,来了,而且还是开源,直接免费开放使用!
腾讯开源旗下混元 3.0 模型(HunyuanImage 3.0),参数量 80B,据官方介绍说是目前效果最好的开源生图模型,整体效果和头部闭源模型相差不大。

原生多模态
据官方介绍中强调原生多模态,这指的是在技术架构上,通过一个模型完成文字、图片、视频与音频等多个模态的输入与输出,而非通过多个模型的组合实现图文理解、图片生成等任务。

这意味着,混元图像3.0不仅拥有生图模型的画画能力,还具备语言模型的思考能力和常识。它就像一个自带“大脑”的画家,可以利用智能去思考图像的布局、构图、笔触,利用世界知识去推理常识性的画面
作为原生多模态开源模型,混元图像3.0需要对模型整体架构进行重构,以支持多任务的训练,并实现多任务效果之间的相互促进。

混元图像3.0以Hunyuan-A13B为基础,基于50亿量级的图文对,视频帧,图文交织数据和6T的语料数据进行了多模态生成、理解和LLM的混合训练,使得模型能够充分融合多任务效果,实现超强的语义理解能力,能够响应复杂的长文本,生成长文本文字,同时具有LLM的世界知识,能够利用世界知识进行推理。
腾讯混元团队透露,混元图像3.0目前的版本仅开放了文生图能力,图生图、图像编辑、多轮交互等版本将于后续发布。
技术特点
-
原生多模态架构:支持文本、图像、视频、音频的统一建模,而非模型拼接。
-
语义与推理能力:可解析千字级复杂语义,具备LLM常识推理能力。
-
图像生成质量:高美学质感,真实高质感画面,支持复杂长文本渲染。
-
训练数据:基于 Hunyuan-A13B,使用 50亿图文对 + 视频帧 + 6T语料,进行多模态与LLM混合训练。
支持生成
-
复杂文本类图片(带小字、长段文字的海报等);
-
漫画/插画/表情包(如四格科普漫画、九宫格表情包);
-
产品广告与高端摄影风格图片;
-
创意艺术风格(插画、手账风格、时尚大片)。
使用体验
网页端直接打开 腾讯混元官网 -> 视觉生成即可进入(同时还支持小程序端,可以直接在微信搜索「腾讯混元」即可)
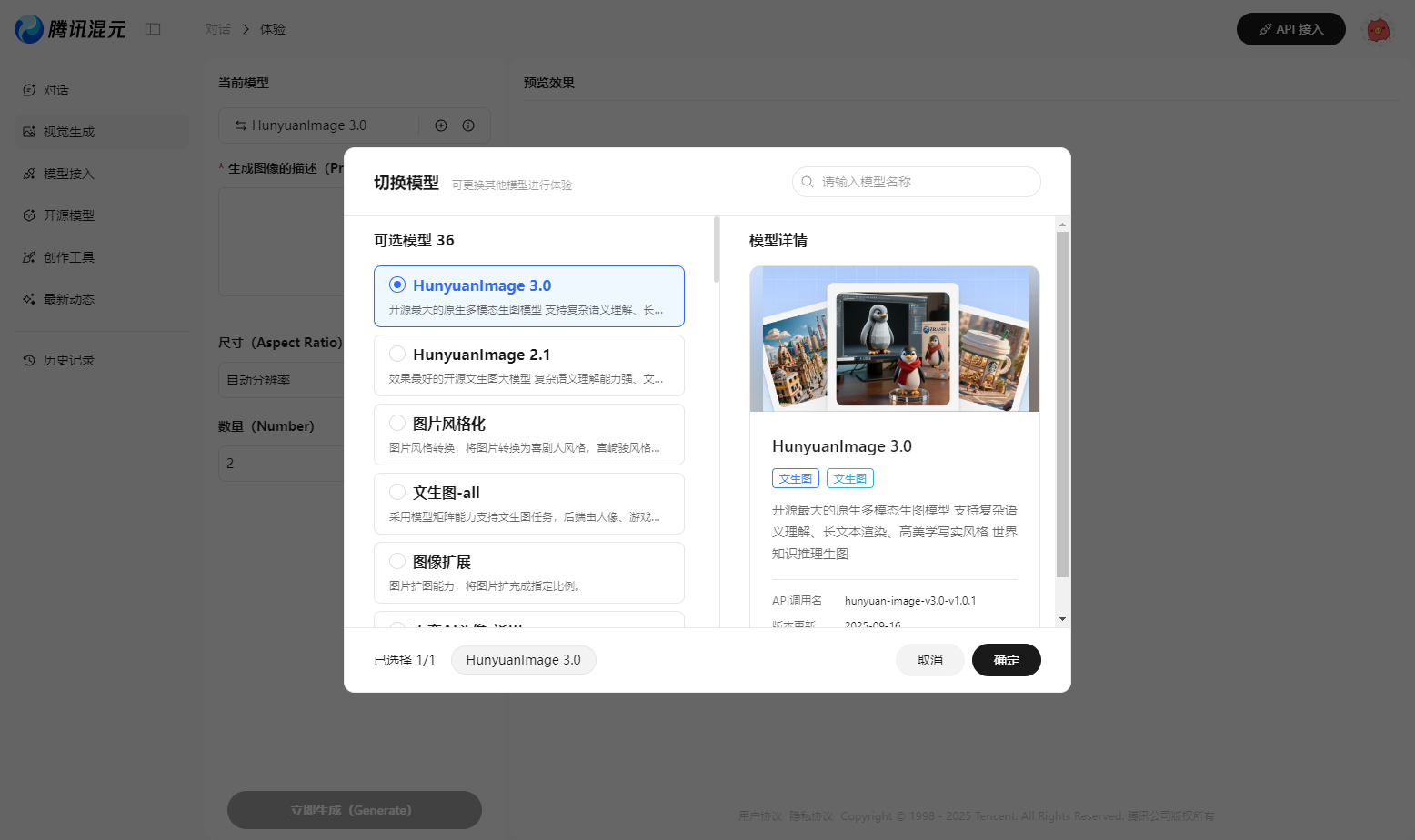
通过最新上线的这个入口进入就默认是「HunyuanImage3.0」模型了
测试一下官方推荐的提示词:你是一个小红书穿搭博主,请根据模特穿搭生成一张封面图片,要求: 1.画面左侧是模特的OOTD全身图 2.右侧是衣服的展示,分别是上衣深棕色夹克、下装黑色百褶短裙、棕色靴子、黑色包包 风格:实物摄影,要求真实,有氛围感,秋季酷感穿搭,看看生成效果:

复杂文字封面/海报提示词:封面设计,标题:AI 编程正在重塑产品经理,副标题:为什么 AI 编程最适合懂技术的产品经理,特写:一个产品经理正在思考AI编程工具,背景:各种AI编程工具如Cursor、Qoder、TRAE、CodeBuddy,要求:背景模糊处理,标题清晰醒目,用海报设计字体

生成九宫格人物手办:生成九宫格的9个系列盲盒手办,要求不同动作的,可爱蓝色的风格的设计感,Q版人物,每一款手办是不一样的造型,展示背景是一个温馨的桌面

加大难度,设计长文海报排版:
设计一张活动海报,分为两个视觉层次:「背景图」和「前景文字排版」。 文字排版风格:现代主义风格,使用清晰、无衬线字体,网格布局,具有层次感。 保持良好留白,文字不要遮挡关键图像区域。 内容如下(如果空白就你来补充,改成中文):活动主题:活动时间:活动地点:邀请嘉宾(用三个照片)

总结
测试完后,我总体感觉是整体能力有了非常大的提升和飞跃,现在只体验了文生图,像图生图,图片编辑还无法体验到,但开源的想象空间非常大!
80B的大模型自己部署 至少要 4 张 80GB的显卡,个人电脑肯定是跑不起来的,所以还是只能在线上体验了!
如果想要自己部署的话看下面:
Github:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
Hugging Face:https://huggingface.co/tencent/HunyuanImage-3.0
同时官方还有提示词手册,大家也可以参考一下
提示词手册: