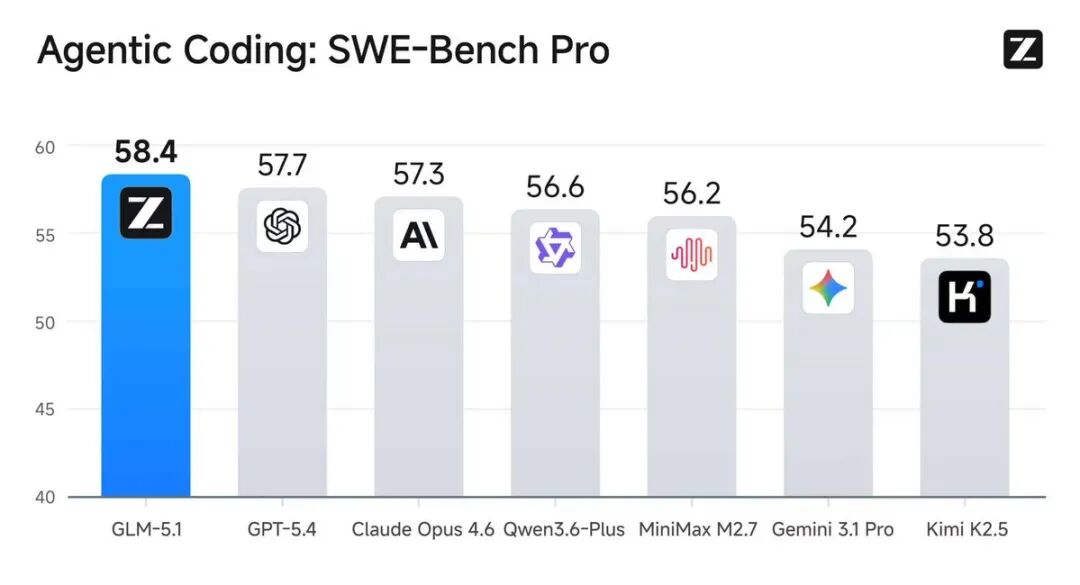
2026 年 4 月 8 日,智谱发布了 GLM-5.1 模型更新。官方博客披露的评测数据显示,这款开源模型在 SWE-Bench Pro(真实 GitHub 工程 Bug 修复)榜单上取得了 58.4 分,超越 GPT-5.4(57.7 分)和 Claude Opus 4.6(57.3 分),位列全球第一。
苏米注:这是首个在代码评测单项上超越 Opus 4.6 的开源模型,但需要理性看待——单项冠军不等于全能冠军。
代码能力评测:单项冠军,非全能
智谱使用了业界公认的三个代码评测基准进行测试:SWE-Bench Pro(修复真实 GitHub 工程 Bug)、Terminal-Bench 2.0(命令行问题解决)、NL2Repo(从零构建完整代码仓库)。
三项综合平均成绩排名如下:
| 模型 | 综合均分 | 排名 |
|---|---|---|
| GPT-5.4 | 58.0 | 第 1 |
| Opus 4.6 | 57.5 | 第 2 |
| GLM-5.1 | 54.9 | 第 3 |
| Gemini 3.1 | 52.0 | 第 4 |
| Qwen3.6+ | 51.0 | 第 5 |
单项成绩对比更能说明问题:
| 评测项目 | GLM-5.1 | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-Bench Pro | 58.4(全球第一) | 57.3 | 57.7 |
| NL2Repo | 42.7 | 49.8(领先 7 分) | 41.3 |
| Terminal-Bench 2.0 | 63.5 | 65.4 | - |
关键结论:GLM-5.1 在最硬的 SWE-Bench Pro 上拿到全球第一,但 NL2Repo(从零构建仓库)被 Opus 拉开 7 分差距,Terminal-Bench 也略逊一筹。对于开发者而言,SWE-Bench Pro 的含金量最高——这恰恰是 GLM-5.1 的强项。
长程任务能力:连续工作 8 小时的真正突破
相比代码跑分,官方博客中展示的长程任务能力更值得关注。传统模型像"考试型选手"——单题作答很快,但给一个完整项目要求"从头做到尾",往往二三十轮就开始原地转圈。
GLM-5.1 的设计目标是不仅能干,更能扛。
案例一:向量数据库优化(655 轮迭代)
官方展示了一个向量数据库近似搜索优化任务:
- 初始状态:Opus 4.6 在 50 轮限制下跑出 3,547 QPS
- GLM-5.1 结果:无轮数限制,最终达到 21,500 QPS,性能提升 6 倍
- 迭代过程:655 轮迭代,6000+ 次工具调用
优化轨迹呈现"阶梯形"特征——每到一个平台期,模型会分析日志、定位瓶颈、主动切换策略。整个过程中策略切换了 6 次方向:IVF 分桶 → 量化粗排 → 两级路由 → u8 量化 → 提前剪枝。
苏米注:这种"碰壁、分析、换方向、恢复"的循环,已经接近真人工程师的工作模式。关键不是给它更多时间,而是让第 8 个小时的产出依然有价值。
案例二:8 小时搭建 Linux 桌面系统
GLM-5.1 在 8 小时内从零搭建了一套完整的 Linux 桌面系统:
- 1200+ 步操作
- 交付成果:窗口管理器、终端、文件浏览器、计算器、游戏库
- 自写回归测试并通过
对比之下,大部分模型完成类似任务时往往只搭建空架子,放几个占位窗口就宣布完成。
案例三:24 小时优化 50 个机器学习任务
模型自主编写 GPU 优化代码、运行测试、分析结果、重写方案,最终实现 3.6 倍加速。不过在这个场景下,Opus 4.6 跑出了 4.2 倍,智谱在博客中大方承认了差距。
综合能力对比:与 Opus 4.6 正面对决
官方披露的其他维度评测数据:
| 评测项目 | GLM-5.1 | Opus 4.6 | 结论 |
|---|---|---|---|
| 数学推理(AIME 2026) | 95.3 | 95.6 | ≈ 持平 |
| 联网任务(BrowseComp) | 79.3 | 84.0 | Opus 领先 5 分 |
| 网络安全(CyberGym) | 68.7 | 66.6 | GLM 赢 |
| 商业模拟(Vending Bench 2) | $5,634 | $8,017 | Opus 领先 |
综合判断:代码和智能体能力达到全球前三水平,推理能力不拉胯但未领先,综合实力与 GPT-5.4、Gemini 3.1 Pro 相比仍有差距。但对一个开源模型而言,能与闭源巨头逐项 PK 已属不易。
使用方式与定价
GLM-5.1 采用 MIT 协议完全开源,代码托管在 GitHub 和 HuggingFace:
使用 Claude Code 或 OpenClaw 的用户,直接修改模型配置即可切换。所有 GLM Coding Plan 套餐用户均可使用,包括最便宜的 Lite 档。
定价策略方面,智谱在半年内已涨价 3 次,本次发布后又上调 10%。非高峰时段(日常简单任务使用 GLM-4.7)限时 1x 额度优惠至 4 月底,高峰期(14:00-18:00)额度消耗为 3x。
苏米注:一年前国产模型还在打价格战抢用户,现在价格已接近 Claude Sonnet 4.6。从"我便宜所以用我"到"我真能干活所以我敢贵",国产模型正在完成价值定位的转变。
总结
智谱在博客中提出了一个新标准:过去比谁更聪明,未来比谁能干更久。如果模型真的能独立工作 8 小时,使用范式将从"对话"转变为"交代任务"。
需要强调的是,以上所有数据均来自官方博客,实际表现仍需上手验证。跑分仅供参考,关键还是看实际应用场景中的表现。