Gemma 4 正式发布:31B 参数跻身全球前三
2026 年 4 月,Google DeepMind 正式发布 Gemma 4 系列开源模型。旗舰版 Gemma 4 31B 在 Arena AI 排行榜位列全球第三,能够与体量大出 20 倍的闭源大模型正面竞争。
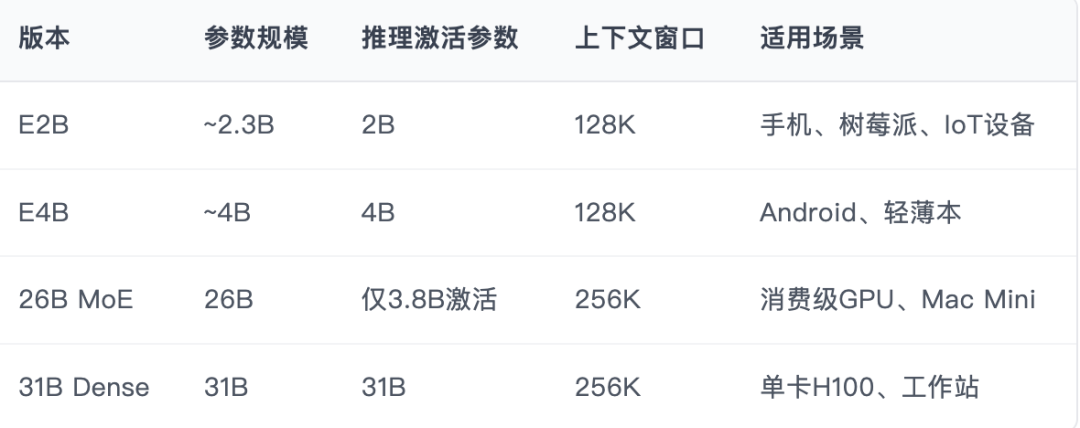
Gemma 4 提供四个版本,覆盖从手机到工作站的全场景部署:
- E2B(有效 2B 参数):边缘设备专用
- E4B(有效 4B 参数):移动端优化
- 26B MoE:混合专家架构,推理时仅激活 3.8B 参数
- 31B Dense:稠密模型旗舰版
其中 26B MoE 版本是整个产品线的工程亮点——以极低的计算成本在 Arena AI 排行榜拿下全球第 6 名,逼近旗舰级性能。
多模态能力全面升级
Gemma 4 是 Google 在开源端最彻底的多模态布局。所有版本均原生支持图像和视频帧输入,擅长 OCR 识别、图表理解、目标检测与视觉定位。
E2B 和 E4B 边缘版本额外支持音频输入,可离线完成语音识别与理解。模型支持多模态函数调用——可以给模型展示一张图片,让它根据图中内容调用外部 API。256K 超长上下文窗口支持一次性处理整个代码仓库或完整技术文档。
oMLX:Mac 原生推理引擎,速度超越 Ollama 3 倍
很多 Mac 用户第一次尝试本地模型都从 Ollama 开始,但往往因为速度太慢而放弃。根本原因是 Ollama 的设计缺陷:KV 缓存只存储在内存中,上下文一变就从头重算,导致每次长上下文推理的首 token 时延(TTFT)高达 30 到 90 秒。
苏米注:用 Ollama 跑 Agent 时,等待时间往往比模型实际思考时间还长,这严重拖慢了工作节奏。
oMLX 的核心优势
oMLX(github.com/jundot/omlx)是一款专为 Apple Silicon M 系列芯片打造的原生 macOS 大模型推理系统,完全基于苹果的 MLX 框架构建,从架构层面解决了 Ollama 的短板。
| 特性 | Ollama | oMLX | 提升 |
|---|---|---|---|
| Token 生成速度 | ~43 tok/s | ~130 tok/s | 3 倍 |
| 内存占用 | 100% | ~50% | 减半 |
| TTFT(首 token 时延) | 30-90 秒 | <5 秒 | 6-18 倍 |
关键技术突破:oMLX 采用 SSD 分页 KV 缓存技术,将每一个 KV 缓存块写入 SSD,之前处理过的上下文片段随时复用,无需重算。这是专为 OpenClaw 等 Agent 框架量身定制的核心技术,也是它与 Ollama 最本质的差距。
在兼容性方面,oMLX 同时提供 OpenAI 兼容和 Anthropic 兼容两套 API 端点,是 OpenClaw、Claude Code、Cursor 等工具的直接替代后端,切换成本极低。
Mac Mini:统一内存架构释放 AI 潜能
统一内存架构是 Mac Mini 碾压传统 PC 的底层逻辑。传统显卡 VRAM 通常只有 8–24GB,模型超限就崩溃;而 Mac Mini 的 CPU、GPU 和神经引擎共享同一内存池,不存在显存与内存的分割,模型可以自由使用全部统一内存。
苏米注:我在实际测试中发现,16GB 的 Mac Mini 用 oMLX 可以流畅运行 Gemma 4 26B MoE mxfp4 量化版,这在 Ollama 上几乎不可能实现。统一内存 + oMLX 的组合,让入门级 Mac Mini 具备了运行前沿模型的能力。
| 指标 | Mac Mini M4 | 双 GPU PC |
|---|---|---|
| 功耗 | ~30W | ~600W+ |
| 年电费 | ~$20-30 | ~$500+ |
| 噪音 | 几近无声 | 风扇噪音明显 |
| 推理框架 | oMLX (MLX) | CUDA/ROCm |
| 保值率 | 高 | 低 |
Mac Mini M4 基础款(16GB/24GB,叠加国补约¥3700/¥4700)已经可以搭配 oMLX 流畅运行 Gemma 4 E4B 或 7B–13B 量化模型,是目前入手本地 AI 最低的门槛之一。
OpenClaw 的最佳本地底座
OpenClaw 是 2026 年增长最快的开源 AI Agent 框架,设计目标是全天候自主运行,通过即时通讯工具接受指令,执行多步骤任务、管理文件、自动化工作流。
Gemma 4 + oMLX + Mac Mini 成为 OpenClaw 的理想底座,原因如下:
- 模型质量达标:Gemma 4 26B MoE 原生支持函数调用与结构化 JSON 输出,工具调用得分从 Gemma 3 的 6.6% 跃升至 85.5%,达到 SOTA 水平
- 速度够快:oMLX 在 16GB 内存 Mac Mini 上跑 Gemma 4 26B MoE mxfp4 版可达~22tok/s,Agent 每步推理响应时间比 Ollama 缩短超过 3 倍
- 长上下文不卡顿:oMLX 的 SSD 分页 KV 缓存专为 Agent 多轮长流程设计,TTFT 控制在 5 秒以内
- 数据主权:oMLX 本地推理,任何数据不离设备
- 全天候低功耗:Mac Mini M4 在 AI 负载下约 30W,全年电费仅 200 多元,是 7×24 小时运行的理想宿主机
结语
Gemma 4 的发布是开源 AI 在 2026 年最重要的事件之一。31B 参数模型能够战胜 600B+ 参数模型,多模态与 Agent 能力开箱即用,标志着开源小尺寸模型进化到"真的够用"的阶段。
而 Mac Mini 凭借统一内存架构消除 VRAM 瓶颈,配合 oMLX 带来比 Ollama 快 2 到 3 倍的本地推理速度,以及 SSD KV 缓存彻底解决 Agent 长上下文卡顿痛点,已经成为 2026 年运行本地 AI 的最佳性价比硬件选择。
实践经验:一台基础款 Mac Mini + Gemma 4 26B MoE + oMLX + OpenClaw,就是触手可及的私有 AI Agent 全栈方案,总成本不到一台旗舰手机的价格。