继发布Z-Image(造相)广受好评后,阿里又上好货了。
就在刚刚发布 Qwen3-TTS,版本号 2025-11-27,这次更新解决了语音合成的几个核心问题。
音色大幅扩展
49 种高品质音色,覆盖不同性别、年龄和角色设定。具体包括撒娇搞怪的茉兔、青梅竹马小野杏、女汉子十三、严厉的墨讲师、智慧老者沧明子、萝莉萌妹萌小姬等角色音色。
语言和方言能力提升
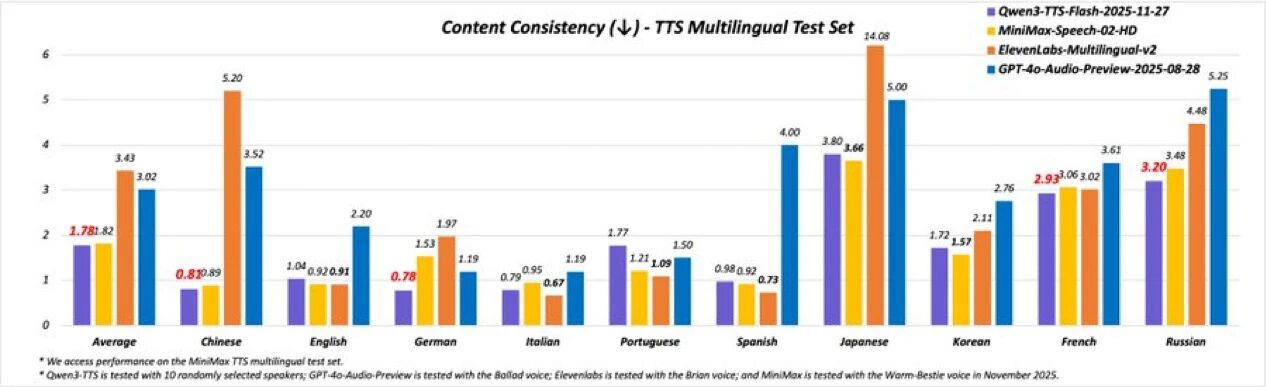
支持 10 种主流语言:中文、英文、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、法语、俄语。在 MiniMax TTS multilingual test set 上,平均词错误率(WER)优于 MiniMax、ElevenLabs 及 GPT-4o-Audio-Preview。
方言支持包括普通话、闽南语、吴语、粤语、四川话、北京话、南京话、天津话和陕西话,能还原地方口音特色。有用户指出,闽南话使用者 5000 万,吴语 8000 万,这些群体此前缺乏高质量语音合成服务。
韵律和语速优化
相比上一版本,自适应调节语速和韵律的能力大幅提高,拟人化程度接近真人。
API 调用简单
通过 DashScope SDK 即可使用,支持多种音色和语言参数。代码示例显示,只需几行代码就能将文本转换为音频文件并下载保存
# 请安装 DashScope SDK 的最新版本
import os
import requests
import dashscope
text = "那我来给大家推荐一款T恤,这款呢真的是超级好看,这个颜色呢很显气质,而且呢也是搭配的绝佳单品,大家可以闭眼入,真的是非常好看,对身材的包容性也很好,不管啥身材的宝宝呢,穿上去都是很好看的。推荐宝宝们下单哦。"
# SpeechSynthesizer接口使用方法:dashscope.audio.qwen_tts.SpeechSynthesizer.call(...)
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash-2025-11-27",
api_key=os.getenv("DASHSCOPE_API_KEY"),
text=text,
voice="Cherry",
language_type="Chinese", # 建议与文本语种一致,以获得正确的发音和自然的语调。
stream=False
)
audio_url = response.output.audio.url
save_path = "downloaded_audio.wav" # 自定义保存路径
try:
response = requests.get(audio_url)
response.raise_for_status() # 检查请求是否成功
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"音频文件已保存至:{save_path}")
except Exception as e:
print(f"下载失败:{str(e)}")目前可以通过 Qwen Chat 的"朗读"功能体验,也有实时 API 和离线 API 可用。
HuggingFace 和 ModelScope 都有 Demo 可以试玩。

体验方式:
- Qwen Chat 朗读功能:http://chat.qwen.ai
- 实时 API 文档:https://modelstudio.console.alibabacloud.com/?tab=doc#/doc/?type=model&url=2840914_2&modelId=qwen3-tts-flash-realtime-2025-11-27
- 离线 API 文档:https://modelstudio.console.alibabacloud.com/?tab=doc#/doc/?type=model&url=2840914_2&modelId=qwen3-tts-flash-2025-11-27
- HuggingFace Demo:http://hf.co/spaces/Qwen/Qwen3-TTS-Demo
- ModelScope Demo:http://modelscope.cn/studios/Qwen/Qwen3-TTS-Demo
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。
未经允许不得转载:刚刚!阿里 Qwen3-TTS 发布,语音合成能力大幅提升!