摘要:OpenAI 正式发布 GPT-5.5,官方定义为"面向真实工作的全新智能类别"。在编程、知识工作、科学推理等多个维度全面超越 Claude Opus 4.7,重新夺回 SOTA 宝座。
本文整合多方信源,详解 GPT-5.5 的核心能力、跑分数据、实际案例与定价策略。
2026 年 4 月 24 日,OpenAI 正式推出 GPT-5.5,官方定位非常直接:"A new class of intelligence for real work"(一种面向真实工作的全新智能)。
这标志着 AI 从辅助工具向自主工作伙伴的根本性转变。
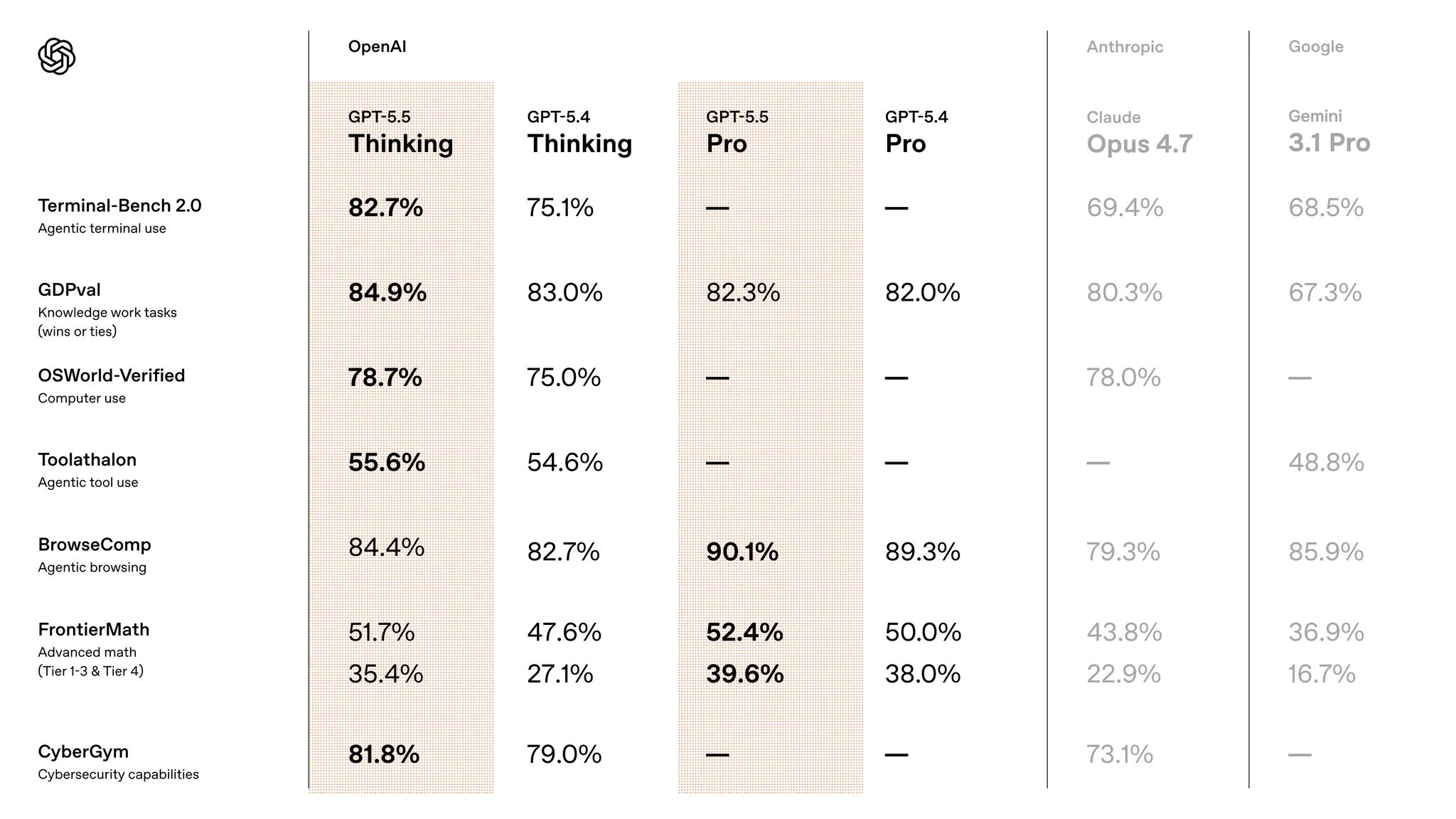
核心跑分数据:全方位领跑
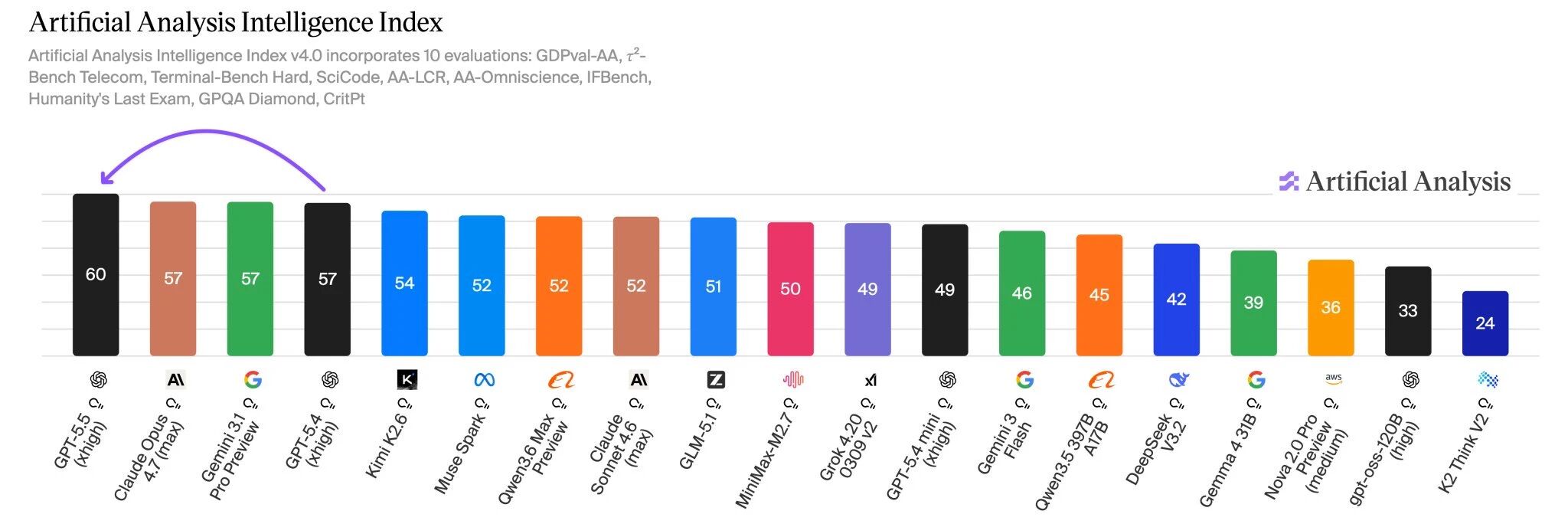
根据第三方评测平台 Artificial Analysis 的综合智能指数,GPT-5.5 在知识、推理、代码、工具使用、长上下文、真实任务等多个维度综合评分达到目前最高分,比 Claude Opus 4.7 和 Gemini 3.1 Pro Preview 高出 3 分。
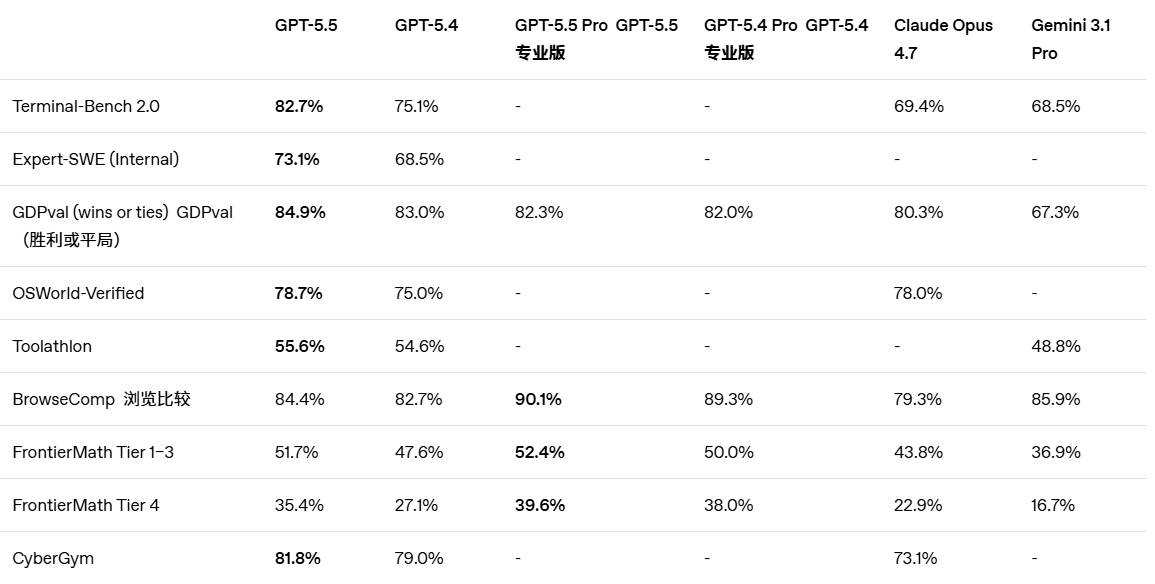
关键基准测试成绩
| 基准测试 | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 |
|---|---|---|---|
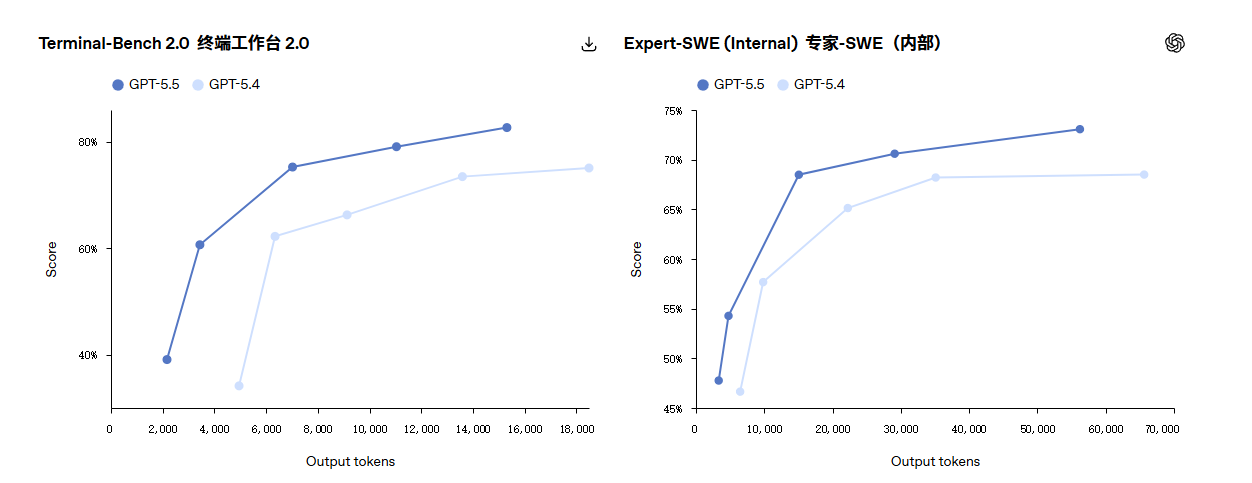
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% |
| OSWorld(计算机操作) | 78.7% | - | - |
| GDPval(专家产出质量) | 84.9% | - | - |
| Expert-SWE(长周期编码) | 73.1% | - | - |
| SWE-Bench Pro | 58.6% | - | 64.3% |
| FrontierMath Tier 4 | 35.4% | 27.1% | - |
苏米注:值得注意的是,GPT-5.5 在 SWE-Bench Pro(真实 GitHub issue 修复)上是唯一低于 Claude Opus 4.7 的项目,这说明在特定场景下 Claude 仍有优势。但综合来看,GPT-5.5 的整体表现更加均衡。
智能体编程:从执行到理解系统架构
GPT-5.5 展现出对复杂系统的深层理解能力。Every 创始人 Dan Shipper 分享了一个典型案例:在应用发布后出现问题时,他花费数天调试无果,最终请来顶尖工程师重写部分系统。为测试 GPT-5.5,他"倒回时钟"让模型查看损坏状态,结果 GPT-5.5 成功生成了与工程师最终决定相同的重写方案,而 GPT-5.4 无法完成这一任务。
"这是我使用过的第一个具有真正概念清晰度的编码模型,"Shipper 评价道。
MagicPath CEO Pietro Schirano 也见证了类似突破:GPT-5.5 将包含数百个前端和重构更改的分支合并到同样发生重大变化的主分支中,仅用约 20 分钟就一次性解决了所有工作。
官方案例展示:从 Demo 到生产级应用
OpenAI 官方展示了多个编程案例,展示了 GPT-5.5 的实际能力:
太空轨迹可视化
结合真实 NASA/JPL 数据,将飞行轨迹、星体位置和交互展示做出来,观感接近专业的科普应用。
地震追踪器
这更像一个真实的信息看板,数据、标题、指标和页面排版都比较完整,不是粗糙的 Demo。
地下城游戏
有了基本的游戏完成度,包括场景、角色、战斗、敌人、HUD 反馈等,说明它能处理更复杂的前端交互和游戏逻辑。
3D 游戏开发
在 Three.js 游戏开发上的能力,从低多边形画面、坦克控制、UFO 飞行到射击反馈,都表现出色。
知识工作:从信息处理到自主决策
GPT-5.5 在文档生成、电子表格和幻灯片制作方面表现优于前代。当结合 Codex 的计算机使用技能时,模型能够真正"与您一起使用计算机":查看屏幕内容、点击、输入、导航界面,并在工具间精确移动。
OpenAI 内部已将这些优势应用于实际工作流。超过 85% 的员工每周使用 Codex,涵盖软件工程、财务、通信、市场营销等多个职能部门:
- 通信团队:分析六个月演讲请求数据,建立评分和风险框架,验证自动化 Slack 代理
- 财务团队:审查 24,771 份 K-1 税表(总计 71,637 页),比前一年提前两周完成任务
- 市场团队:员工自动化生成周度业务报告,每周节省 5-10 小时
科学研究:从回答问题到推动发现
GPT-5.5 在科学和技术研究工作流上显示出显著进步。在 GeneBench(遗传学和定量生物学中的多阶段科学数据分析评估)上,相比 GPT-5.4 有显著提升。
更令人印象深刻的是,GPT-5.5 帮助发现了关于 Ramsey 数的新证明,这是组合数学中的核心对象。该证明后来在 Lean 中得到验证,展示了 GPT-5.5 不仅提供代码或解释,还能在核心研究领域贡献令人惊讶且有用的数学论证。
波兰亚当·密茨凯维奇大学数学助理教授 Bartosz Naskręcki 使用 GPT-5.5 在 11 分钟内从单一提示构建了代数几何应用,可视化二次曲面交点并将结果曲线转换为 Weierstrass 模型。
Codex 浏览器交互:从阅读到操作
随着 GPT-5.5 的推出,Codex 现在能够更有效地在浏览器、文件、文档和计算机应用中完成工作。OpenAI 显著扩展了浏览器的使用能力,使 Codex 可以与 Web 应用交互、测试流程、点击页面、捕获截图,并根据所见内容迭代直到完成任务。
技术社区对此反应热烈。aipulsedaily 指出:"'根据所见内容迭代'是关键短语。截图结果、视觉识别错误、修复、重复。这正是开发者实际需要的前端测试循环。"
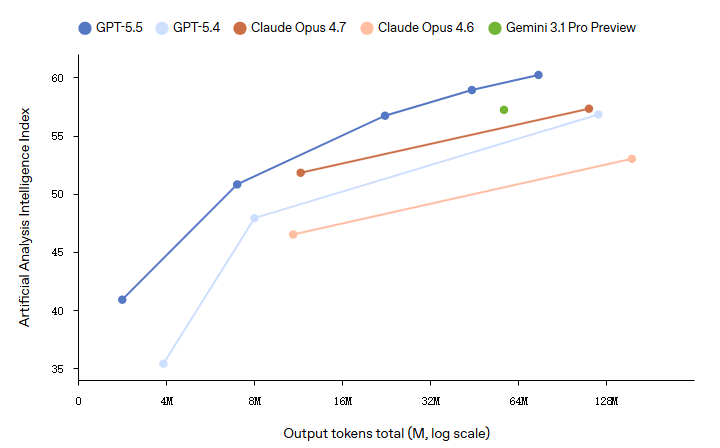
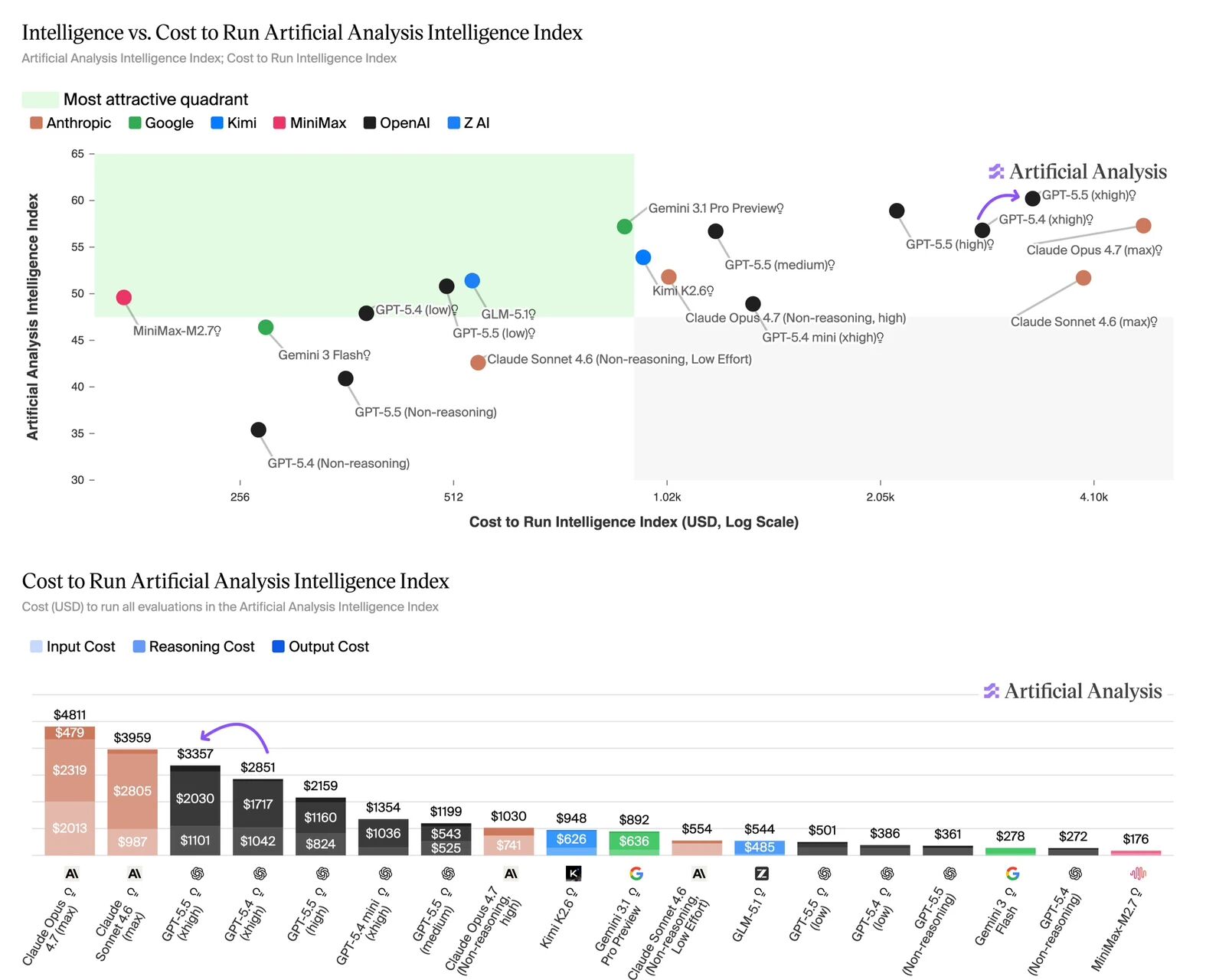
性能与效率的双重突破
GPT-5.5 在保持与 GPT-5.4 相同每 token 延迟的同时,在几乎所有评测中都表现更好。更重要的是,它在完成相同 Codex 任务时使用的 token 数量显著减少,使其既更高效又更强大。
Codex 分析了几周的生产流量模式,并编写了自定义的调度算法来最优地分区和平衡工作。该努力产生了超出预期的影响,将 token 生成速度提高了 20% 以上。
API 定价策略
GPT-5.5 今天向 ChatGPT 和 Codex 的 Plus、Pro、Business 和 Enterprise 用户推出。
| 模型 | 输入 Token(每百万) | 输出 Token(每百万) | 说明 |
|---|---|---|---|
| gpt-5.5 | $5 | $30 | 标准版本 |
| gpt-5.5-pro | $30 | $180 | 专业版本 |
| Fast 模式 | 生成速度提高 1.5 倍,成本为 2.5 倍 | 高速模式 | |
虽然 GPT-5.5 的定价高于 GPT-5.4,但它既更聪明又更加 token 高效。在 Codex 中,OpenAI 已经细心调整体验,以便 GPT-5.5 为大多数用户使用更少的 token 获得更好的结果。
技术社区反响
Cursor 联合创始人兼 CEO Michael Truell:"GPT-5.5 明显比 GPT-5.4 更聪明、更持久,具有更强的编码性能和更可靠的工具使用。它在没有提前停止的情况下保持任务的时间显著更长,这对我们用户委托给 Cursor 的复杂、长期运行的工作最为重要。"
NVIDIA 企业 AI 副总裁 Justin Boitano:"GPT-5.5 提供了执行密集型工作所需的持续性能。构建和服务于 NVIDIA GB200 NVL72 系统上,该模型使我们的团队能够从自然语言提示中发布端到端功能,将调试时间从几天缩短到几小时,并将数周的实验转化为复杂代码库中的隔夜进展。"
从能力分数到完成率的转变
随着 GPT-5.5 的推出,单次提示的时代似乎正在过去。智能体工作流将成为新的标准,而完成率而非能力分数,将成为衡量 AI 实际价值的关键指标。
正如一位开发者评论:"每个初创公司高管读到这个都会批准一个项目,现在每个任务可以调用 10 倍以上的 API,因为基本上免费了。"
模型质量在狭窄范围内趋于平稳,但完成率在整个工作流中复合增长。GPT-5.5 的发布标志着 AI 正从"有多聪明"向"有多少任务可以在无需人工干预的情况下端到端完成"的根本性转变。
参考资料: