作为一个长期深度使用Claude Code的开发者,我一直在思考:为什么有些人能用Claude Code做出质量很高的产品,而有些人却总是陷入反复修改的循环?
直到最近看到Boris Cherny(Claude Code的创建者)他发过一条推文,分享了13条使用技巧,我才意识到——问题不在工具本身,而在于使用方法论。
Boris在过去47天里有46天使用Claude Code,累计消耗3.25亿tokens,提交259个PR。

他不是在讲理论,而是在分享一个真实在用、高频在用的产品创建者的实践经验。这篇内容值得被认真对待。
一、并行执行架构:从单线程到多窗口工作流
Boris的第一个实践是在终端里同时运行5个Claude Code实例,通过系统通知识别哪个需要输入。
这不是简单的"开多个窗口",而是一个系统化的并行工作流:
- 标签页编号1-5,对应不同的任务
- 依赖系统通知而非频繁切窗口
- 避免上下文频繁切换导致的认知成本
这个思路的核心是:当Claude在等待某个命令执行时,你可以在另一个窗口启动新任务,而不是阻塞式地等待。
二、本地+网页双线作战:突破单一界面的限制
除了本地5个Claude实例,Boris还在claude.ai/code上同时运行5-10个。
两端通过以下方式协作:
- 用
&符号进行本地和网页会话的交接 - 用
--teleport在两端切换 - 外出时用手机浏览器控制网页端,不中断任务进度
这扩展了可用的并行资源容量到10-15个并发任务窗口。
三、统一使用Opus 4.5+思考模式:成本vs效率的权衡
Boris的立场是明确的:所有工作都用Opus 4.5并开启思考模式。
理由不是"Opus最强",而是具体的效率分析:
- 需要的引导次数更少:Opus理解复杂需求的能力更强,减少了反复纠正的轮次
- 工具使用能力更强:在复杂工作流中,工具调用的准确率直接影响任务完成时间
- 总耗时通常更短:虽然单次运行慢,但整体的轮次更少,最终时间反而更快
这是一个成本优化问题而非单纯的成本问题。
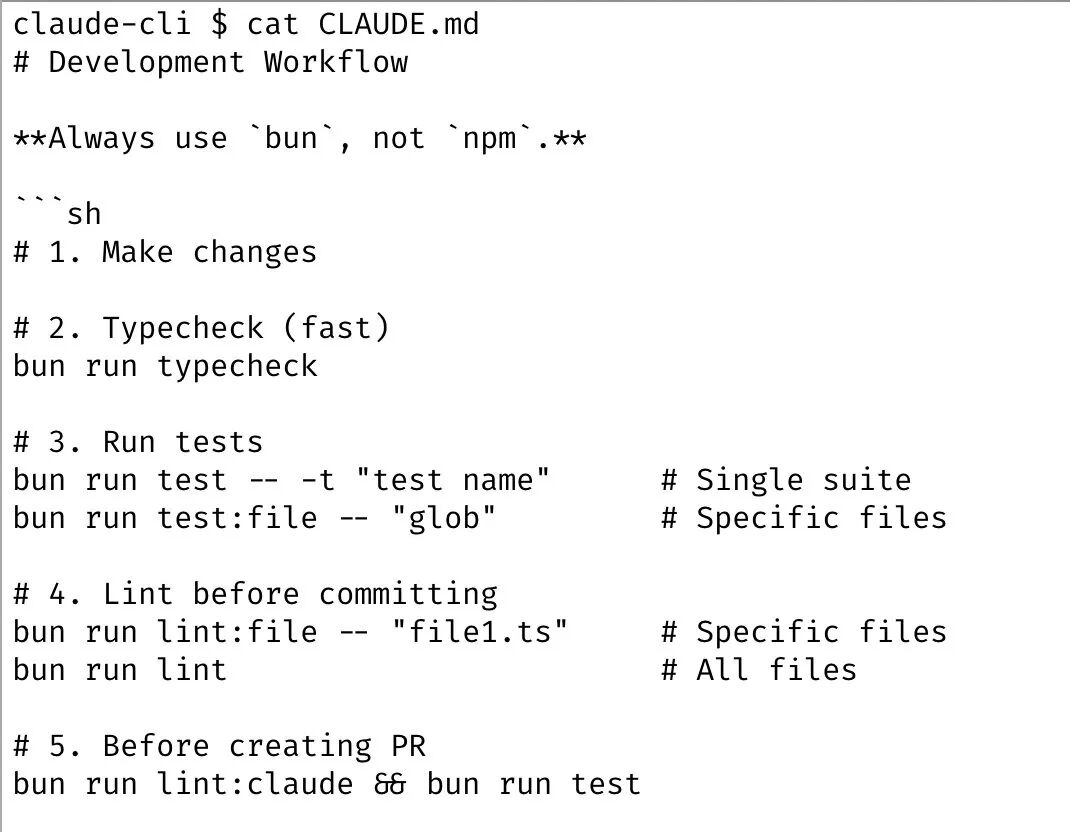
四、CLAUDE.md:团队级的规则积累系统
Boris团队的每个成员共享同一个CLAUDE.md文件,这是一个关键的实践创新:
- 错误驱动更新:每当Claude犯错,就在CLAUDE.md里记录应该如何处理
- 形成正反馈循环:Claude犯错 → 记录规则 → Claude学习 → 犯更少的错
- 版本管理:这个文件check进git,团队每周贡献多次,形成持续演进
CLAUDE.md不是一次性文档,而是一个动态的"工作手册"。
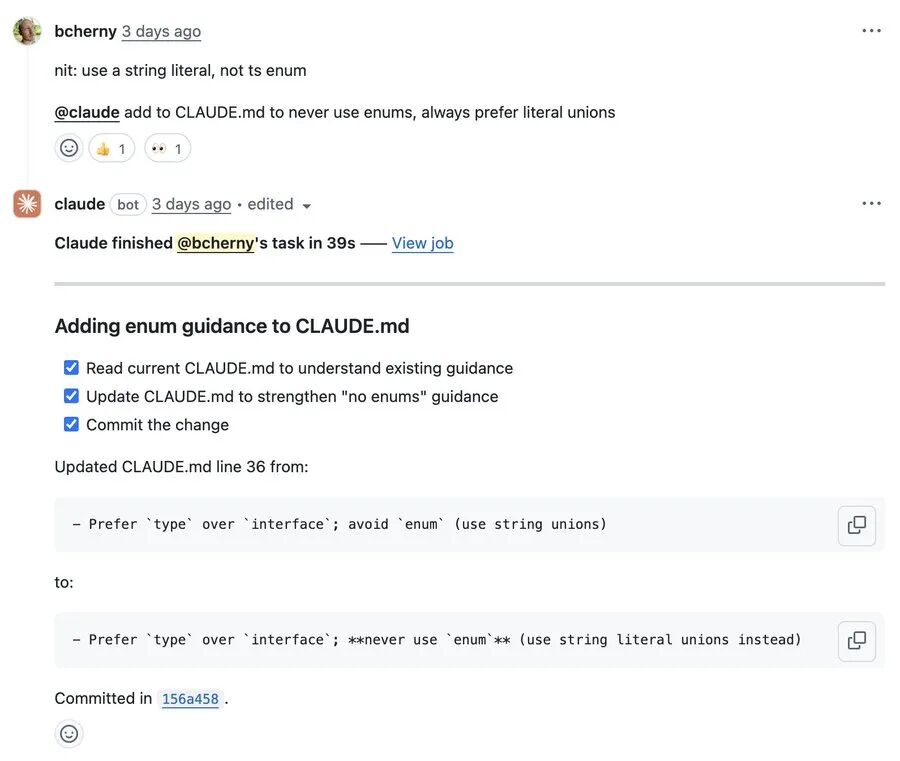
五、Code Review自动化:通过GitHub Action自动更新规则
在代码审查阶段,Boris的流程是:
- 同事提交PR,@claude进行审查
- 审查发现规则缺陷,在@claude的备注中说明
- 触发Claude Code的GitHub Action,自动将规则添加到CLAUDE.md
- 无需手动编辑,规则自动应用到后续任务
设置命令:/install-github-action
六、Plan模式优先:从规划到执行的两阶段流程
Boris的大多数会话从Plan模式开始,具体流程是:
- 按
Shift+Tab两次进入Plan模式 - 在这个阶段与Claude往复讨论,确保计划准确无误
- 一旦计划确定,切换到自动接受编辑模式
- Claude通常能一次完成原定工作
这个方法的核心洞察是:一个好的计划真的很重要。

直接让Claude开干,经常会做到一半才发现方向错了,浪费大量token和时间。
七、斜杠命令:编码化高频工作流
Boris对每天重复做很多次的"内循环"工作都定义斜杠命令,放在.claude/commands/目录下。
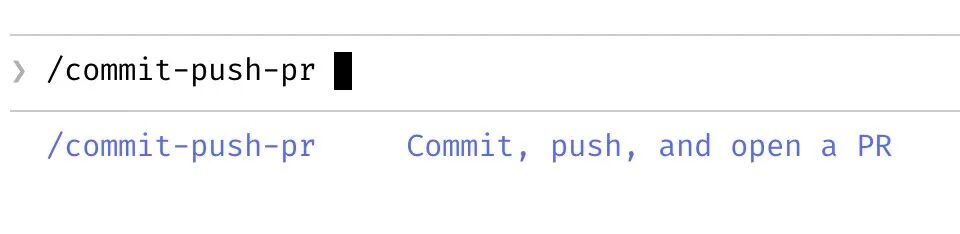
这不仅仅是节省打字:
- Claude能调用这些命令:Claude写代码时可以自行调用
/review来检查自己的工作 - 形成自动化流程:复杂工作流被编码为单条命令,降低每次的认知成本
- 团队统一规范:团队成员都使用相同的命令集,提高协作效率
八、子代理的正确用法:流程自动化,而非角色分工
Boris使用子代理来自动化常见流程,例如:
code-simplifier:工作完成后自动简化代码verify-app:运行端到端测试的详细指令
但他明确指出一个陷阱:不要创建一堆"专家子代理"(Python专家、前端专家)。

这样做会:
- 将上下文分割开,主Claude无法进行整体推理
- 导致信息孤岛,子代理之间无法有效协作
子代理的正确定位是流程自动化工具,而非角色分工。
九、PostToolUse钩子:关键检查点的自动验证
Boris的团队用PostToolUse钩子来自动格式化Claude的代码。

核心思路是:
- Claude通常开箱就能生成格式良好的代码(80-90%)
- 钩子处理最后的10%,避免后续CI中的格式错误
- 这比限制Claude的每一步动作更高效
这个思路可以推广:在关键检查点用钩子做验证,而不是在前期限制每一步动作。
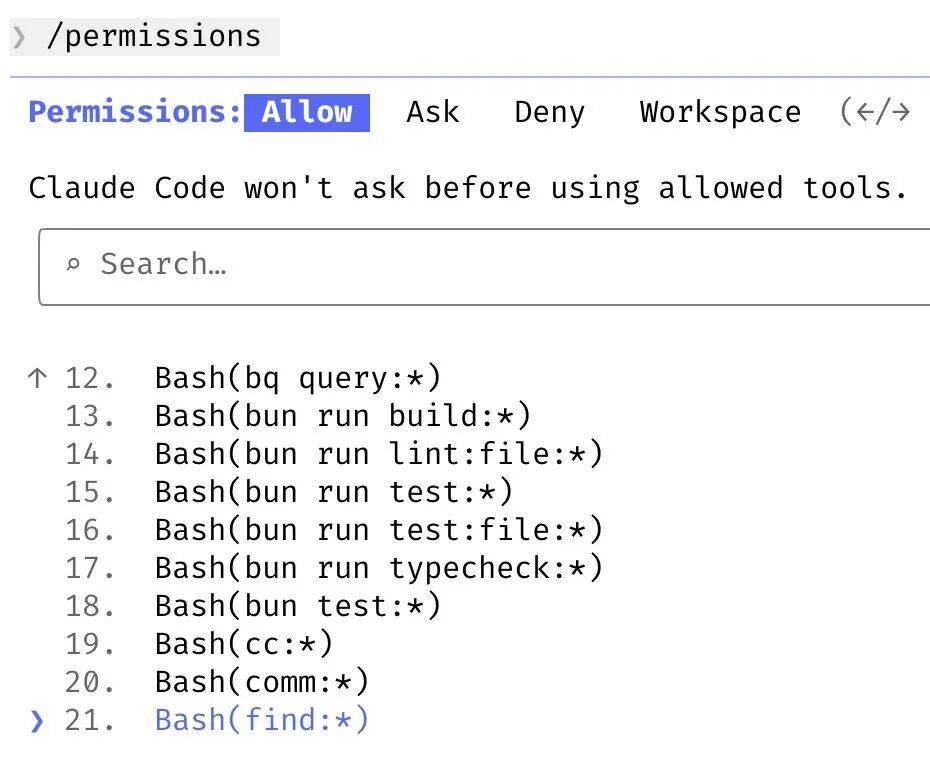
十、权限管理:预授权 vs 跳过权限
Boris不使用--dangerously-skip-permissions,而是采用更细化的权限管理:
- 用
/permissions预先允许已知安全的bash命令 - 大部分权限配置check进
.claude/settings.json并与团队共享 - 形成一个"白名单"机制,既保证安全又不频繁手动确认
这是一个安全性和自动化的平衡方案。
十一、Claude作为通用Agent:突破"代码生成工具"的定位
Boris让Claude Code操作各种工具,而不仅仅是写代码:
- 通过MCP服务器搜索和发送Slack消息
- 运行BigQuery查询回答分析问题
- 从Sentry抓取错误日志进行故障诊断
这反映了Claude Code的真实定位:不是"写代码的工具",而是"可以用代码解决问题的通用Agent"。
十二、长任务处理:三层验证策略
对于非常长的任务,Boris使用三种方式组合:
- 后台代理验证:任务完成后,用子代理进行独立验证
- Agent Stop钩子:设置钩子在关键点进行验证
- ralph-wiggum插件:让Claude在完成后自动循环,直到真正达到目标
ralph-wiggum插件的名字来自《辛普森一家》的角色,核心机制是让Claude自动循环直到任务真正完成。
插件地址:https://github.com/anthropics/claude-plugins-official/tree/main/plugins/ralph-wiggum
十三、验证机制:从70分到95分的关键差异
这是Boris强调的最重要建议:给Claude一种验证工作的方式。
他的具体做法是:
- 用Chrome扩展测试每一个代码改动
- Claude打开浏览器,自动测试UI
- 发现问题 → 修复 → 再测试 → 迭代直到正常工作
验证的形式因领域而异:
- 后端任务:运行bash命令验证,查看日志输出
- 测试驱动:运行测试套件,检查覆盖率和失败情况
- 前端任务:在浏览器或手机模拟器中进行UI测试
关键结论:如果Claude能自己测试、自己发现问题、自己修复,最终输出质量会提升2-3倍。
三个核心认知
1. 基础功能用到极致比黑魔法更有效
Boris的配置看起来很朴素,没有什么神秘的hack。但他把Plan模式、CLAUDE.md、子代理、钩子这些基础功能用到了极限。这给了我一个重要启发:不要期待某个高级技巧能解决问题,正确的使用方法论更重要。
2. 并行思维的规模超出常规想象
本地5个 + 网页端5-10个,总共10-15个并发窗口。这个规模远超我之前在Cursor里开5个终端的做法。这反映了一个关键认知:充分利用Claude Code的并行能力,能显著提升整体产出。
3. 验证闭环是最大的质量杠杆
第13条建议是最有价值的。很多人让Claude写完代码就完事了,但如果Claude能自己测试、自己发现问题、自己修复,质量会好很多。这不是技术问题,而是反馈循环的设计问题。
结语
读完Boris的这13条建议,我最大的收获不是某个具体的技巧,而是一个更深层的认知:Claude Code的上限不在工具本身,而在你如何设计与它的交互流程。
Boris自己强调过一句话:"Claude Code团队的每个人使用方式都非常不同。没有一种'正确'的使用方式。"这说明这13条不是教条,而是参考。但至少它清晰地表明了:一个深度理解产品的创建者,是怎样在真实场景中使用它的。
从我个人的使用经历来看,最有启发的是验证机制和CLAUDE.md的迭代思路。前者能显著提升输出质量,后者能让Claude逐渐适应你的工作风格。这两个点如果用好,已经足以让你的Claude Code体验上一个台阶。
相关资源
Boris的原文推文:https://x.com/bcherny/status/2007179832300581177