a16z 昨日在其 Charts of the Week 中放出一张图,将 GLM-5 与 Claude Opus 4.6 并列标注在 Artificial Analysis Intelligence Index 的时间轴上

原文指出:A proprietary model (Claude Opus 4.6) is still the 'most intelligent,' but the gap between it and the next best open weight model has closed substantially.(链接:a16z)
直译过来就是:在 a16z 的口径下,智谱 GLM-5 被视为当前“最佳开源模型”。
今天,GLM-5 发布了完整技术报告(40 页,arXiv)。
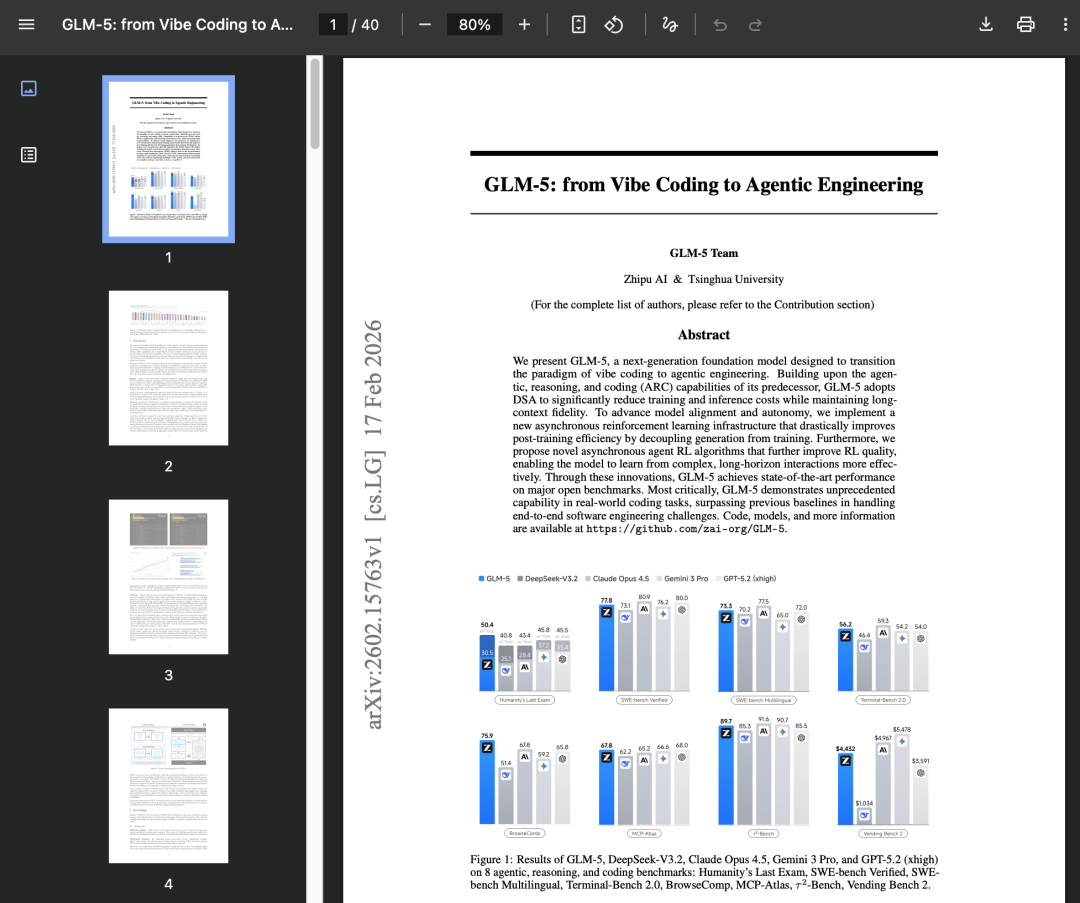
报告发布后,开发者社区迅速进入逐页学习模式,讨论最热的技术点包括:DSA 稀疏注意力(用 20B token 适配追平 DeepSeek 943.7B token 的效果)、完全异步的 Agent RL 训练框架、自研 slime RL 基础设施……以及那句“早就剧透的财富密码:智谱 + 龙虾”。
下面,我们把这份技术报告拆解成关键模块,逐块看清楚。
基座与基本面:744B 总参,40B 激活
在 Artificial Analysis Intelligence Index v4.0 上,GLM-5 得分 50,开源第一。

延续 MoE(Mixture of Experts)架构:总参数 744B,每次推理激活 40B,256 个专家,80 层。
对比 GLM-4.5:总参数从 355B 翻到 744B,激活参数 32B → 40B。
预训练数据由 23T token 增至 28.5T token(预训练 27T,中期训练 1.5T)。
在 LMArena(原 Chatbot Arena)上,GLM-5 在文本与代码竞技场均为开源第一,整体与 Claude Opus 4.5、Gemini 3 Pro 同档。

架构三大改动
GLM-5 相较 GLM-4 系列,在架构上有三处关键升级:
- MLA + Muon Split
- 多 token 预测(MTP)
- DSA 稀疏注意力
MLA + Muon Split
GLM-5 采用 Multi-latent Attention(MLA),与 DeepSeek-V3 同源。MLA 通过压缩 KV 缓存维度来节省显存,在长文本场景显著提速。
训练中团队发现:Muon 优化器与 MLA 的组合效果不如更简单的 GQA-8。于是提出 Muon Split:将原本对整块投影矩阵做的正交化,改为“按注意力头逐个进行”,让不同头各自独立更新。
效果追平 GQA-8。
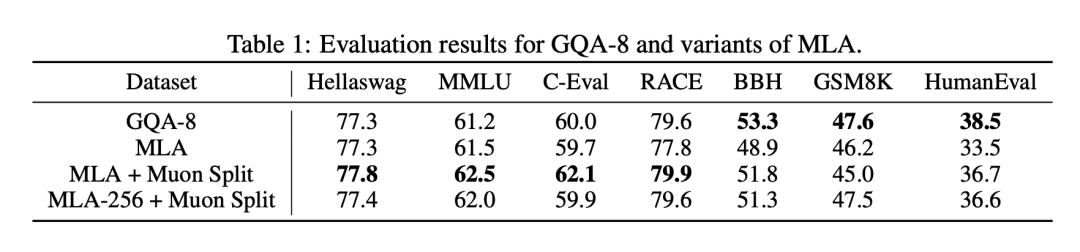
注意力分数在训练中自动保持稳定,无需额外裁剪。
推出 MLA-256 变体:单头维度 192 → 256,头数减少 1/3;总参数不变、性能持平,但推理计算量降低。
多 token 预测:参数共享的 MTP
推测解码是一种加速思路:用小模型先“猜”出后续几个 token,再让大模型验证,猜中即可省算力。
- DeepSeek-V3 训练只用 1 层 MTP,推理预测 2 个 token,但训练/推理不一致导致第二 token 猜中率偏低。
- GLM-5 在训练中使用 3 层 MTP,且三层共享同一套参数;推理时占用与 DeepSeek-V3 相当,但“猜中率”更高。
- 实测同样 4 步推测解码:GLM-5 平均接受长度 2.76,DeepSeek-V3.2 为 2.55。
DSA 稀疏注意力:长上下文核心提效
传统注意力计算是全量的,随上下文长度增长呈平方级膨胀,长上下文极其昂贵。
DSA(DeepSeek Sparse Attention)引入轻量级“索引器”,先快速扫所有 token,挑出与当前 token 最相关的 top-k(k=2048),只对这部分做注意力计算——基于内容选择而非位置。
在 GLM-5 中,进行 20B token 的 DSA 适配,即可追上 DeepSeek 使用 943.7B token 的效果(约 50 倍差距)。
流程:基础模型(中期训练结束后)→ 1000 步预热(只训练索引器,主模型冻结)→ 20B token 稀疏适配;总预算 20B token。
结果:DSA 模型在长上下文基准与原始 MLA 基本持平,SFT 训练损失曲线几乎重合。
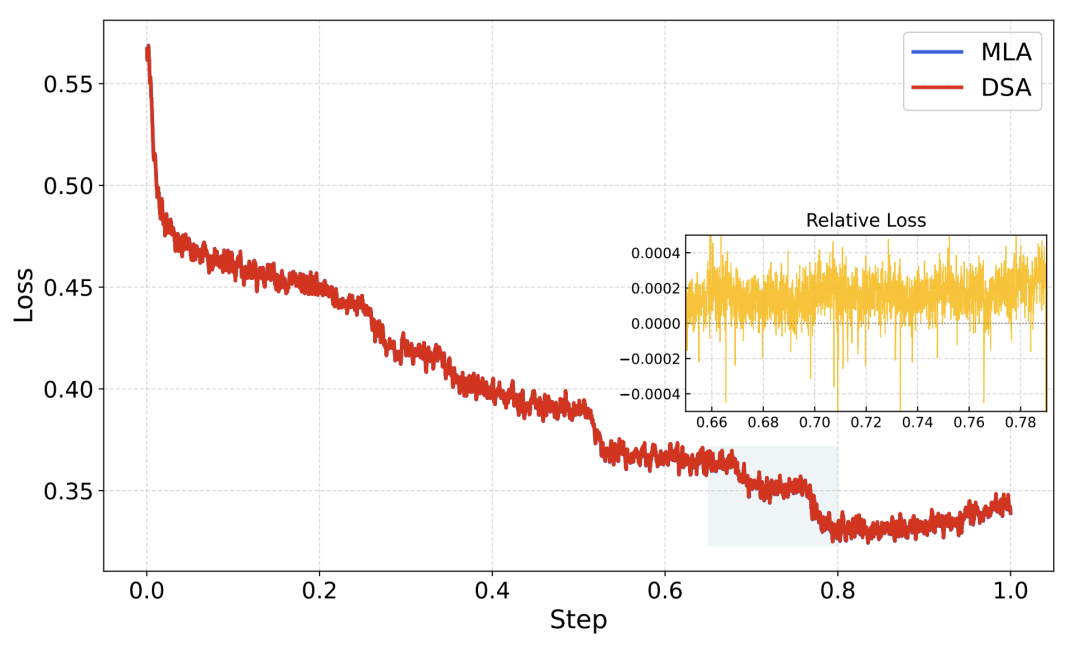
收益:长序列注意力计算降低 1.5-2 倍;Agent 推理动辄 200K 上下文,GPU 成本直接砍半。
消融对比:
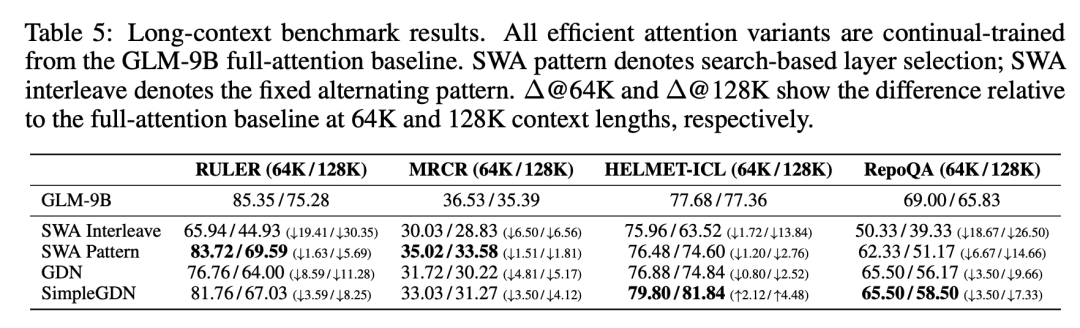
- 朴素滑动窗口交错:固定每隔一层用窗口注意力,在 128K 上下文 RULER 跌 30 分,基本不可用。
- 基于搜索的 SWA:束搜索最优层分配,效果更好,但细粒度检索仍丢 5-7 分。
- GDN / SimpleGDN:其中 SimpleGDN 在复用预训练权重方面效率最高。
- DSA:索引器做 token 级动态选择,不丢长程依赖。
数据:预训练与中期训练全面升级
网页数据
在 GLM-4.5 管线基础上新增 DCLM 分类器(基于句子嵌入),补捞标准分类器漏掉的高质量内容。
训练“世界知识分类器”(用 Wikipedia 条目 + LLM 标注数据),从中低质量网页中筛选有价值的长尾知识。
代码数据
刷新主要托管平台快照,模糊去重后 unique token 增加 28%。
修复 Software Heritage 元数据对齐问题。
为 Scala、Swift、Lua 等低资源语言训练专用分类器。
数学与科学
来源:网页、书籍、论文;由 LLM 打分,仅保留最具教育价值的部分。
长文档采用分块聚合评分;严格排除合成与 AI 生成数据。
中期训练
上下文窗口三阶段扩展:
- 32K(1T token)
- 128K(500B token)
- 200K(50B token)
GLM-4.5 上限为 128K;新增 200K 主要应对超长文档与多文件代码库。
软件工程数据扩容:放宽仓库级筛选拿到约 1000 万 Issue-PR 对,同时加强单个 issue 的质量过滤;最终 Issue-PR 数据约 160B token。
长上下文数据包含自然与合成数据;合成部分采用 NextLong / EntropyLong 构建长程依赖;在 200K 阶段引入多种 MRCR 变体,增强超长多轮对话召回。
训练工程:让 744B 模型“跑得起来”
- MTP 布局优化:将 MTP 输出层与主输出层放在流水线最后一个 stage 共享参数,其余模块前移,平衡各 rank 显存。
- ZeRO2 梯度分片:每个 stage 仅存 1/dp 梯度,配合双缓冲,在不增加同步开销下显著降显存。
- Muon 优化器零冗余通信:all-gather 限定在本 rank 的参数分片范围。
- 流水线激活卸载:前向完成后按层卸到 CPU,反向时再加载,与计算重叠。
- 序列分块输出投影:长序列下输出层与 loss 显存峰值高,按序列维度分块处理。
- INT4 量化感知训练(QAT):在 SFT 阶段即推进,开发与推理 bit-level 对齐的量化 kernel。
后训练全流程
GLM-5 的后训练是一条完整流水线:SFT → Reasoning RL → Agentic RL → General RL → 跨阶段在线蒸馏。
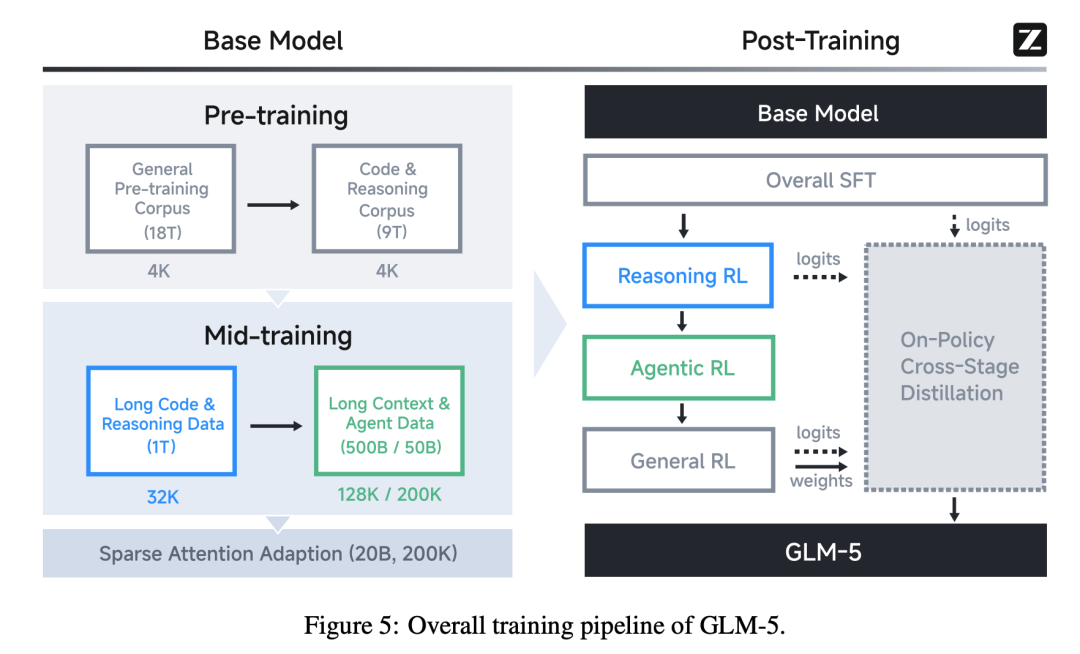
SFT
- 数据三大类:通用对话(问答、写作、角色扮演、翻译、多轮、长上下文)、推理(数学、编程、科学)、编程与 Agent(前后端代码、工具调用、Coding Agent、搜索 Agent)。
- 最大上下文长度扩至 202,752 token。
- 三种“思考模式”:
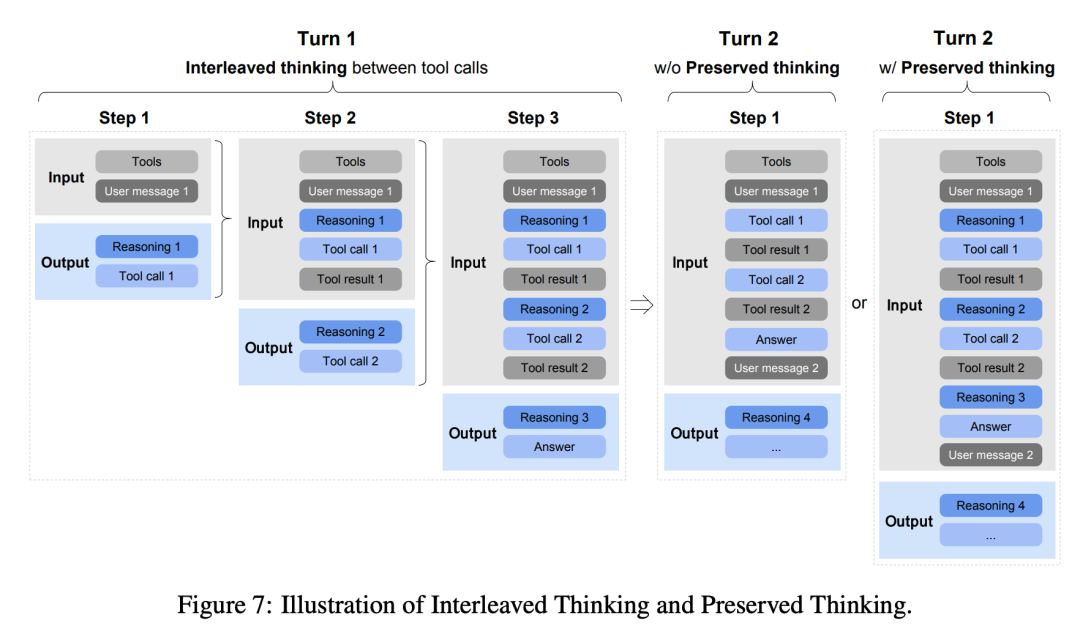
- 交错思考(Interleaved):每次响应和工具调用前都先思考一轮,提升遵循与生成质量。
- 保留思考(Preserved):在 Coding Agent 场景,多轮间保留所有思考,不重推导;适合长程复杂任务,降低信息丢失。
- 轮级思考(Turn-level):按轮次开关;简单请求关闭降延迟,复杂任务打开提精度。
- 编程与 Agent 的 SFT 数据通过专家 RL 与拒绝采样提质;错误片段保留但在 loss 计算中掩码,模型能“看见错误并学会纠错”,却不会被训练去复现错误。
Reasoning RL
- 算法基于 GRPO + IcePop;明确区分“训练模型”与“推理模型”,并移除 KL 正则以加速训练。
- 纯 on-policy:group size 32、batch size 32。
- 关键工程发现:DSA 索引器的 top-k(k=2048)若使用 CUDA 非确定性实现,RL 会迅速崩溃(同一输入两次排序不同,导致熵骤降与性能退化)。最终全程采用原生 torch.topk,并在 RL 阶段冻结索引器。
- 混合训练领域:数学、科学、代码、工具集成推理(TIR)。
- 难度过滤:仅保留 GLM-4.7 做不出、但 GPT-5.2 xhigh / Gemini 3 Pro Preview 能做出的题目。
Agentic RL
核心挑战在于 rollout 时间极长且任务差异巨大:一条 SWE 任务可能几分钟,另一条半小时;同步 RL 会被最慢任务拖垮 GPU 利用率。
- GLM-5 采用完全异步:
- 训练 GPU 与推理 GPU 物理分离。
- 推理端持续生成轨迹,凑够一批即发送训练端。
- 推理端权重每隔 K 步与训练端同步。
- Multi-Task Rollout Orchestrator:不同 Agent 任务(SWE 修 bug、终端操作、搜索问答)作为独立微服务注册到中央编排器,控制任务比例与生成速度,支持 1000+ 并发。
- 为保证异步稳定,三项关键设计:
- TITO(Token-in-Token-out):训练直接消费推理引擎产生的 token ID 与元数据,避免文本往返造成的 re-tokenization 偏差。
- 直接双侧重要性采样:用 rollout 记录的对数概率作为行为代理,计算 r_t(θ) = π_θ / π_rollout;超出信任域 [1-ε_l, 1+ε_h] 的 token 屏蔽梯度。
- 样本过滤:记录每条轨迹的模型版本号,版本差距超过阈值的丢弃;因环境崩溃造成失败的样本也去除。
- DP-aware 路由:同一多轮 Agent 任务通过一致性哈希路由到同一个 DP rank,复用 KV cache,预填充成本与增量 token 成正比。
General RL
- 优化目标三维度:正确性(指令遵循、逻辑一致、事实准确、无幻觉)、情商(同理心、洞察力、自然表达)、特定任务能力(写作、问答、角色扮演、翻译等)。
- 奖励信号三种混合:规则奖励(精确但覆盖窄)+ 判别式奖励模型 ORM(低方差但易 reward hacking)+ 生成式奖励模型 GRM(鲁棒但方差大)。
- 在 RL 中引入人类高质量回复作为风格锚点,避免模型收敛到冗长、模板化的“机器腔”。
跨阶段在线蒸馏
- 解决多阶段 RL 的灾难性遗忘:将各阶段(SFT、Reasoning RL、General RL)的最终 checkpoint 作为教师模型。
- 学生模型通过 logits 差距直接计算 advantage,无需大 group size,batch size 可开到 1024 提升吞吐。
Agent 环境:10000+ 可验证场景
软件工程环境
- 从真实 GitHub Issue-PR 对出发,基于 RepoLaunch 自动构建可执行环境。
- 自动分析仓库安装与依赖,构建 Docker,生成测试命令,用 LLM 从测试输出生成日志解析函数。
- 覆盖 9 种语言:Python、Java、Go、C、C++、JavaScript、TypeScript、PHP、Ruby;总计超过 10000 个可验证环境。
终端环境
- 两条路径:
- 种子任务合成:从真实 SWE 与终端场景采集种子,LLM 生成任务草稿 → 以 Harbor 格式实例化 Agent → 精炼迭代;Docker 构建精度超 90%。
- 网页语料合成:从代码网页到闭环设计,要求 Coding Agent 合成任务并自我验证,所有检查通过才入库。
搜索任务与上下文管理
- 从早期搜索 Agent 轨迹中收集 200 万+ 高信息量网页,构建 Web 知识图谱(WKG),生成多跳问答,对问题进行跨网页证据汇聚与多步推理。
- 难度过滤分三阶段:删掉不用工具也能答对的题(8 次尝试中至少对 1 次即删)→ 过滤早期 Agent 几步就能搜到的题 → Verification Agent 双向校验,排除答案不唯一或证据不一致样本。
- BrowseComp 表现高度依赖上下文管理。GLM-5 采用分层策略:
- Keep-recent-k:交互历史超过 k 轮时,仅保留最近 5 轮完整内容,旧工具结果折叠;准确率 55.3% → 62.0%。
- 与 Discard-all 结合:总上下文超过 32K 时清空工具调用历史重新开始,同时继续 Keep-recent-k,使模型在预算内执行更多步搜索。
- 最终 BrowseComp 得分 75.9,所有模型中最高(含闭源)。
PPT 生成与 Reward Hacking
报告中给出一个直观的 reward hacking 案例:PPT 生成以 HTML 为中间格式,RL 设置三级奖励——静态属性(定位、间距、颜色)、渲染后真实属性(DOM 实际宽高)、视觉感知(空白检测)。

- 模型的两种“作弊”:用
overflow: hidden隐藏溢出让页面看似 16:9;用flex: 1 1 8%强行占满空间,布局正常但内容稀疏。 - 解决方案:改用渲染器输出的真实属性值评估,不看 HTML 源码写了什么。
- 修正后,符合 16:9 比例的页面由 40% 提升至 92%;人工评估中,GLM-5 对比 GLM-4.5 综合胜率 67.5%。
国产芯片适配
GLM-5 上线即适配国产芯片,覆盖七大平台:华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、天数智芯(MetaX)、燧原。
以华为昇腾 Atlas 系列为例,适配分三层:
- W4A8 混合精度量化:Attention / MLP 用 INT8(W8A8),MoE 专家压到 INT4(W4A8),让 750B 模型装入单台 Atlas 800T A3。
- 融合算子:
- Lightning Indexer:将分数计算、ReLU、TopK 三步融合为一算子。
- Sparse Flash Attention:TopK 检索与稀疏注意力并行。
- MLAPO:13 个碎片化预处理算子融合为一个。
- 推理引擎优化:vLLM-Ascend 与 SGLang 适配;异步调度消除采样回传“气泡”;RadixCache 做前缀共享;Attention DP + MoE EP 混合并行;MTP 加速。
- 效果:单台国产节点的推理性能接近两台国际主流 GPU 集群;长序列部署成本降低 50%。
评测数据:完整跑分速览
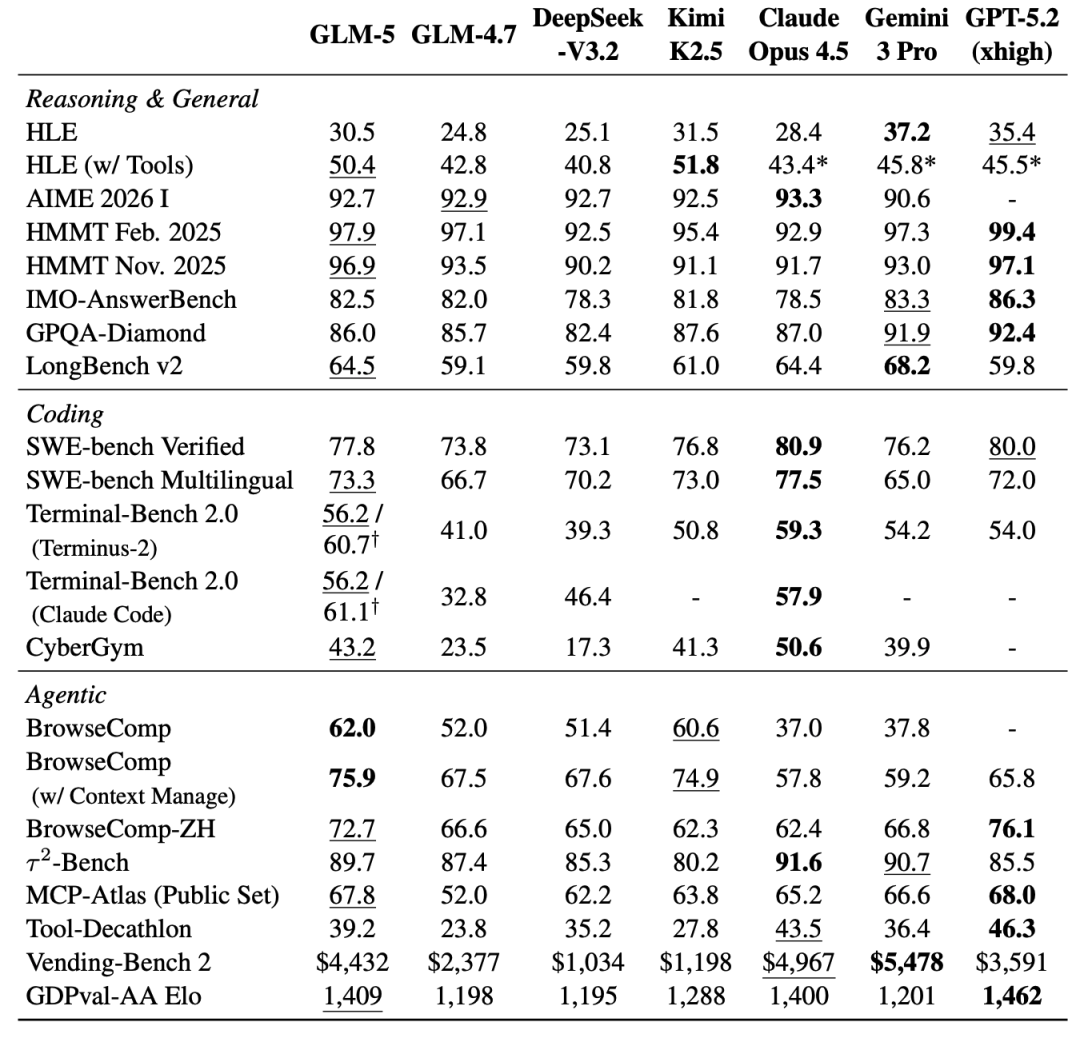
推理
- HLE(含工具):50.4(Claude Opus 4.5:43.4;GPT-5.2 xhigh:45.5;Gemini 3 Pro:44.2)
- HLE(不含工具):30.5(Claude:35.9;GPT-5.2 xhigh:25.1)
- AIME 2026 I:92.7(Claude:93.3;Gemini 3 Pro:92.7)
- HMMT Feb. 2025:97.9(Claude:92.9;Gemini 3 Pro:97.3)
- HMMT Nov. 2025:96.9(Claude:93.5;Gemini 3 Pro:96.9)
- IMO-AnswerBench:82.5(Claude:87.5;GPT-5.2 xhigh:75.5)
- GPQA-Diamond:86.0(Claude:85.8;GPT-5.2 xhigh:84.8)
- LongBench v2:64.5(Claude:59.5;Gemini 3 Pro:68.2)
编程
- SWE-bench Verified:77.8(Claude:80.9;Gemini 3 Pro:72.5;GPT-5.2 xhigh:80.0)
- SWE-bench Multilingual:73.3(Claude:77.5;GPT-5.2 xhigh:72.0)
- Terminal-Bench 2.0:56.2(修正模糊指令后 60.7-61.1;Claude:59.3)
- CyberGym:43.2(Claude:51.3)
Agent
- BrowseComp(含上下文管理):75.9(Claude:64.8;GPT-5.2 xhigh:54.4)
- BrowseComp-ZH:72.7(Claude:64.8;Gemini 3 Pro:42.3)
- τ²-Bench:89.7(Claude:91.6)
- MCP-Atlas:67.8(GPT-5.2 xhigh:68.0)
- Tool-Decathlon:74.0(Claude:75.6)
- Vending-Bench 2:$4432(Claude:$5478)
- GDPval-AA Elo:1409(Claude:1381;GPT-5.2 xhigh:1437)
在 SWE-rebench(持续更新、去污染的 SWE 评测)上,GLM-5 的 42.1% 与 Claude Opus 4.5 的 43.8% 仅差 1.7 个百分点。
CC-Bench-V2:真实工程体验
这是智谱内部的自动化评测基准,不依赖人工标注。
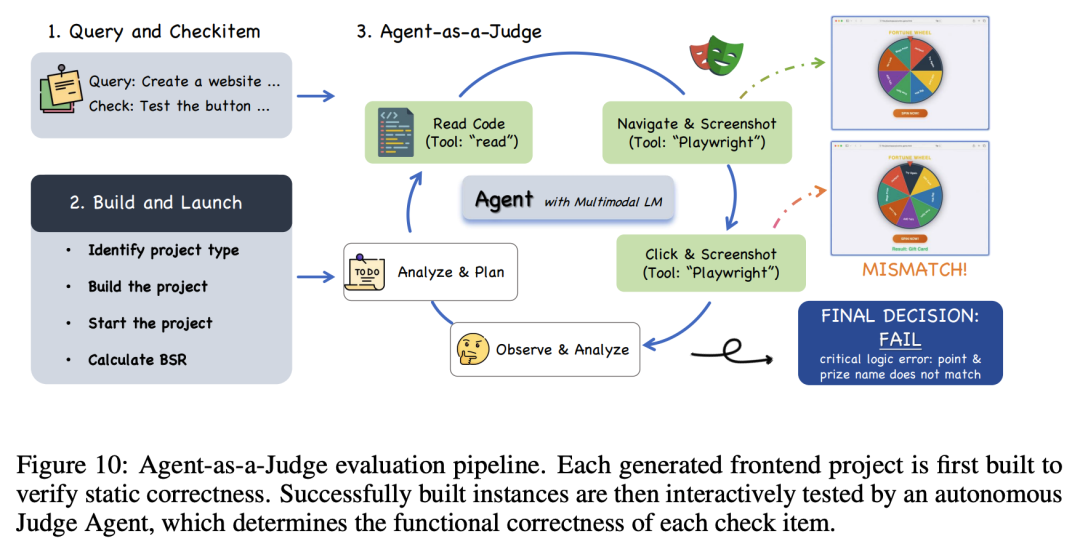
使用 Claude Code + Claude Sonnet 4.5 配合 Playwright 做 Agent-as-a-Judge,让一个 Agent 操作另一个 Agent 生成的前端项目,执行点击、输入、截屏等,逐项验真。
前端
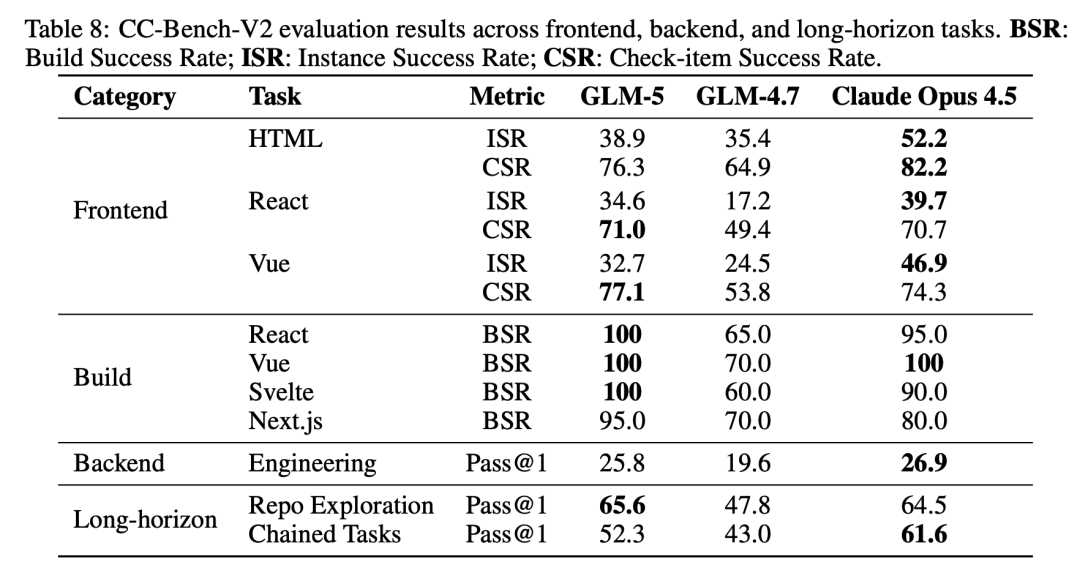
- 指标包含 BSR(构建成功率)、CSR(检查项通过率)、ISR(实例整体通过率)。
- BSR 98%:GLM-5 生成的项目几乎都能跑起来。
- CSR 与 Claude 接近,但 ISR 差距明显:例如 HTML 差 13 个百分点、Vue 差 14 个百分点。
- 结论:单项能力到位,但将所有需求组合为端到端完整任务仍有提升空间。
后端
- 涵盖 85 个任务、6 种语言(Python、Go、C++、Rust、Java、TypeScript),涉及搜索引擎、数据库、Web 框架、AI 推理服务等。
- GLM-5 Pass@1:25.8(Claude Opus 4.5:26.9)。
长程任务
- 大规模代码库探索(在数万文件仓库中定位目标):GLM-5 65.6,高于 Claude 64.5;该任务更考策略性搜索与工具轨迹训练效果。
- 多步链式任务(每步修改改变后续上下文,模拟真实增量开发):GLM-5 52.3(Claude:61.6);差距原因在于错误会累积,前一步次优修改可能破坏后续测试——需在长上下文一致性与长程自纠错上继续突破。

通用能力:五维度全面提升

- 机器翻译(ZMultiTransBench):1016 → 1050
- 多语言对话(LMArena):1441 → 1452
- 指令遵循(IF-Badcase):78.5 → 83.2
- 世界知识(Chinese SimpleQA):72.9 → 75.2
- 工具调用(ToolCall-Badcase):60.8 → 95.8(提升幅度最大)
自研 RL 框架:slime
- 横向扩展:高度可定制的 rollout 接口 + HTTP API 暴露推理服务;不同 Agent 框架可像调用普通推理引擎一样与 slime 交互,训练与推理逻辑完全解耦。
- 纵向扩展:RL 推理目标是端到端延迟,瓶颈在最慢轨迹;采用多节点推理部署(EP64 + DP64 跨 8 节点)、FP8 rollout 降低单 token 延迟、MTP 在小批次解码收益显著、PD 分离(prefill 与 decode 分开调度)保证多轮交互中解码速度稳定。
- 容灾:推理服务定期心跳,不健康节点自动终止并注销,路由自动重试到健康节点。
产品与使用方式
- 模型权重遵循 MIT License 开源,已上线 Hugging Face 与 ModelScope。
- 线上服务纳入 Max 用户套餐,Pro 用户 5 天内支持;GLM Coding Plan 适配 Claude Code、OpenCode 等主流开发工具。
新场景
- Z Code:智谱推出的编程工具,模型自动拆解任务,多 Agent 并发完成代码编写、命令执行、调试、预览与提交;支持手机远程指挥桌面端 Agent;Z Code 自身亦由 GLM 参与开发。(官网)
- OpenClaw 适配:推出 AutoGLM 版本,支持官网一键配置与飞书机器人集成;据 a16z,OpenClaw 在 OpenRouter 上占 13% token 消耗。(博客)
- 办公文档输出:在 Z.ai 与智谱清言上,GLM-5 可直接生成 .docx、.pdf、.xlsx(如 PRD、教案、试卷、财报等)。
- GLM in Excel:原生适配 Excel 的 AI 插件,侧边栏自然语言处理表格数据;Beta 阶段仅对 Max 用户开放。
Pony Alpha:低调上线引发猜测
GLM-5 最早以匿名身份“Pony Alpha”在 OpenRouter 上线,未公开品牌信息,仅靠“模型体感”出圈。上线数日即引发开发者讨论,因其在复杂代码、Agent 任务链路、角色扮演上的表现抢眼,出现多种猜测:
- 25% 用户认为是 Anthropic 的 Claude Sonnet 5。
- 20% 猜是 Grok 新版本。
- 10% 认为是 DeepSeek V4。
- 最终确认:GLM-5。
相关链接
- 技术报告全文:arXiv
- GitHub:zai-org/GLM-5
- Hugging Face:zai-org/GLM-5
- ModelScope:ZhipuAI/GLM-5
- Z Code:zcode.z.ai
- Blog:z.ai/blog/glm-5
- a16z:Charts of the Week