作为Claude Code的深度用户,我一直在探索如何让AI助手更懂我、记住我。
最近两个月,我被一个核心问题困扰:每次开启新对话,都要花15分钟重新建立上下文——介绍自己的身份、项目技术栈、代码风格偏好……这种重复劳动不仅浪费时间,还白白消耗token。
直到我找到了mcp-memory-service这个工具,问题才真正得到解决。
这篇文章会详细拆解这个方案的工作原理、实战配置、以及与其他同类工具的差异。
核心问题:Claude为什么总是失忆?
Claude本身没有跨会话记忆能力,每一次对话都是一个全新开始。
这意味着:
- 你的项目背景信息无法保留
- 代码风格偏好每次都要重新说明
- 团队协作时,新成员需要重复理解项目上下文
- 大量重复信息消耗token预算
两个解决方案对比
市场上有两个主流方案:
| 维度 | claude-mem | mcp-memory-service |
|---|---|---|
| 安装难度 | 极低(两行命令) | 中等(需配置) |
| 适用客户端 | 仅Claude Code | 13+应用(Claude Desktop、VS Code、Cursor等) |
| 存储方案 | 本地SQLite | 本地+云同步混合 |
| 记忆整合 | 无 | 有(梦境式算法) |
| 质量分类 | 基础 | DeBERTa + MS-MARCO双模型 |
| 团队协作 | 不支持 | OAuth 2.1共享 |
mcp-memory-service的核心能力
先看界面:
1、可手动输入和自动记忆和管理
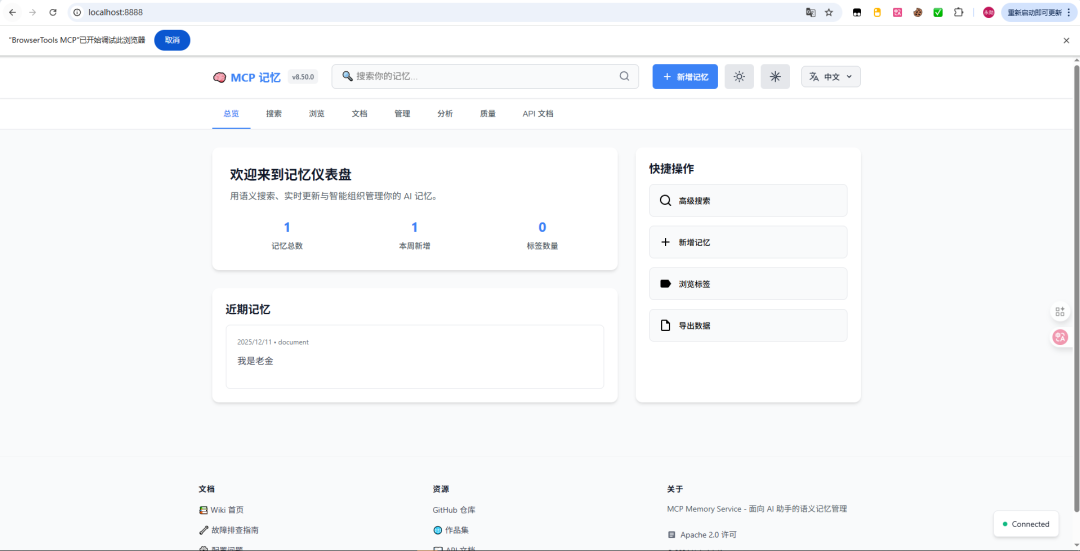
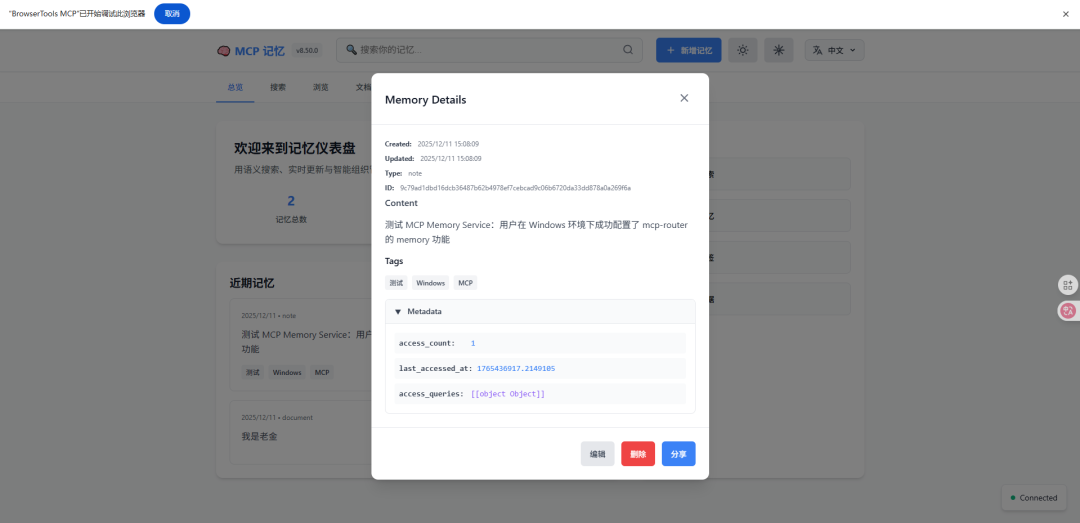
2、搜索所有记忆
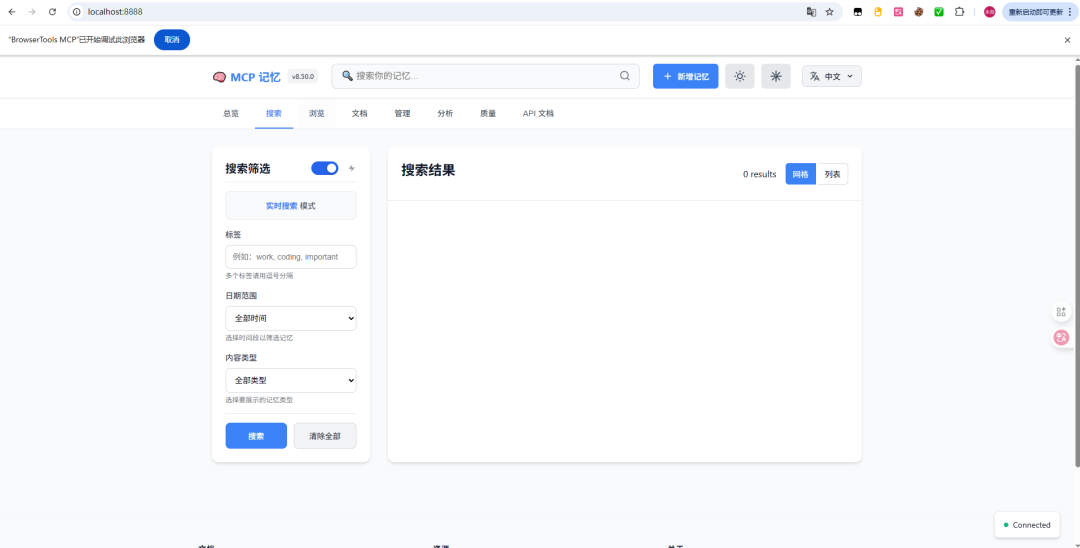
3、直接提交文档!
4、导出记忆!
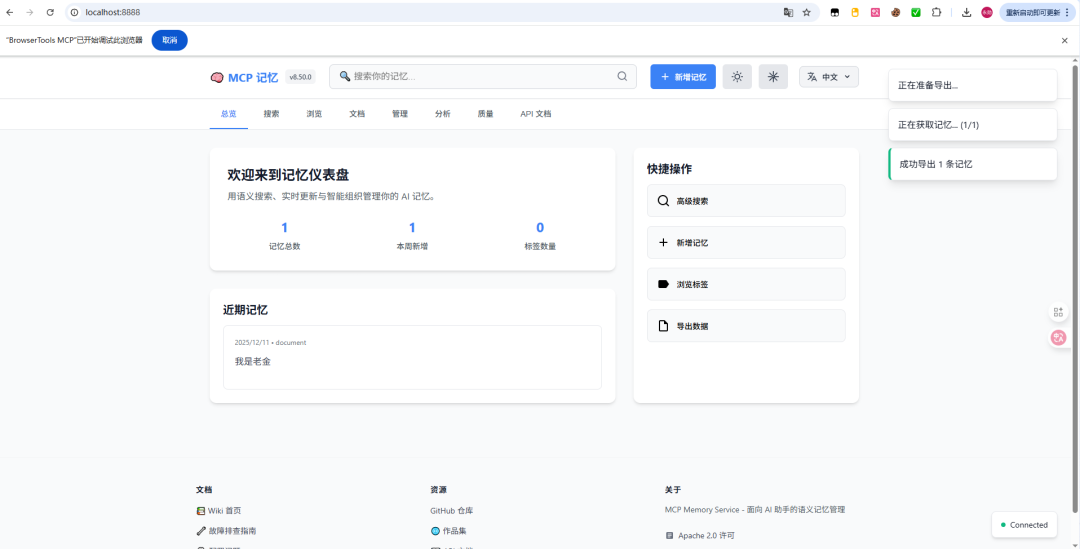
5、最离谱的,它能分析质量,自己做迭代!
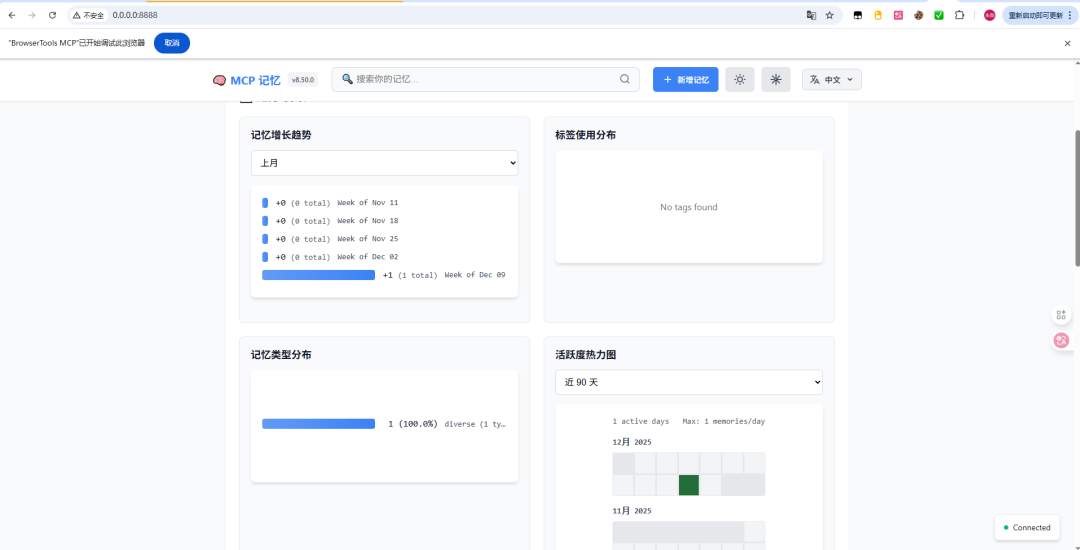
数据指标(生产环境实测)
- 上下文设置速度提升96.7%:从15分钟压缩到30秒自动加载
- 本地读取延迟5ms:基于SQLite-vec的向量存储,无数据库锁冲突
- 令牌消耗减少65%:通过OAuth协作复用信息,避免重复描述
- 团队规模验证:1700+条记忆在实际团队部署中稳定运行
工作原理:语义搜索数据库
与传统关键词匹配不同,mcp-memory-service使用语义搜索理解对话含义。例如:
- 存储:「项目用React 18 + TypeScript」
- 查询:「帮我写个组件」
- 结果:系统理解「组件」与「React」的关联,自动调出相关记忆
这由一个25MB的嵌入模型(all-MiniLM-L6-v2)实现,首次启动自动下载。
三种存储模式详解
1. 混合模式(推荐)
本地SQLite + Cloudflare后台同步的最佳组合:
- 本地读取5ms超快响应
- 多设备无缝同步
- 零数据库锁问题
配置方式:
export MCP_MEMORY_STORAGE_BACKEND=hybrid
export CLOUDFLARE_API_TOKEN="your-token"
export CLOUDFLARE_ACCOUNT_ID="your-id"
export CLOUDFLARE_D1_DATABASE_ID="your-db-id"
export MCP_MEMORY_SQLITE_PRAGMAS="busy_timeout=15000,cache_size=20000"2. SQLite-vec模式
纯本地存储,适合单人离线使用:
- 依赖小于100MB
- 无云服务依赖
- 一次性配置
3. Cloudflare模式
纯云存储,适合团队全球协作,但性能依赖网络连接。
四大高级功能详解
自然记忆触发(v7.1.3+,准确率85%)
无需手动保存——系统自动判断哪些信息值得记住:
- 检测关键技术栈信息
- 提取项目约束条件
- 识别代码风格规范
梦境式记忆整合
定期整理记忆库的三个阶段:
- 衰减评分:常用记忆权重提高,冷记忆权重降低
- 关联发现:建立记忆间的知识网络
- 压缩归档:合并重复内容,优化存储空间
启动HTTP服务后自动调度:
uv run memory server --http性能参考:2495条记忆整合耗时4-6分钟。
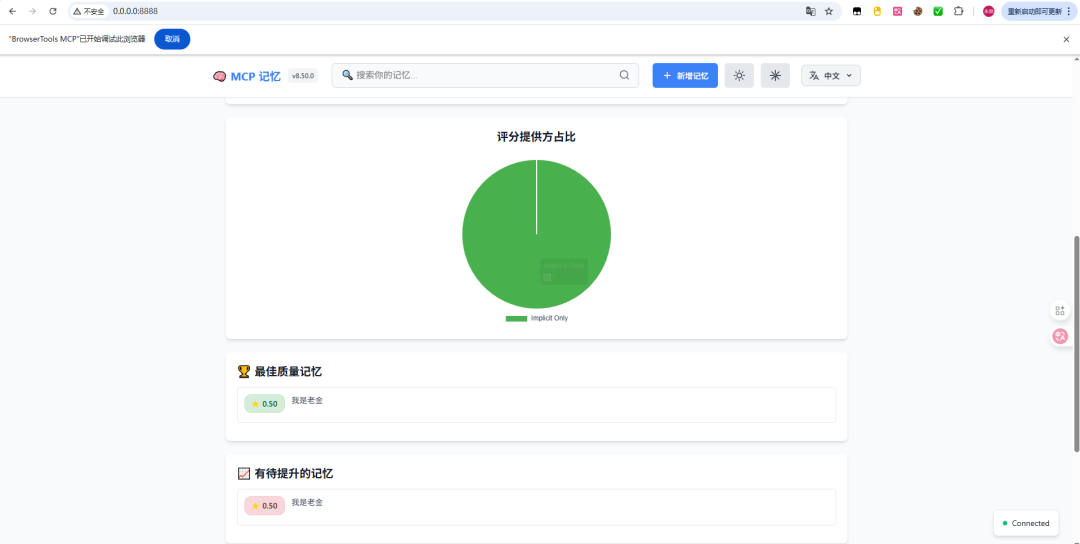
DeBERTa + MS-MARCO双模型救援(v8.50.0最新)
解决代码被误删的问题:
- DeBERTa首轮评分,分数低于0.6的不直接丢弃
- 交给MS-MARCO二次评估(微软搜索排序模型,对技术内容更友好)
- MS-MARCO评分超过0.7则保留
- 效果:代码评分从0.48提升到0.70-0.80,提升45-65%
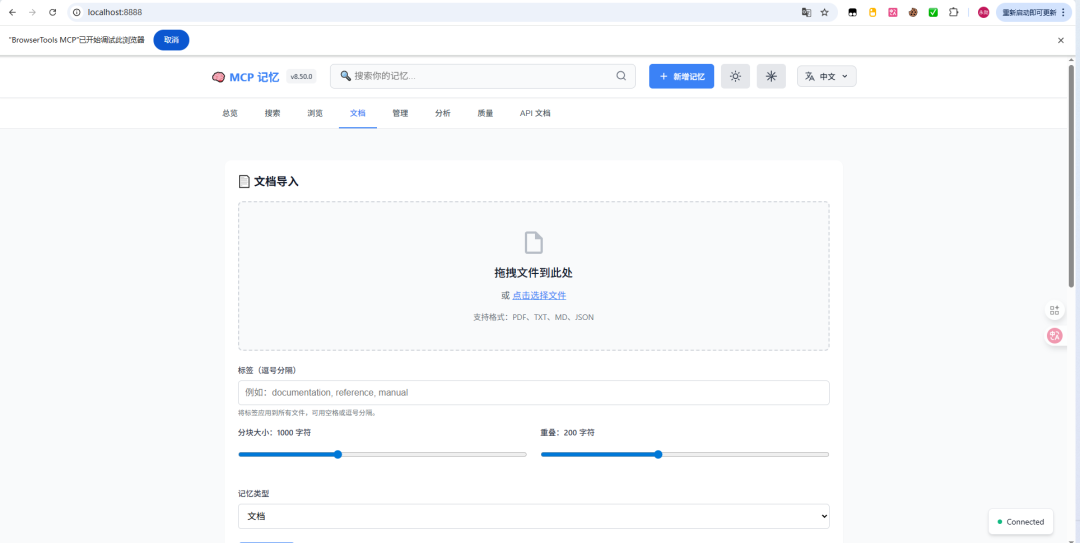
文档摄取系统(v8.6.0)
直接上传文档让Claude理解项目背景:
- 支持格式:PDF、TXT、MD、JSON
- 自动分块、打标签、入库
- 应用场景:技术规范、代码风格、PRD文档
Web界面上传:
uv run memory server --http
# 访问 http://127.0.0.1:8888命令行上传:
curl -X POST http://127.0.0.1:8888/api/documents/upload \
-F "file=@document.pdf" \
-F "tags=documentation"安装方案速查表
推荐:轻量安装
git clone https://github.com/doobidoo/mcp-memory-service.git
cd mcp-memory-service
python install.py完整ML功能
python install.py --with-mlDocker一键启动
docker-compose up -d
# 或HTTP+OAuth版本
docker-compose -f docker-compose.http.yml up -dSmithery自动集成
npx -y @smithery/cli install @doobidoo/mcp-memory-service --client claudeWindows环境完整配置指南
第一步:创建启动脚本
在项目根目录创建 start_server.ps1,内容包含:
- 端口号设置(8888)
- OAuth禁用(本地使用)
- 自动杀死旧进程防止端口占用
- 启动Uvicorn服务器
创建 start_server.bat 用于双击启动。
第二步:MCP配置
编辑 C:\Users\admin\.claude\mcp.json:
{
"mcpServers": {
"mcp-memory-service": {
"url": "http://127.0.0.1:8888/mcp",
"transport": "http"
}
}
}第三步:验证部署
三个测试命令:
- 健康检查:
curl http://127.0.0.1:8888/api/health - MCP初始化:验证协议连接
- 工具列表:确认40+个工具可用(store_memory、retrieve_memory、search_by_tag等)
Claude Code自动记忆配置
安装记忆钩子(30秒)
cd mcp-memory-service/claude-hooks
python install_hooks.py --natural-triggers验证安装
node ~/.claude/hooks/memory-mode-controller.js statusHooks工作流程
- session-start:会话开始时加载相关记忆
- user-prompt-submit:用户输入时自动触发记忆检索
- session-end:会话结束时保存新记忆
Windows用户需手动运行 /session-start 初始化,macOS/Linux全自动。
常见坑位与解决方案
坑1:Python版本不兼容
sqlite-vec缺乏Python 3.13预编译wheel。
解决:使用Python 3.12或切换Cloudflare后端。
坑2:macOS SQLite扩展缺失
系统Python默认不支持可加载扩展。
解决:用Homebrew安装 brew install python@3.12
坑3:国内网络模型下载失败
Hugging Face访问受限导致25MB嵌入模型无法下载。
解决:配置国内镜像
# Windows
set HF_ENDPOINT=https://hf-mirror.com
python -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('all-MiniLM-L6-v2')"
# macOS/Linux
export HF_ENDPOINT=https://hf-mirror.com
python -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('all-MiniLM-L6-v2')"坑4:首次启动警告
关于缓存、已弃用参数、模型下载的警告均为正常,首次成功运行后消失。
实战对比:同类工具分析
| 工具 | 支持客户端 | 记忆整合 | 质量分类 | 团队协作 | 学习曲线 |
|---|---|---|---|---|---|
| mcp-memory-service | 13+应用 | 梦境式算法 | DeBERTa+MS-MARCO | OAuth 2.1 | 中等 |
| OpenMemory MCP | 多平台 | 基础 | 简单分类 | 有 | 低 |
| claude-memory-mcp | Claude Code | 无 | 无 | 无 | 最低 |
| Knowledge Graph | Anthropic官方 | 基于图 | 实体-关系 | 有 | 高 |
日常使用命令速查
存储记忆
uv run memory store "项目用React 18 + TypeScript,代码风格遵循Airbnb规范"搜索记忆
uv run memory recall "React代码风格"标签搜索
uv run memory search --tags python debugging系统健康检查
uv run memory health手动整合
curl -X POST http://127.0.0.1:8888/api/consolidate实际使用体验总结
经过两个月的深度使用,我发现了几个关键改进:
- 上下文快速加载:新对话不用重复自我介绍,系统自动加载相关记忆
- 代码风格一致性:生成的代码自动适配我的风格偏好,减少手动调整
- 团队效率提升:通过OAuth共享记忆,新成员更快理解项目规范
- 偶发不相关记忆:虽然85%准确率很高,但15%的假阳性确实存在。新版本的DeBERTa+MS-MARCO救援机制已大幅改善
选型建议
强烈推荐安装场景:
- 每天频繁使用Claude的开发者
- Claude Code重度用户(代码上下文复杂)
- 跨多个AI工具的用户
- 有团队协作需求的团队
可以延后的场景:
- 仅偶尔使用Claude
- 项目上下文简单且变化少
方案选择矩阵:
- 仅Claude Code用户 → 装
claude-mem(两行命令) - 跨多工具使用 → 装
mcp-memory-service - 有团队协作需求 → 必须
mcp-memory-service
总结
作为Claude Code的深度用户,我认为mcp-memory-service填补了一个关键空白。不论是从工程的角度(106版本迭代、20贡献者的社区活跃度),还是从功能的角度(梦境式整合、双模型救援、混合存储),它都代表了第三方Claude记忆方案的目前最高水准。
配置确实需要一些工作量,但一旦部署完毕,它能以几乎零成本的方式帮你节省大量时间和token预算。如果你每天都在跟Claude对话,这个投入绝对值回票价。
官方正在推进的Memory功能预计2026年会更广泛推出,但在那之前,mcp-memory-service是我能找到的最完整的选择。
有任何问题,可以直接在GitHub提issue,社区反应速度很快。
你最期待Claude什么功能?欢迎评论区讨论。
参考资源
GitHub仓库:https://github.com/doobidoo/mcp-memory-service
完整文档:https://github.com/doobidoo/mcp-memory-service/wiki