
虽然我还没来得及深度测试(毕竟提升幅度看起来不大,短期测试很难感受到具体差异),但从官方数据和社区初步反馈来看,有些东西值得聊聊。
一、性能表现
官方放出的这个表格很有意思,我们来仔细看看:
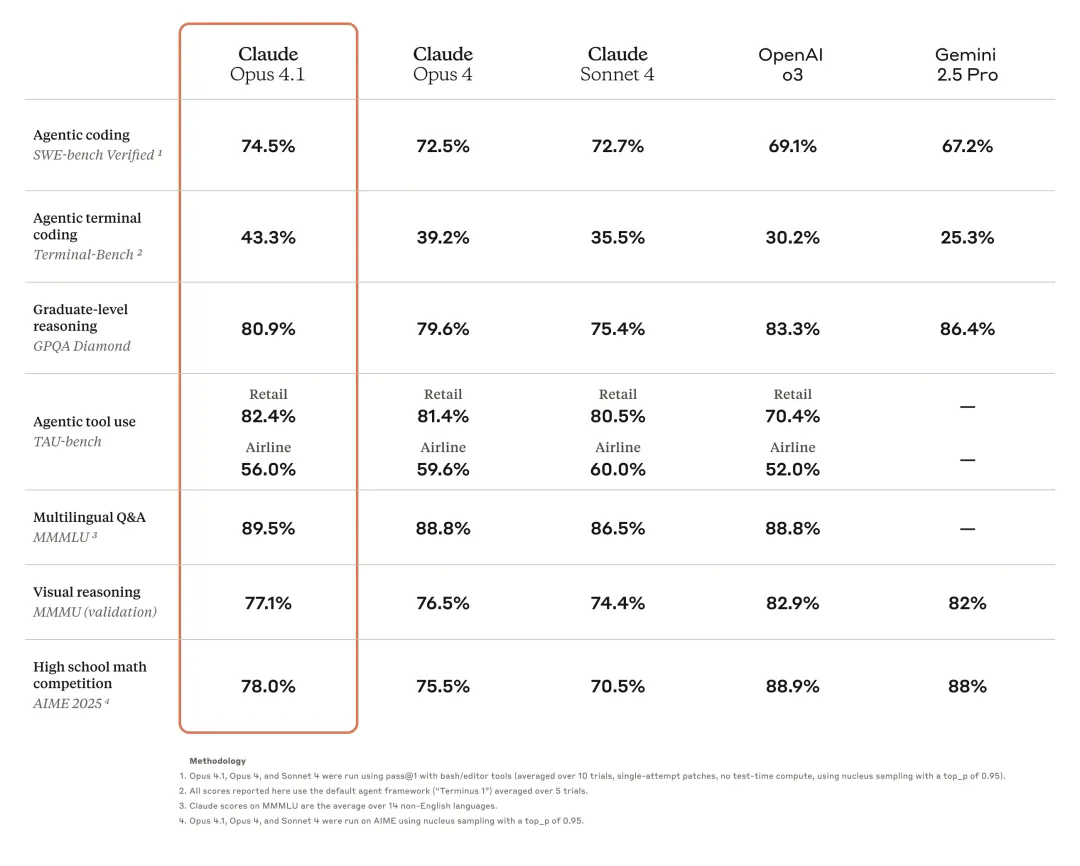
编程能力全面领先
-
SWE-bench Verified: 74.5%,比Opus 4提升2个点,领先o3整整5.4个百分点
-
Terminal-Bench: 43.3%,这个提升就大了,从39.2%到43.3%,说明在终端操作这种更贴近实际开发的场景下进步明显
这两个指标我特别看重,因为它们测的都是真实场景,不是刷分用的toy problem。
特别是SWE-bench,用的是真实的GitHub issue,这74.5%意味着4个bug它能自己解决3个。
但也不是全面碾压
有意思的是,在一些传统的推理任务上,o3和Gemini 2.5 Pro反而更强:
-
GPQA Diamond(研究生级别推理): o3以83.3%领先,Gemini也有86.4%
-
AIME 2025(高中数学竞赛): o3和Gemini都是88%+,Claude只有78%
这说明什么?Claude在押宝实用性,而不是刷榜。 你想想,日常写代码时,你是更需要解高中奥数题的能力,还是更需要准确重构代码、修bug的能力?
TAU-bench的数据很亮眼
在Agentic tool use(智能体工具使用)这个维度:
-
Retail场景:82.4%,只比Opus 4高1个点
-
Airline场景:56.0%,反而比Opus 4低了3.6个点?
官方解释说他们调整了测试方法,增加了thinking步骤,把最大步数从30提到了100。这其实更贴近真实使用场景——让AI多思考几步,把事情做对,比快速给个错误答案强多了。
更有意思的是社区反馈:
-
GitHub团队说多文件重构准确度提升明显
-
Rakuten说它能精确定位大型代码库的bug,不会乱改不相关的代码
-
Windsurf报告说相当于从Sonnet 3.7到Sonnet 4的提升幅度
OpenAI又难产了!
最近有个数据挺有意思:Anthropic的API收入达到31亿美元,首次超过OpenAI。其中14亿来自Cursor和GitHub Copilot这两个AI编程工具。
这说明什么?在AI编程这个赛道,Claude已经是事实上的王者了。
你看现在国内发布新模型,都是说“接近Claude 4的水平”,没人说接近GPT-4o或o3。
Kimi k2发布时说的是用1/10的成本达到Claude 90%的效果,Qwen3 Coder、GLM-4.5也都是拿Claude当benchmark。

OpenAI最近是有点尴尬的。o3虽然在某些推理任务上很强,但价格贵得离谱,而且在实际编程场景下并没有碾压Claude。Sam Altman天天在X上吊胃口,神神秘秘的,但拿得出手的东西越来越少了。
二、快速使用Opus 4.1
API 调用方式
由于价格一致,Anthropic推荐所有用户从 Opus 4 升级到 4.1,调用模型 ID 为:claude-opus-4-1-20250805
Claude Code
-
Claude Code CLI 内直接支持 Opus 4.1(也是需要订阅的用户)
-
无需更改参数,可继续使用原来的对话与 agent 工作流
-
表现升级明显,交互反馈速度及准确性都有显著提升
Cursor使用
Cursor作为Anthropic的大客户,也在第一时间接入了Opus 4.1模型,可以直接使用了。
Claude官网
如果你订阅了Claude,在Claude官网同样可以直接使用Opus 4.1模型了。
最后想说
Claude Opus 4.1 模型本身显然只是个小版本的更新,但Anthropic也借这个模型证明了他们有持续迭代提升模型Coding水平的能力。目前这个水平依旧是领先整个行业的,AI编程的首选。
而且因为Coding和Agent是2025年至今都清晰得不能再清晰的趋势了,他们是真的能为用户为企业解决实实在在的问题,他们也是tokens消耗的大户,所以,不管是OpenAI还是国内的开源大模型们,大家都在这块持续内卷,试图做出更适应Agentic和Coding需求,并且更快速、更便宜的模型。
就目前而言,在不考虑成本的情况下哎,Claude Opus 4.1 是最值得升级使用的编程模型。