Anthropic 最近在 Claude 平台上实装了一套"军师策略"(Advisor Strategy),主要目标是降低成本的同时提高次级模型的智商。
苏米注:最近很多网友反馈 Claude 降智了,其实 A 厂的顶尖模型 token 使用明显偏向 to B 和内部迭代。这个军师策略,说不定内部早就在用了。
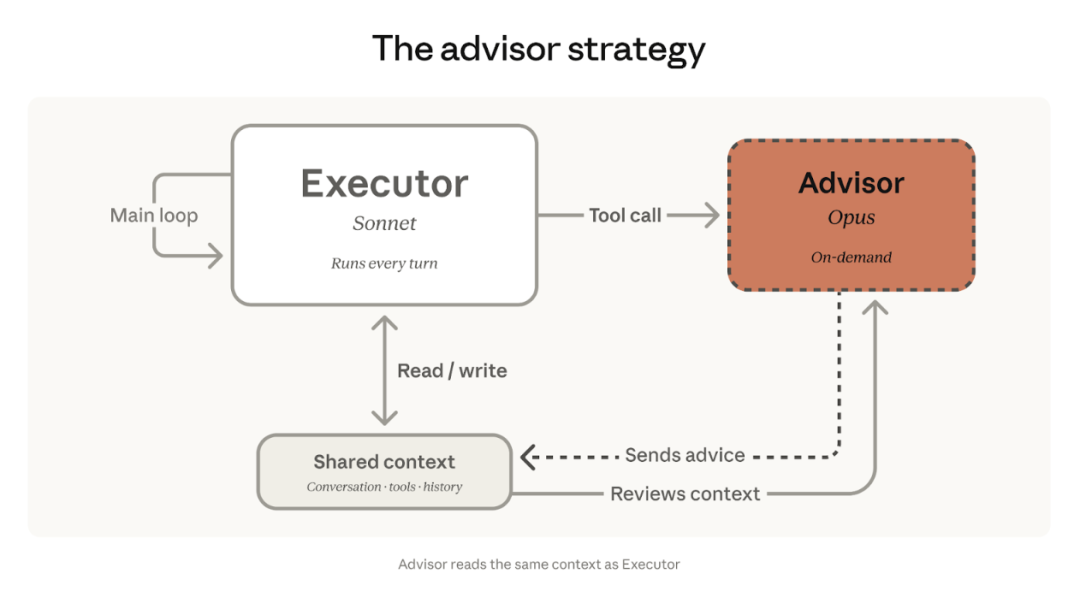
简单来说,就是让最强大的 Opus 模型在后台当军师,让轻量级的 Sonnet 或 Haiku 模型当执行者。通过这种搭配,开发者可以用极低的成本,让智能体获得接近 Opus 级别的智商。
运作机制
军师策略的运作非常巧妙:
- 执行者主导:Sonnet 或 Haiku 从头到尾运行任务,调用工具,读取结果,不断尝试解决问题
- 关键时刻呼叫:当执行者遇到高难度决策、觉得自己搞不定时,呼叫 Opus 军师寻求指导
- 军师出招:Opus 读取共享上下文,给出明确计划、纠错建议或停止信号
- 继续执行:执行者拿到建议后继续干活

苏米注:这个设计很聪明。军师绝对不会亲自调用工具,也不会直接生成最终内容,它的职责仅仅是给执行者提供高层指导。
与传统模式的对比
这种玩法直接反转了业界常用的子智能体模式:
| 模式 | 统筹节点 | 执行者 | 特点 |
|---|---|---|---|
| 传统子智能体 | 超大模型 | 小模型工人池 | 需要复杂任务拆解 |
| 军师策略 | 小模型(Sonnet/Haiku) | 小模型主导 | 军师只在卡壳时介入 |
在军师策略里,小巧且省钱的模型承担主导和汇报工作,最顶尖的推理算力全用在刀刃上。
实测数据
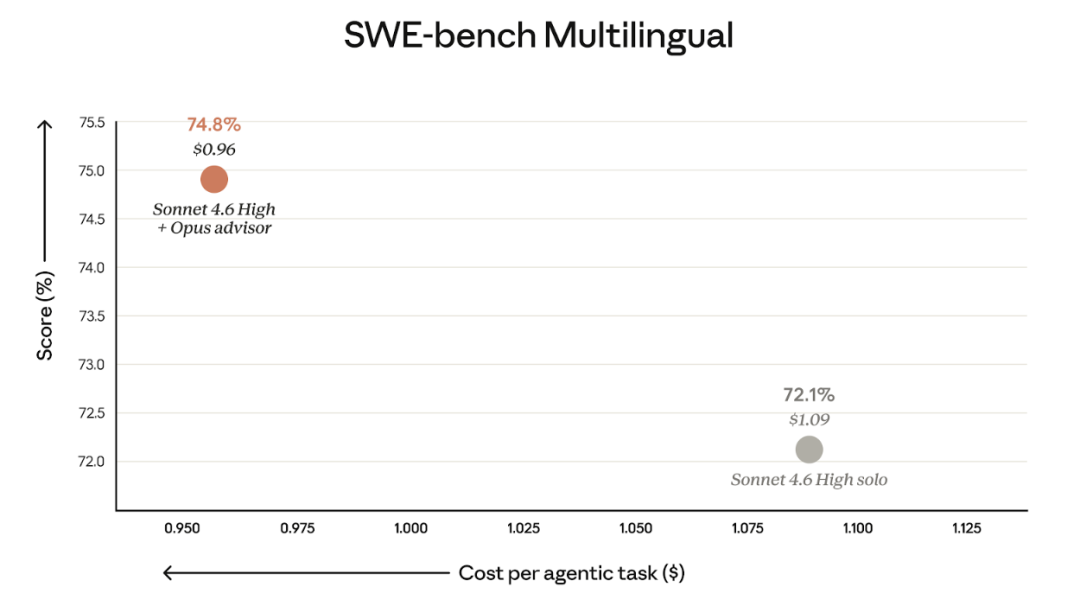
SWE-benchmark Multilingual 测试
带上 Opus 军师的 Sonnet 执行者:
- 得分提升:+2.7 个百分点
- 成本降低:-11.9%
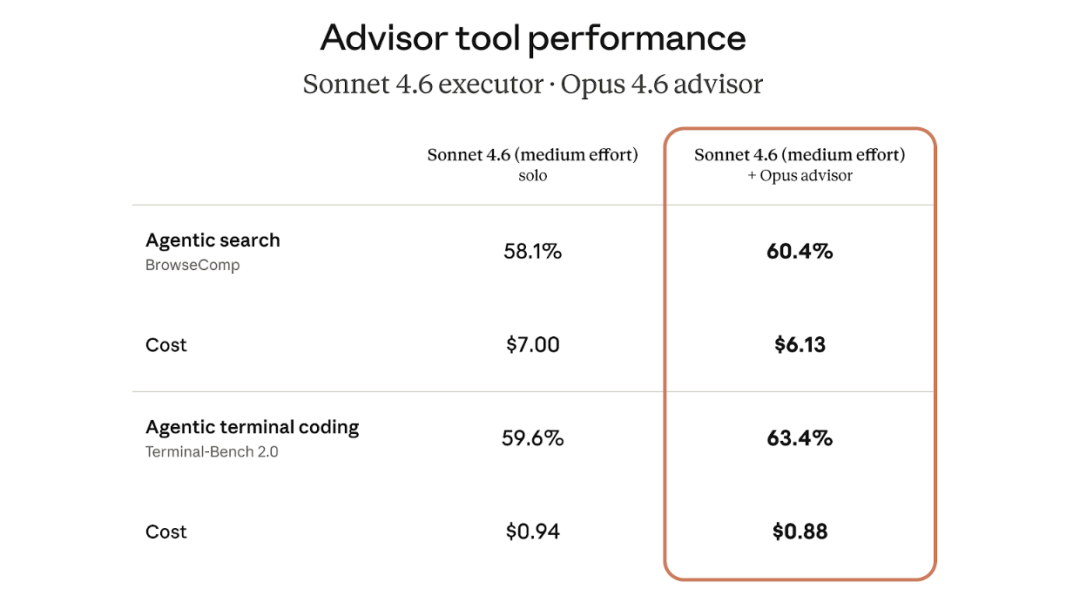
BrowseComp 和 Terminal Benchmark 2.0
有 Opus 当军师的 Sonnet 不仅得分全面提升,花费也比单独使用 Sonnet 时更少。
Haiku + Opus 组合
如果把执行者换成最小的 Haiku 模型,效果更加立竿见影:
- BrowseComp 得分:19.7% → 41.2%(翻倍)
- 成本下降:85%
- 对比 Sonnet:得分落后 29%,但成本只有零头
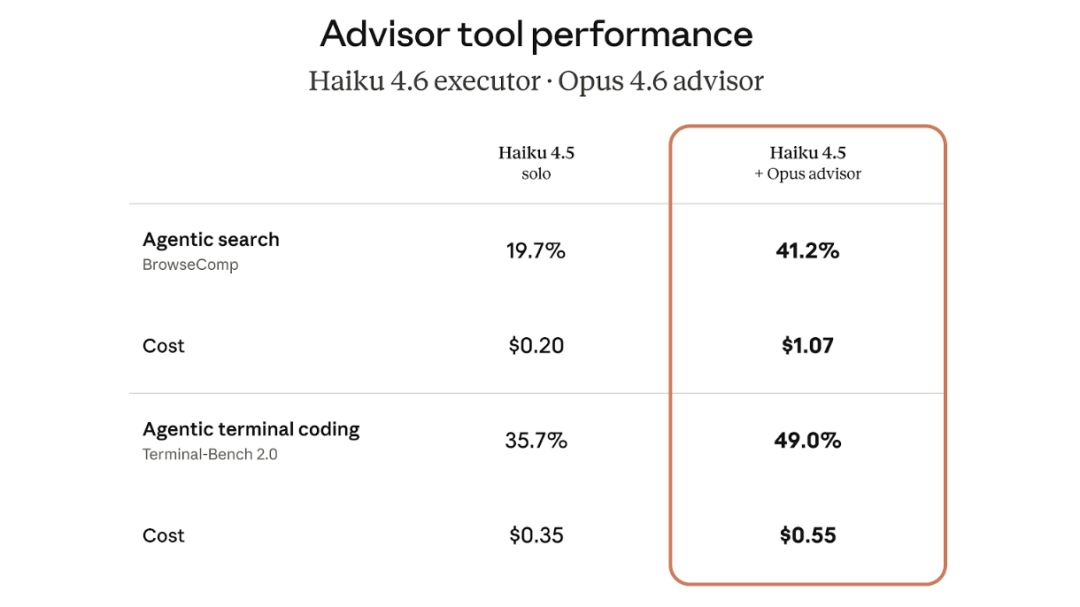
苏米注:对于既需要一定智商又面临海量高并发需求的场景,Haiku+ 军师是极具杀伤力的性价比选项。
如何使用
军师工具已在 Claude 平台开启 Beta 测试。开发者只需在 Messages API 请求中声明 advisor_20260301,模型的交接工作就会在同一个 API 请求内自动完成。
核心代码配置
response = client.messages.create(
model="claude-sonnet-4-6",
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
"max_uses": 3,
},
],
messages=[...]
)三个步骤上手
- 在请求头中加上 Beta 版特性声明:
anthropic-beta: advisor-tool-2026-03-01 - 在 Messages API 请求里添加
advisor_20260301 - 根据具体业务场景调整系统提示词
计费方式
计费逻辑非常清晰:
- 军师消耗的 Token:按 Opus 费率计算
- 执行者消耗的 Token:按轻量级费率计算
因为军师通常只吐出 400-700 个 Token 的简短指导计划,而耗费大量 Token 的最终长文本全交给价格低廉的执行者,所以总体成本被压在全量跑大模型之下。
成本控制功能
官方内置了成本控制:
- max_uses 参数:限制每次请求中呼叫军师的次数上限
- 使用情况明细:军师消耗的 Token 单独列出,方便追踪
技术栈兼容
军师工具本质上只是 API 请求列表里的一个新增条目。你的智能体可以一边搜索资料、一边敲代码测试,遇到死胡同时顺手向 Opus 请教,所有动作在同一个循环里完美闭环。
苏米注:Anthropic 官方建议开发者用自己的评估数据集跑对比测试,分别看看单跑 Sonnet、军师策略组合、单跑 Opus 的效果差异。这种实测数据最有说服力。
总结
Claude 的军师策略提供了一个巧妙的解决方案:用小模型主导,大模型只在关键时刻介入。既保证了智商,又控制了成本。
对于需要平衡性能和成本的开发者来说,这是一个值得尝试的新方案。