很多人第一次用 Codex,还是把它当成「更会写代码的 ChatGPT」:看仓库、改 diff、跑测试、提 PR。
真正有意思的变化,是 Codex 的边界正在往外推:当浏览器、邮件、日程、MCP、桌面 GUI、自动化都接进来之后,Codex 就不再只是 coding agent,而是在变成一个「电脑工作系统」。

先别急着把 Codex 理解成 IDE 插件
很多开发者最早接触 coding agent,通常是从代码任务开始的。比如让它读一个 repo,理解架构,改一段实现,跑一遍测试,再帮你准备 PR。这当然还是 Codex 的主场。但如果只停在这里,就会低估它真正的变化。
因为电脑上的很多工作,本来就已经被代码、命令、网页、API 和文件系统包了一层。只要这些表面能被 Codex 操作,它就自然会从「写代码」扩展到「把电脑上的工作往前推」。

Codex 的重心仍然是代码,但它的工作边界已经不是代码。以前我们问的是「它能不能把这个函数写对」。现在更值得问的是:「它能不能在一个真实工作流里,把上下文、工具、产物和人的判断串起来」。
长线程比单次回答更重要
这篇文章反复强调一个词:durable threads(长线程)。它不是简单的聊天记录保存,而是让一个工作流有自己的长期上下文。比如你可以有一个专门处理发布的线程,一个做文档审查的线程,一个负责外部监控的线程,甚至一个类似 Chief of Staff 的线程。
这些线程的价值,不在于「记得你上次说过什么」这么浅。更重要的是,它能保留一整套工作习惯:哪些来源可信、哪些步骤要先跑、哪些人需要被提醒、哪些检查不能漏。

很多人会低估的一点:AI agent 的生产力,不只来自模型变聪明,也来自上下文不再每次清零。一个短聊天里的 AI 很像临时工,你每次都要重新交代背景、规则、口味和禁忌。长线程更像一个持续工作的项目房间,里面的材料、半成品、决策记录都还在。
语音、转向、排队:人还在回路里
这里有几个看起来小,但实际很关键的控制方式:voice、steering、queuing。
语音输入的意义不是「懒得打字」。它更适合捕捉还没整理好的想法。很多真实任务一开始都不是一个漂亮的 prompt,而是一段含糊的描述:
「我记得 Slack 里好像有人提过这个,名字可能叫 Ben,但细节我忘了。你去找一下。」
对传统工具来说,这句话信息太脏。但对能搜索、整理、追问、汇报的 agent 来说,这反而是很自然的入口。
Steering(转向)是另一种控制:任务跑到一半时,用户可以打断它,立刻纠偏。Queuing(排队)则是不打断当前任务,只把下一步排到队列里。比如「做完后把预览链接发给审核人」,这就是排队。

这套控制模型背后的重点是:人没有被踢出回路。很多 agent 产品容易把「自动化」讲成「你不用管了」。但真实工作不是这样。越是复杂任务,越需要用户在关键节点做判断。好的 agent 不是替你拍板,而是把决策点提前暴露出来,让你用最少的介入改变方向。
工具接入之后,Codex 开始离开 repo
长线程解决的是「上下文能不能留下来」。工具解决的是「它到底能碰到什么」。

Codex 的触达范围大概可以分成几层:
| 层级 | 适合做什么 |
|---|---|
| Browser | 在侧边栏里查看网页、标注、调试页面 |
| Chrome | 处理依赖登录态的真实网页流程 |
| Computer Use | 操作只能通过桌面 GUI 完成的任务 |
| MCP / Connectors | 接入 Slack、Gmail、Calendar 等工作入口 |
| Skills | 把重复工作流封装成可复用能力 |
这个方向很关键。因为很多重要工作并不是从代码仓库开始的。它可能从一条 Slack 消息开始,从一封客户邮件开始,从日历里的会议开始,从一个 Google Docs 评论开始。过去这些入口彼此割裂,最后还是人来做搬运工。现在 Codex 有机会把它们接到同一个工作线程里。
这里也有一个现实提醒:工具越多,风险越大。能读 Slack、能看 Gmail、能操作浏览器,意味着权限边界、确认机制、日志记录都会变得更重要。真正成熟的 agent 工作流,不是「尽可能自动执行」,而是「把可自动化的部分自动化,把需要人负责的部分清楚地停下来」。
自动化和 Goals:从陪聊变成追结果
还有两个概念值得单独拿出来:Automations 和 Goals。

Automations 是让 Codex 按计划启动工作。比如每天生成报告,定期检查 repo,或者让一个活跃线程每隔一段时间醒来,看看 Slack、Gmail、PR 评论有没有新东西需要处理。
Goals 则更像长跑任务:你给它一个明确终点和验证器,让它持续往那个结果推进。
弱目标是:「按这个 Markdown 里的计划实现一下。」
强目标是:「把这个内部工具从 Python 迁到 Rust。目录要建好,功能要对齐,单元测试全部通过才算完成。」
差别就在验证器。没有验证器的目标,只是愿望。测试、benchmark、复现脚本、端到端流程,这些东西把「继续努力」变成了「有没有更接近完成」。
这也是未来 agent 工作流最实用的一条分界线:不是任务越大越适合交给 agent,而是越能被验证的任务,越适合让 agent 长时间推进。
侧边栏和移动端:产物就在对话旁边
Codex app 的 side panel 也在这套叙事里占了很大位置。
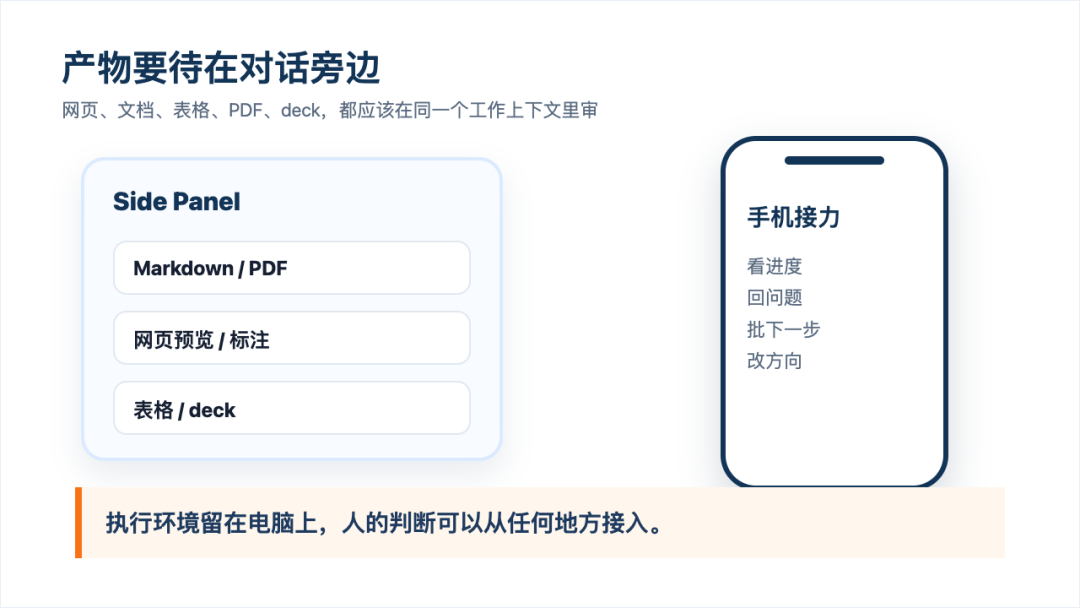
它解决的是另一个老问题:AI 产出一个东西之后,人到底在哪里审。如果输出是代码,可以看 diff。如果输出是网页,就应该直接打开页面。如果输出是文档、表格、PDF、deck,就应该在同一个工作上下文旁边审阅、标注、修改,而不是导出以后切到另一个地方重新沟通。
OpenAI 最近把 Codex 接进 ChatGPT 移动端,也是同一个逻辑:长任务不应该把人绑死在电脑前。你可以在 Mac 上启动一个任务,让本地文件、权限、依赖都留在那台机器上;人离开桌面后,手机继续看进度、回答问题、批准下一步、改变方向。
这不是简单的「远程控制电脑」。更像是让工作线程跟着人走,而执行环境还留在最合适的地方。
真正的变化:上下文、工具、验证器
这篇长文最值得记住的,不是某一个功能,而是一个框架。

Codex 正在从三个方向变重:
- 上下文:长线程、共享记忆、项目文件,让工作不用每次重来。
- 工具:浏览器、Chrome、MCP、连接器、桌面 GUI,让它能碰到真实工作表面。
- 验证器:测试、检查矩阵、端到端流程,让长任务知道什么叫完成。
如果说早期 coding agent 的问题是「能不能写对代码」,下一阶段的问题会变成:「能不能在真实工作流里,带着上下文和验证器,把事情推到完成」。
它不是要把程序员变成甩手掌柜。相反,它把人的角色往上抬了一层:少做搬运、检索、重复执行,多做目标定义、判断和验收。
苏米注:Codex 仍然从代码出发,但它的产品形态已经在往「工作系统」移动。长线程解决上下文,工具连接真实工作表面,Goals 和验证器让任务有终点。真正能用起来的 agent,不是全自动替你决定,而是在正确的节点让你介入。这才是 Codex 这波变化的重点。