作为一名长期体验AI产品的产品经理,我经常面临一个普遍的内容消费痛点:高质量的视频内容繁多,但快速将其转化为可复用的文档资产却始终是个低效的手工活。
最近在GitHub发现了一个相对成熟的开源项目:AI-Media2Doc(现已获得3.5k Star),它以相对简洁的技术架构解决了"视频/音频到文档"的转换需求。本文将从产品设计、技术实现和应用价值三个维度展开分析。
项目概览
核心定位: AI-Media2Doc 是一款面向内容创作者、学生、知识工作者的视频/音频到文档的自动转换工具。

其主要价值在于降低内容二次加工的成本——通过AI语言模型处理音频转录,自动生成多种风格的文档产物。

主要功能清单:
音频提取与转录:支持视频链接或本地音频文件输入,自动完成音频提取和语音转文字
多风格文档输出:
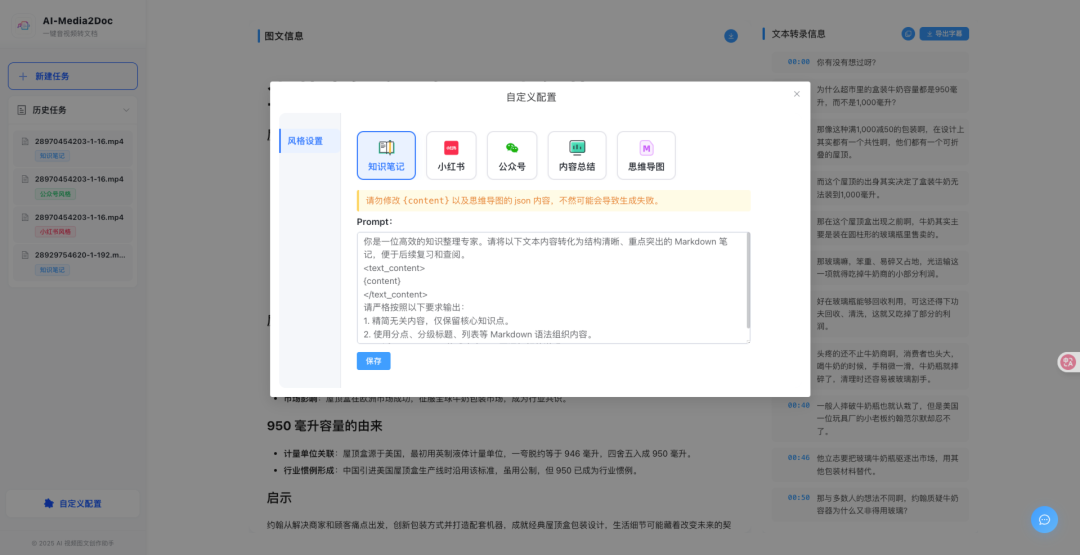
小红书风格 — 图文笔记格式
公众号风格 — 公众号排版文章
知识笔记 — 结构化学习笔记
思维导图 — 逻辑结构梳理
视频字幕 — 字幕文件导出
内容总结 — 核心要点提取
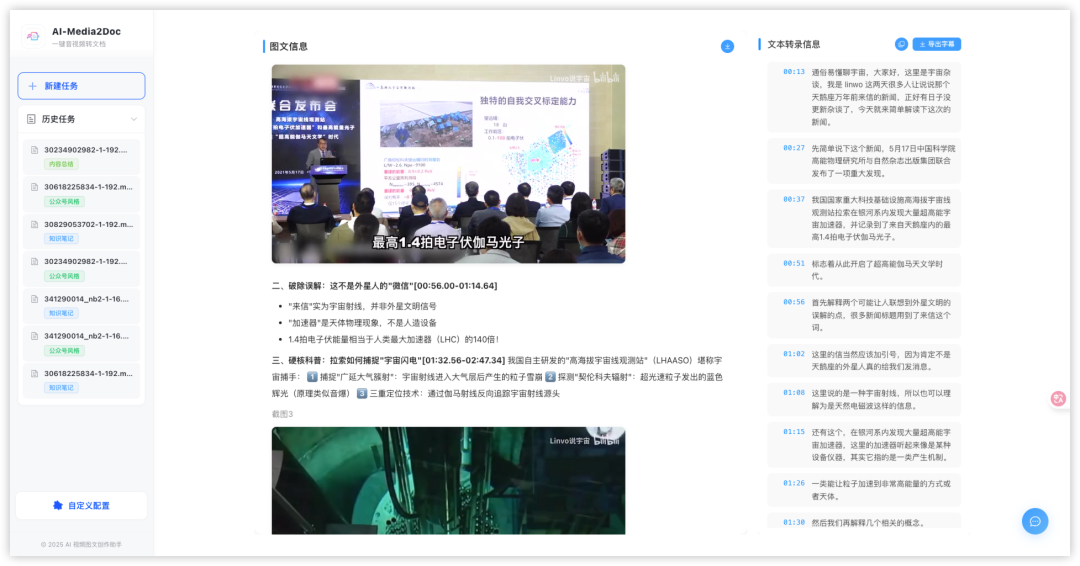
智能截图功能:根据字幕时间轴自动在原视频对应位置截图,直接嵌入文档
AI对话交互:转换完成后可针对视频内容进行后续提问澄清
Prompt自定义:支持前端直接修改输出Prompt,灵活适配不同内容风格需求
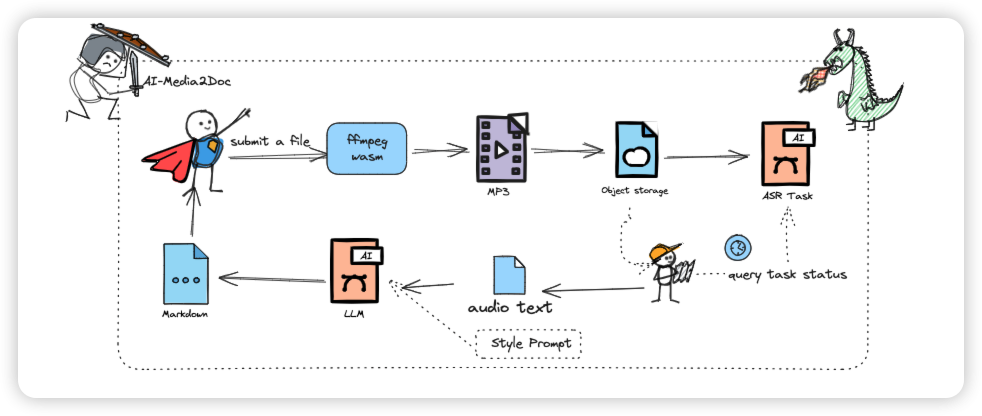
技术架构
技术栈组成:
- 前端:Vue.js
- 后端:Python
- 音频处理:FFmpeg + WebAssembly
- 大模型接入:支持多种LLM(ChatGPT、豆包等)
- 部署方案:Docker容器化
架构特点:
- 处理流程清晰:音频提取→转录→Prompt组织→LLM处理→结果渲染,每个环节相对独立
- 隐私友好:无需登录注册即可使用,源代码完全开源(MIT协议),用户可自行部署掌控数据流向
- 零视觉模型成本:智能截图功能不依赖单独的视觉大模型,通过字幕时间戳匹配视频帧实现,降低部署和推理成本
快速部署指南
系统要求:
- Docker 及 Docker Compose 环境
- 配置有效的LLM API密钥(如OpenAI或国内大模型)
部署步骤:
- 在本地克隆项目或下载 docker-compose.yaml
- 配置 variables.env 文件,填入LLM API密钥和其他必要参数
- 执行部署命令:
docker-compose -f docker-compose.yaml up -d - 访问本地服务地址即可使用
配置管理: 核心配置集中在 variables.env 文件中,包括模型选择、API端点、输出偏好等,修改后重启容器生效。
项目代码结构清晰,有能力的使用者可基于需求扩展功能模块。
应用场景分析
| 用户群体 | 典型场景 | 使用价值 |
| 自媒体创作者 | 视频内容转公众号/小红书 | 一次录制,多渠道发布;减少排版时间 |
| 学生/学习者 | 网课/讲座转学习笔记 | 快速生成结构化笔记;期末复习资料 |
| 知识工作者 | 播客/会议录音转文档 | 会议内容存档;知识沉淀 |
| 内容团队 | 内容库建设与二次创作 | 加速内容流转;支撑多形式内容策略 |
注意事项: 在内容搬运或二次创作场景中,需严格遵守原创作者的版权声明和平台协议,避免不当转载。
相似项目对比
在视频转文档领域,还有其他开源或商用方案值得了解:
- Whisper(OpenAI):专注语音转录质量,需自行搭建文档生成流程
- Descript:功能完整的商用方案,提供Web界面和API,但付费模式且代码不开源
- AI-Media2Doc 的差异:聚焦于"转录+多风格输出"的端到端流程,完全开源可自部署,更适合对隐私或成本敏感的用户
总结
作为产品经理,我对AI-Media2Doc的评价是:"实用而克制"。它没有过度承诺AI的能力,而是在明确的问题域内(视频/音频到文档)提供了相对完整的解决方案。项目的几个亮点值得关注:
- 实现成本低:利用字幕时间轴做截图,避免了视觉模型的复杂依赖
- 部署友好:Docker一键化部署,降低了非技术用户的入门门槛
- 灵活性强:Prompt可自定义,适配不同内容风格和行业需求
- 隐私保障:完全开源,用户可掌控数据流向
不过也需要认识到其局限:输出质量最终仍然依赖于所接入的LLM模型,音频质量不佳的视频转录效果会受影响。对于有规模化需求的团队,还需配套考虑转录质量评估、输出内容审核等环节。
总的来说,如果你是内容创作者、学生或知识工作者,且关心数据隐私或希望自主部署,AI-Media2Doc 值得一试。