这款基于单张图像和音频的多模态数字人方案,凭借双人场景生成、超长视频连贯性、情感感知等突破性功能,在影视制作、虚拟主播、教育营销等领域掀起新一轮技术革命。
相较于之前的 Omnihuman 1.0,这次不只是上传音频和图片他帮你生成带有唇形同步的动态视频,1.5 的控制能力大幅提升,你可以定义视频中的人物表演和运动方式。
模型能力
技术升级
OmniHuman-1.5并非简单迭代,而是对真实感与泛化能力的全面重构。
动作自然度飙升: 通过优化多模态运动条件混合训练策略,系统能精准解析音频中的节奏、语调,生成与真人无异的肢体动作。无论是演讲时的手势,还是舞蹈中的旋转,都能做到“音画同步”。
唇形同步精度达毫秒级: 针对动漫角色、虚拟偶像等非真人形象,系统通过风格迁移算法保持动作一致性,同时优化唇形生成逻辑,彻底告别“口型对不上”的尴尬。
情感感知让视频“有灵魂”: 系统可识别音频中的情绪(如愤怒、喜悦、悲伤),并自动调整人物表情。例如,输入一段激昂的演讲音频,视频中的人物会眉头紧锁、眼神锐利,增强感染力。
技术亮点
支持双人音频驱动: 首次实现多人场景交互,可生成对话、辩论甚至舞蹈合作视频,为虚拟直播、影视特效提供新可能。
超长视频生成: 通过帧间连接策略,支持生成超过1分钟的连贯视频,身份一致性误差率低于3%,满足演讲、MV等复杂需求。
应用场景
Omnihuman -1.5的突破性功能,正在重塑多个领域的创作逻辑:
影视制作: 快速生成虚拟演员视频,降低特效成本。例如,历史剧中的已故演员可“复活”参演,动漫角色可实时对口型配音。
虚拟主播: 主播无需露脸,上传一张照片即可生成动态形象,配合实时音频驱动,实现24小时不间断直播。
教育培训: 生成生动的教学视频,教师形象可配合知识点讲解做出手势,提升学生注意力。
广告营销: 品牌可定制虚拟代言人,根据不同产品调整形象风格(如科技感、亲和力),提升转化率。
实测体验
打开即梦官网首页,切换到「数字人」
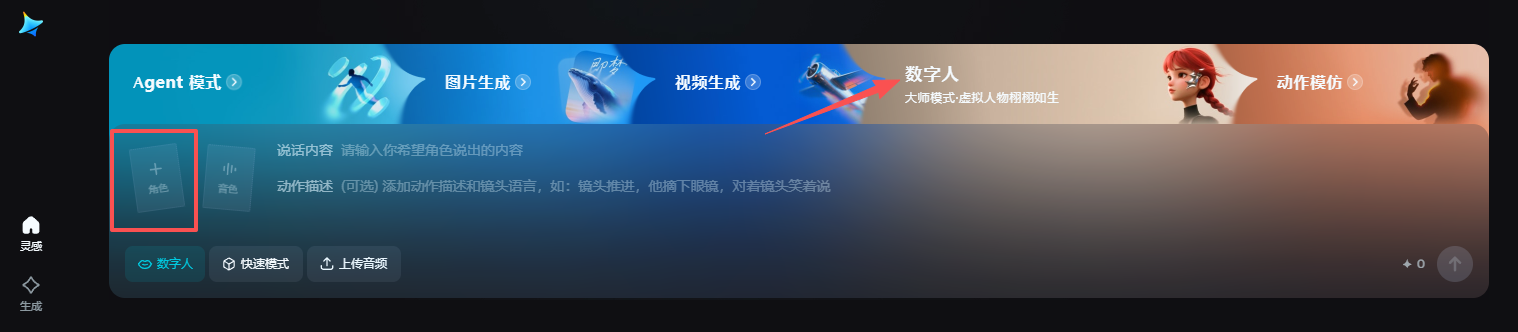
上传人物首帧图片,可以是真人或动漫人物
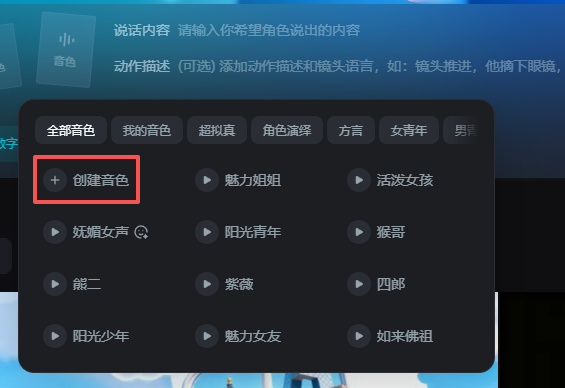
音乐选择支持选择即梦内置的音色库,当然也可以创建自己的音色库,只需要在「我的音色」这里去克隆你想用的音色,只需要 5 秒音频就行。
如果你自己有音频,这时候你需要点击下面的「上传音频」按钮,音频就会回填,这时候角色说这部分就变成你上传的音频了不能打字。
还有一种情况是,你上传的画面里有多个角色,这时候即梦就会自动检测到,你就可以选择是图片中的哪个角色在说话,可以选单个,也可以选全部。
关于动作描述,这里可以用他们推荐的提示词模板,尽量遵循清晰、不矛盾、少否定,多写具体的内容,少用文学化和形容词表达。
这里苏米找了一段播客素材,实现双人对话场景,一起来看看效果:
提示词:角色对着镜头说话,说的同时也会与右边的角色产生眼神互动,说话情绪活力,轻松愉悦的氛围,在聊八卦的感觉,手部也会相应的与说话同步摆动
因为有两个角色,所以需要分两次分别导入音频生成,最后拼出来的效果给大家看看~

技术要求
数字人使用基础参数要求:
| 输入图片格式 | JPG, PNG 等 |
|---|---|
| 图片大小限制 | < 5MB, < 4096×4096 |
| 音频时长 | 推荐 ≤ 15 秒,最大 30 秒 |
| 支持分辨率 | 720P, 1080P |
| 生成模式 | 快速模式, 大师模式 |
| 支持语言 | 不限,中、英、日等常见语种表现更佳 |
提示词指南:
把编写提示词当成讲故事,使用连贯自然的自然语言,尽可能减少孤立词汇的堆砌。
只描述动态的事件即可,图片中已经包含的静态特征(角色穿什么衣服、戴什么首饰等等)无需描述。
提示词需要遵循清晰、不矛盾、少否定的原则。使用具体而非抽象的描述,分步骤引导。
最佳实践模板:
镜头运动 + 说话角色情绪 + 说话状态(说话/哭泣/唱歌/...) + 具体动作 + (可选)背景事件/其他角色的动作
总结
整体的感觉,对于长内容的对话可能在细节上还是会有一些不太贴合,包括动作的细节,但整体感受还是非常自然了,从语气和表情、动作的关联,都能够达到非常好的一致性!
从OmniHuman-1到1.5,字节跳动用技术迭代证明:AI视频生成的终极目标,不是“替代人类”,而是“赋能每个人”。
当一张照片、一段音频就能承载创意,当非专业用户也能轻松制作影视级内容,创作的门槛正被彻底打破。