摘要:Anthropic 最新博客将多 Agent 协调归纳为五种模式,从最简单到最复杂,给出了何时演进到下一级的判断标准。大部分团队的问题不是不知道多 Agent 的好处,而是上来就挑最酷的模式,结果被协调开销拖死了。
用一个 Agent 搞不定复杂任务?上多 Agent 吧。这个判断现在大家基本都认了。但上多 Agent 之后紧跟着一个更具体的问题:这些 Agent 之间怎么配合?
Anthropic 刚发的这篇博客正好补了这个缺口,把多 Agent 协调归纳成五种模式,从最简单到最复杂,还给出了什么时候该从一种演进到另一种的判断标准。
苏米注:读完最大的感受是:大部分团队的问题不是不知道多 Agent 的好处,而是上来就挑了一个听起来最酷的模式,结果被协调开销拖死了。Anthropic 的建议是,从最简单的能跑通的模式开始,看它哪里撑不住了,再往上演进。
模式一:生成 - 验证(Generator-Verifier)
这是最简单的多 Agent 模式,也是部署最广的。
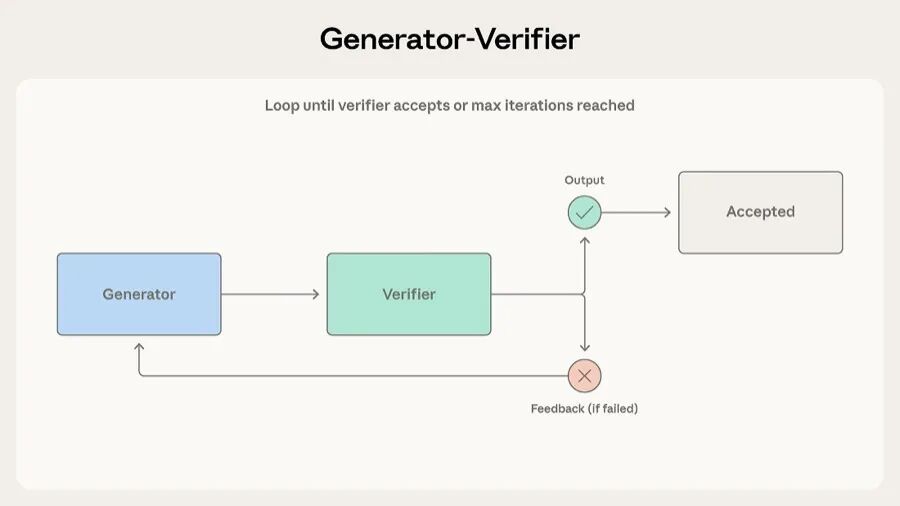
逻辑很简单。一个 Agent 负责生成输出,另一个负责评估。评估通过就结束,不通过就把反馈打回给生成方,重新来一轮。循环下去直到通过或者达到最大迭代次数。
最典型的应用是代码生成:一个 Agent 写代码,另一个写测试、跑测试。客服场景也适用,生成方起草邮件回复,验证方检查是否准确引用了产品文档、是否回应了用户提到的每个问题。
常见踩坑点
踩坑 1:验证标准太模糊
如果你只告诉验证方检查输出是否足够好,它大概率会糊弄人,放行所有东西。验证方的价值完全取决于你能不能把"好"拆成具体的、可检查的标准。
踩坑 2:迭代循环卡死
生成方解决不了验证方提的问题,两边来回震荡不收敛。所以必须设最大迭代次数,加一个兜底策略,比如升级给人处理,或者返回当前最好的版本并标注问题。
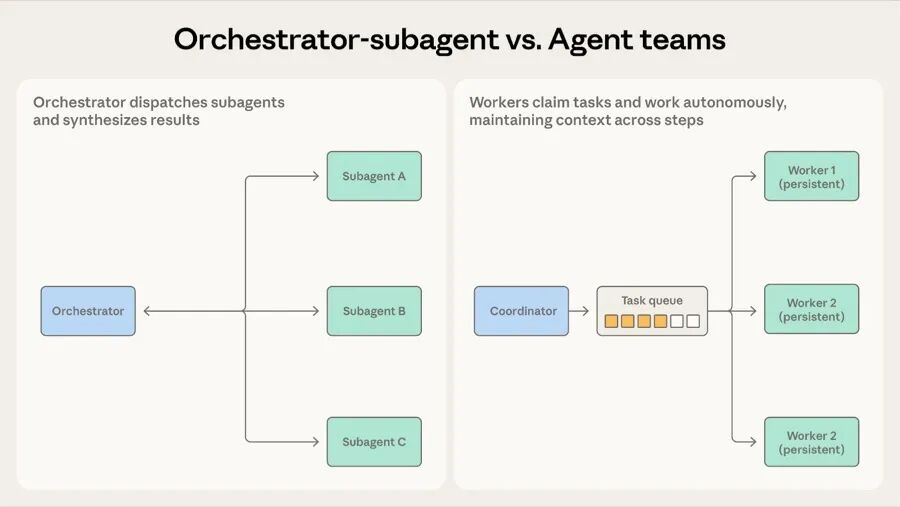
模式二:编排 - 子 Agent(Orchestrator-Subagent)
这是层级式的分工。一个 Agent 当 Team Lead,负责规划任务、分配工作、汇总结果。子 Agent 接到具体任务后执行完就汇报。
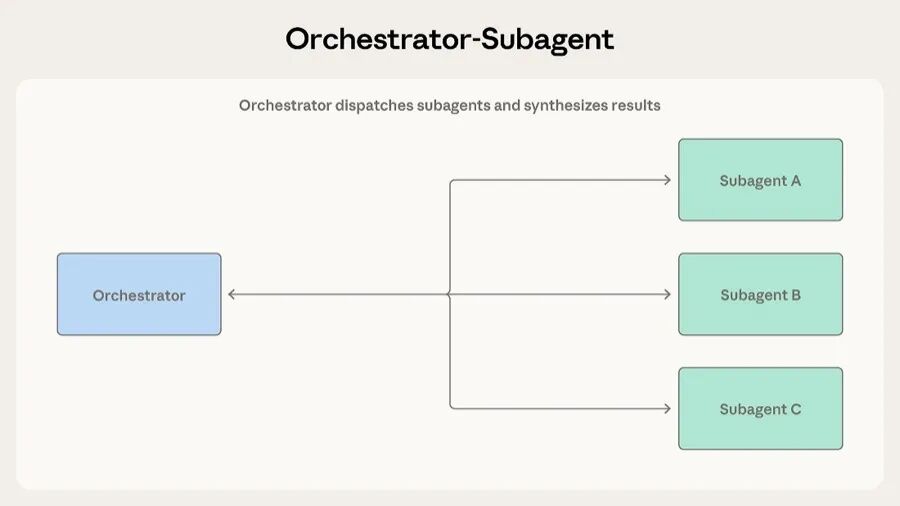
Claude Code 用的就是这个模式。主 Agent 自己写代码、编辑文件、跑命令,需要搜索大型代码库或者调查独立问题时,就在后台派 subagent 去做,自己继续手头的活。
这个模式适合任务拆分清晰、子任务之间依赖少的场景。比如自动化代码审查:一个 PR 进来,需要查安全漏洞、检查测试覆盖率、评估代码风格、验证架构一致性。每个检查维度独立、上下文不同、输出格式明确。
核心问题:信息瓶颈
当子 Agent 发现了对其他子 Agent 有用的信息时,这条信息必须经过编排 Agent 中转。安全子 Agent 发现了一个认证漏洞,这个发现影响架构子 Agent 的分析。编排 Agent 需要识别这种依赖关系并正确路由信息。经过几轮中转之后,关键细节经常被丢失或者在摘要中被省略掉。
苏米注:我在用 Claude Code 的 subagent 时也有类似体感。subagent 搜完代码库回来的结果有时候会把关键上下文压缩掉,主 Agent 拿到的是一个干净但不够完整的摘要。
模式三:Agent 团队(Agent Teams)
编排模式里的子 Agent 是用完即弃的。接到任务,干完活,交结果,走人。但如果任务需要 worker 在多轮中积累经验呢?
Agent 团队模式的区别就在这里:worker 是持久的。
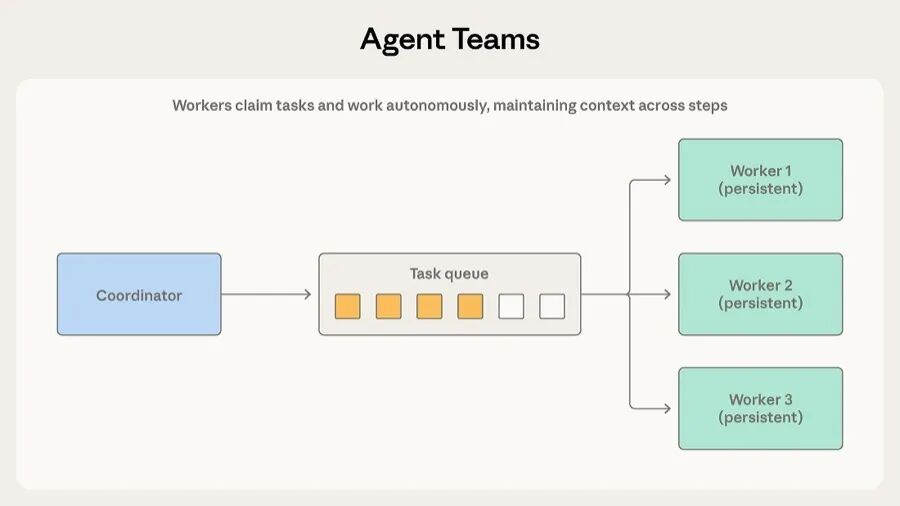
一个协调者启动多个 worker Agent 作为独立进程。领任务,干活,交结果。不重置,不遗忘。每个 worker 在多轮迭代中积累对自己负责领域的熟悉度。
最直观的例子是大规模代码迁移。每个 worker 分管一个服务,在反复处理这个服务的依赖、测试、部署配置的过程中,逐渐摸清它的脾气。一次性 subagent 每次接手都要重新理解服务的配置约定和依赖关系,持久 worker 第一次弄明白之后后续迭代直接复用,省掉重复的上下文加载。
硬前提:独立性
团队模式里的 worker 没有中间人帮忙传话。一个 worker 的改动影响了另一个,谁都不知道,产出可能冲突。常见的应对方式是文件级别的分区或者合并前跑冲突检测,但这增加了协调者的复杂度。
模式四:消息总线(Message Bus)
前面三种模式都有明确的协调者在指挥交通。但如果 Agent 数量继续增加、交互模式变得不可预测呢?
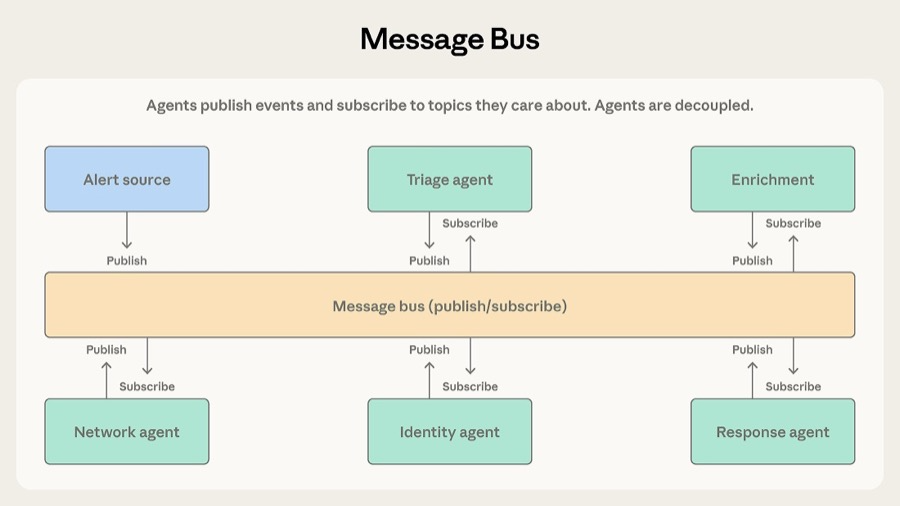
消息总线引入了一个共享通信层。核心操作就两个:发布和订阅。Agent 订阅自己关心的 topic,路由器负责分发。新 Agent 上线不需要改已有的连接,订阅相关 topic 就能开始接收工作。
Anthropic 举的例子是安全运维自动化。告警从多个来源进来,分诊 Agent 分类后路由给对应的调查 Agent,调查结果再流向响应协调 Agent。事件一个阶段接一个阶段地流下去,新出了什么威胁类型就加个新 Agent,各个 Agent 还能独立开发部署。
代价:可追溯性变差
一个告警触发五个 Agent 之间的事件级联,要搞清楚到底发生了什么,调试难度比编排模式那种顺序决策链高了不少。路由器分错类或者丢了事件更麻烦,系统会静默失败,什么都不处理但也不崩溃。
模式五:共享状态(Shared State)
前四种模式里都有一个中心角色在管理信息流。共享状态模式把这个中间人去掉了。
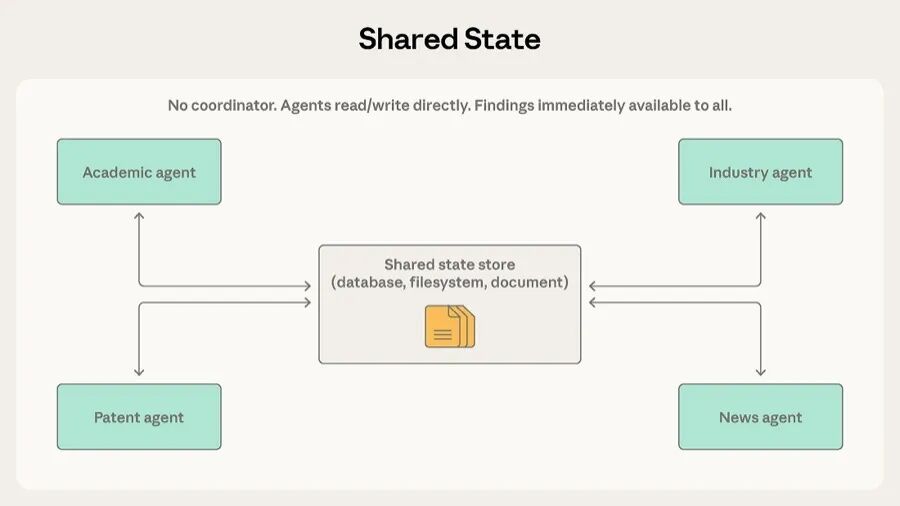
没有中央协调者。Agent 自主运行,读写一个共享的数据库、文件系统或文档。工作一般从往存储里丢一个问题或数据集开始。停下来的条件有几种:时间到了、结果收敛了,或者有个专门的 Agent 判断存储里的东西已经够用了。
研究综合场景是这个模式的主场。多个 Agent 分头调查一个复杂问题的不同方面,学术 Agent 发现了一个关键研究者,这条信息对行业 Agent 调查这个研究者的公司立刻就有用。不用等协调者来路由,发现直接写进存储,其他 Agent 马上就能看到。
代价与挑战
Agent 可能重复工作或者走互相矛盾的方向。更棘手的是反应式循环:Agent A 写了一个发现,Agent B 读到后写了跟进,Agent A 看到跟进后又回应。系统持续烧 token 但不收敛。
五种模式对比总结
| 模式 | 复杂度 | 适用场景 | 主要挑战 |
|---|---|---|---|
| 生成 - 验证 | ⭐ | 代码生成、客服回复 | 验证标准模糊、迭代卡死 |
| 编排 - 子 Agent | ⭐⭐ | 任务拆分清晰、子任务独立 | 信息瓶颈、上下文丢失 |
| Agent 团队 | ⭐⭐⭐ | 需要积累经验的长期任务 | worker 独立性、冲突检测 |
| 消息总线 | ⭐⭐⭐⭐ | 大规模 Agent 协作、事件驱动 | 可追溯性差、静默失败 |
| 共享状态 | ⭐⭐⭐⭐⭐ | 研究综合、复杂问题调查 | 重复工作、反应式循环 |
苏米的实践建议
演进原则:从最简单的能跑通的模式开始,看它哪里撑不住了,再往上演进。不要上来就选最复杂的模式。
对于大多数团队,我建议从生成 - 验证模式开始,这是最简单且部署最广的模式。当你的任务需要拆分成多个独立子任务时,再考虑演进到编排 - 子 Agent模式。
如果你的子 Agent 需要在多轮中积累经验,再考虑Agent 团队模式。只有当 Agent 数量继续增加、交互模式变得不可预测时,才需要考虑消息总线或共享状态模式。
文章来源:Feisky
原文编译自 Anthropic 博客《Multi-agent coordination patterns: Five approaches and when to use them》