwen3-30B-A3B-Instruct-2507 或 Qwen3-30B-A3B-Thinking-2507 的量化版本。
本地部署步骤(基于 Ollama)
- 先安装 Ollama
- 到 Ollama 官方库选择合适显存的模型:https://ollama.com/library/qwen3
- 下载过程中若速度突然变慢,可 Ctrl+C 终止;随后用下方命令继续(会从断点续传):
ollama run qwen3:30b-a3b-thinking-2507-q4_K_M
说明:若本地尚未下载该模型,上述命令会先拉取模型,再自动启动运行。
快速自测示例
>>> 0.8和0.11谁大
0.8 比 0.11 大。
解释:
- 0.8 可写作 0.80,便于对齐比较。
- 比较小数位:0.80 的十分位是 8,0.11 的十分位是 1,故 8 > 1。
- 分数视角:0.8 = 80/100,0.11 = 11/100,显然 80/100 > 11/100。
结论:0.8 > 0.11。