美团正式发布 LongCat-Flash 系列模型,现已开源 LongCat-Flash-Chat 和 LongCat-Flash-Thinking 两大版本,获得了开发者的关注。
今天 LongCat-Flash 系列再升级,正式发布全新家族成员——LongCat-Flash-Omni。
LongCat-Flash-Omni 以 LongCat-Flash 系列的高效架构设计为基础( Shortcut-Connected MoE,含零计算专家),同时创新性集成了高效多模态感知模块与语音重建模块。即便在总参数 5600 亿(激活参数 270 亿)的庞大参数规模下,仍实现了低延迟的实时音视频交互能力,为开发者的多模态应用场景提供了更高效的技术选择。
综合评估结果表明,LongCat-Flash-Omni 在全模态基准测试中达到开源最先进水平(SOTA),同时在文本、图像、视频理解及语音感知与生成等关键单模态任务中,均展现出极强的竞争力。LongCat-Flash-Omni 是业界首个实现 “全模态覆盖、端到端架构、大参数量高效推理” 于一体的开源大语言模型,首次在开源范畴内实现了全模态能力对闭源模型的对标,并凭借创新的架构设计与工程优化,让大参数模型在多模态任务中也能实现毫秒级响应,解决了行业内推理延迟的痛点。

▶ 模型已同步开源:
-
Hugging Face:
https://huggingface.co/meituan-longcat/LongCat-Flash-Omni
-
Github:
https://github.com/meituan-longcat/LongCat-Flash-Omni
极致性能的一体化全模态架构
LongCat-Flash-Omni 是一款拥有极致性能的开源全模态模型,在一体化框架中整合了离线多模态理解与实时音视频交互能力。该模型采用完全端到端的设计,以视觉与音频编码器作为多模态感知器,由 LLM 直接处理输入并生成文本与语音token,再通过轻量级音频解码器重建为自然语音波形,实现低延迟的实时交互。所有模块均基于高效流式推理设计,视觉编码器、音频编解码器均为轻量级组件,参数量均约为6亿,延续了 LongCat-Flash 系列的创新型高效架构设计,实现了性能与推理效率间的最优平衡。

大规模、低延迟的音视频交互能力
LongCat-Flash-Omni 突破 “大参数规模与低延迟交互难以兼顾” 的瓶颈,在大规模架构基础上实现高效实时音视频交互。该模型总参数达 5600 亿(激活参数 270 亿),却依托 LongCat-Flash 系列创新的 ScMoE 架构(含零计算专家)作为 LLM 骨干,结合高效多模态编解码器和“分块式音视频特征交织机制”,最终实现低延迟、高质量的音视频处理与流式语音生成。模型支持 128K tokens 上下文窗口及超 8 分钟音视频交互,在多模态长时记忆、多轮对话、时序推理等能力上具备显著优势。
渐进式早期多模融合训练策略
全模态模型训练的核心挑战之一是 “不同模态的数据分布存在显著异质性”,LongCat-Flash-Omni 采用渐进式早期多模融合训练策略,在平衡数据策略与早期融合训练范式下,逐步融入文本、音频、视频等模态,确保全模态性能强劲且无任何单模态性能退化。
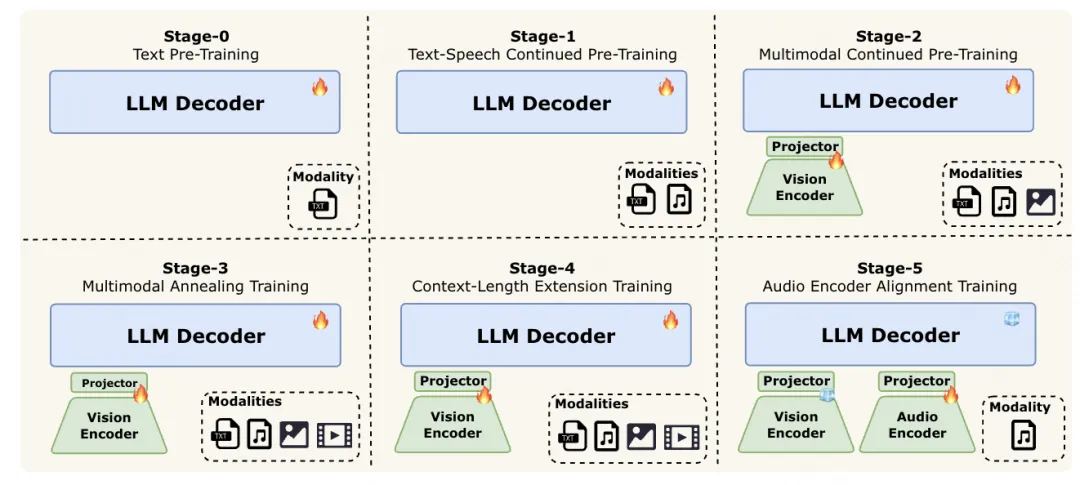
预训练阶段
-
阶段 0:大规模文本预训练,利用成熟稳定的大语言模型为后续多模态学习奠定坚实基础;
-
阶段 1:引入与文本结构更接近的语音数据,实现声学表征与语言模型特征空间的对齐,有效整合副语言信息;
-
阶段 2:在 文本 - 语音对齐基础上,融入大规模图像 - 描述对与视觉 - 语言交织语料,实现视觉 - 语言对齐,丰富模型视觉知识;
-
阶段 3:引入最复杂的视频数据,实现时空推理,同时整合更高质量、更多样化的图像数据集以增强视觉理解;
-
阶段 4:将模型上下文窗口从 8K 扩展至 128K tokens,进一步支持长上下文推理与多轮交互;
-
阶段 5:为缓解离散语音 tokens 的信息丢失,进行音频编码器对齐训练,使模型能直接处理连续音频特征,提升下游语音任务的保真度与稳健性。
经过全面的综合评估显示:LongCat-Flash-Omni 不仅在综合性的全模态基准测试(如Omni-Bench, WorldSense)上达到了开源最先进水平(SOTA),其在文本、图像、音频、视频等各项模态的能力均位居开源模型前列,真正实现了“全模态不降智”。
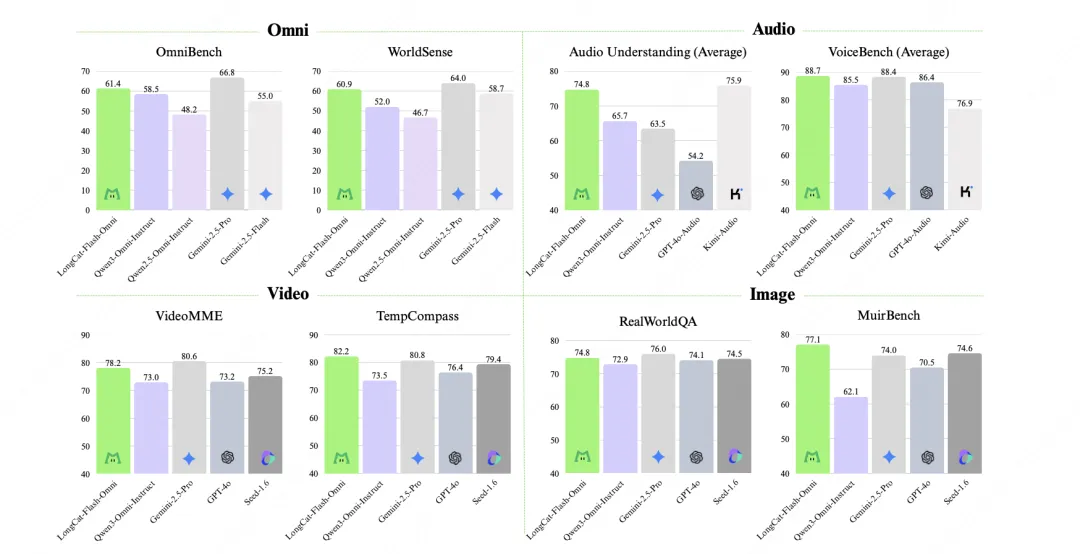
LongCat-Flash-Omni 的基准测试性能
-
文本:LongCat-Flash-Omni 延续了该系列卓越的文本基础能力,且在多领域均呈现领先性能。相较于 LongCat-Flash 系列早期版本,该模型不仅未出现文本能力的衰减,反而在部分领域实现了性能提升。这一结果不仅印证了我们训练策略的有效性,更凸显出全模态模型训练中不同模态间的潜在协同价值。
-
图像理解:LongCat-Flash-Omni 的性能(RealWorldQA 74.8分)与闭源全模态模型 Gemini-2.5-Pro 相当,且优于开源模型 Qwen3-Omni;多图像任务优势尤为显著,核心得益于高质量交织图文、多图像及视频数据集上的训练成果。
-
音频能力:从自动语音识别(ASR)、文本到语音(TTS)、语音续写维度进行评估,Instruct Model 层面表现突出:ASR 在 LibriSpeech、AISHELL-1 等数据集上优于 Gemini-2.5-Pro;语音到文本翻译(S2TT)在 CoVost2 表现强劲;音频理解在 TUT2017、Nonspeech7k 等任务达当前最优;音频到文本对话在 OpenAudioBench、VoiceBench 表现优异,实时音视频交互评分接近闭源模型,类人性指标优于 GPT-4o,实现基础能力到实用交互的高效转化。
-
视频理解:LongCat-Flash-Omni 视频到文本任务性能达当前最优,短视频理解大幅优于现有参评模型,长视频理解比肩 Gemini-2.5-Pro 与 Qwen3-VL,这得益于动态帧采样、分层令牌聚合的视频处理策略,及高效骨干网络对长上下文的支持。
-
跨模态理解:性能优于 Gemini-2.5-Flash(非思考模式),比肩 Gemini-2.5-Pro(非思考模式);尤其在真实世界音视频理解WorldSense 基准测试上,相较其他开源全模态模型展现出显著的性能优势,印证其高效的多模态融合能力,是当前综合能力领先的开源全模态模型。
-
端到端交互:由于目前行业内尚未有成熟的实时多模态交互评估体系,LongCat 团队构建了一套专属的端到端评测方案,该方案由定量用户评分(250 名用户评分)与定性专家分析(10 名专家,200 个对话样本)组成。定量结果显示:围绕端到端交互的自然度与流畅度,LongCat-Flash-Omni 在开源模型中展现出显著优势 —— 其评分比当前最优开源模型 Qwen3-Omni 高出 0.56 分;定性结果显示:LongCat-Flash-Omni 在副语言理解、相关性与记忆能力三个维度与顶级模型持平,但是在实时性、类人性与准确性三个维度仍存在差距,也将在未来工作中进一步优化。
实测体验
我试了下官网 demo(https://longcat.ai),上传图片、发语音、直接对话,整个交互流畅到让我忘了它是个开源模型。
语音识别几乎是即时响应,语气自然度接近 GPT-4o,视频理解也能识别画面情境并作出连贯回答。
根据官方测试,Omni 在端到端交互的自然度上,用户评分比 Qwen3-Omni 高 0.56 分(250人参与评测),专家组也给出了“类人性优于 GPT-4o”的评价。当然,它在实时性、语音情感和准确率上还有提升空间,但就目前的开源生态来说,这个成绩已经相当亮眼。
LongCat-Flash-Omni 代表的是“多模态实用化”的一个分水岭。
之前的多模态模型更多停留在研究或展示层面,而这个模型已经具备真正的实时交互能力——而且是开源的。
目前模型已全量开源:
Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-Omni
Github:https://github.com/meituan-longcat/LongCat-Flash-Omni