在过去几个月的产品调研中,我发现许多团队在构建多模态AI应用时都面临一个共同的痛点:需要在数据库、文件存储、向量库、API服务和编排系统之间反复切换,用大量胶水代码维持整个流水线的运转。这种架构不仅开发效率低下,还容易在数据流转过程中引入bug。直到接触到Pixeltable,我才意识到还有更简洁的解决方案。
项目定位与核心价值
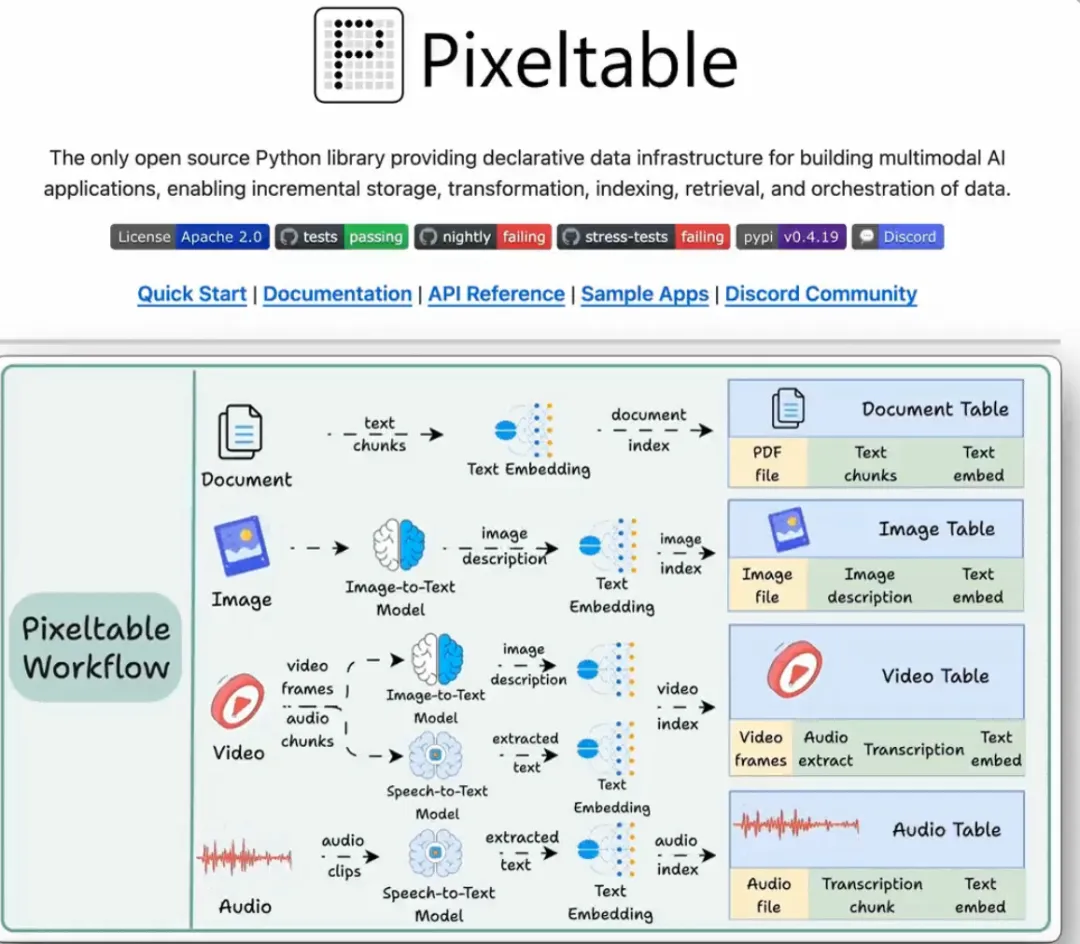
Pixeltable是一个开源的声明式数据框架,核心理念是将复杂的多模态AI流水线统一为单一的表格接口。不同于传统的微服务编排方式,它将数据存储、计算、向量索引和版本管理整合在一个统一的抽象层中,让开发者能够专注于业务逻辑而非基础设施搭建。
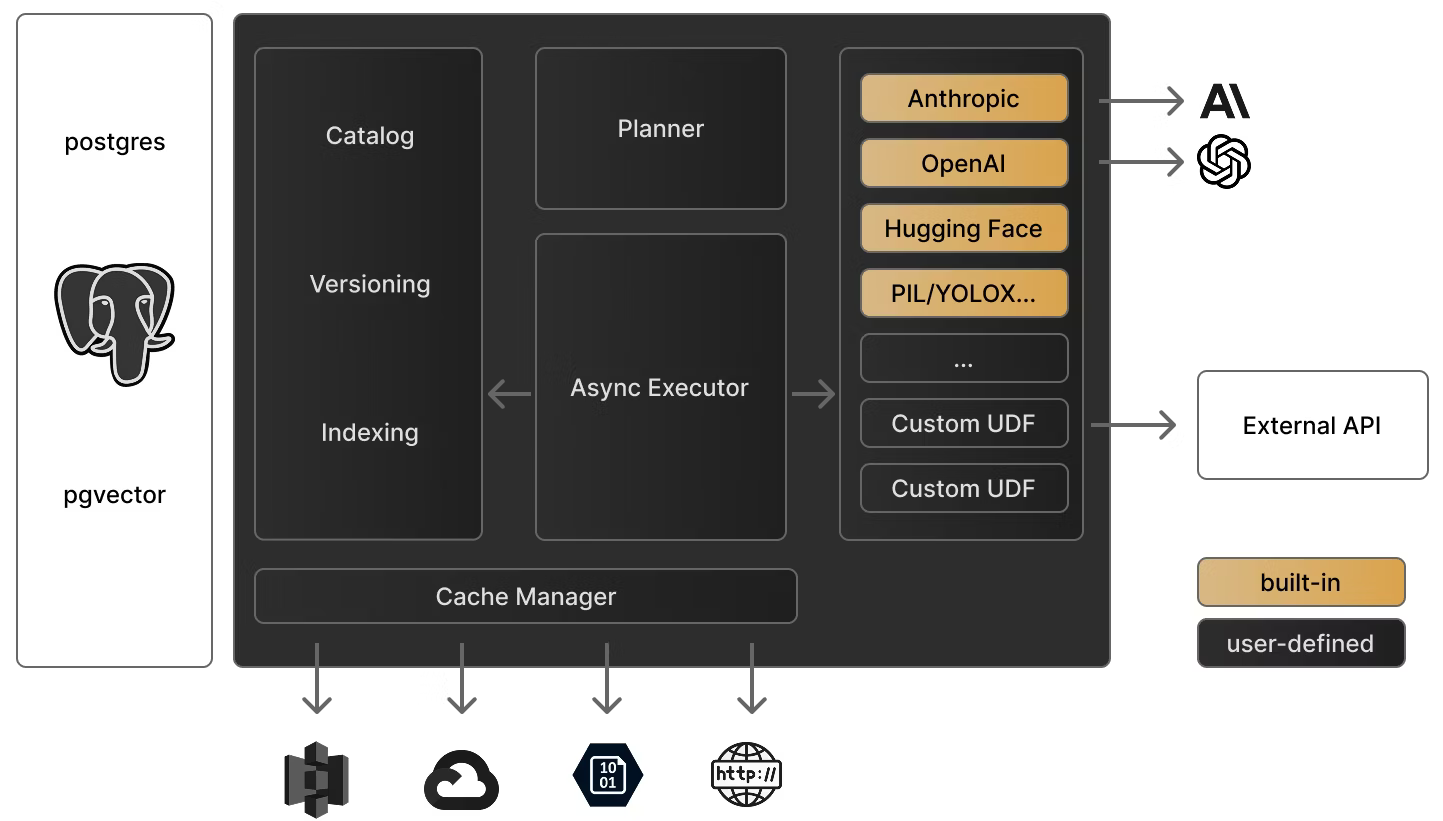
相比之下,同类产品如LangChain侧重于链式调用的编程范式,Apache Airflow则面向工作流编排,而Pixeltable的差异在于:它将所有操作都映射到表的结构化视图,使得数据血缘追踪和增量计算成为原生特性。
核心功能详解
1. 多模态数据统一管理
Pixeltable内置支持Image、Video、Audio、Document等多种数据类型,允许在同一张表中混合存储和处理不同模态的数据。这意味着你无需额外配置多个存储系统,所有数据都以结构化方式组织。
2. 声明式计算列
定义一次处理逻辑,新插入的数据会自动触发计算。这种声明式的设计模式降低了维护成本,避免了手动触发计算的繁琐工作。
3. 内置向量搜索能力
直接在表上执行语义搜索,无需额外部署向量数据库。这对于RAG(检索增强生成)系统特别有价值。
4. 增量计算与成本优化
框架能够智能识别哪些数据需要重新计算,仅对必要部分执行操作,显著降低API调用成本和计算时间。
5. 数据血缘与版本控制
自动记录数据变化、模型更新和处理步骤的完整链路,便于调试、审计和回溯。
应用场景分析
| 应用场景 | 典型用例 | 核心优势 |
|---|---|---|
| 多模态RAG系统 | 文档分块、向量索引、语义检索一体化 | 无需部署独立向量库,数据流转透明 |
| 计算机视觉流水线 | 图像检测、分类、相似度搜索、特征提取 | 支持级联模型,增量处理大规模图像集合 |
| AI Agent系统 | 基于Pixeltable的PixelBot框架,多轮交互数据管理 | 对话历史、中间结果自动持久化和版本化 |
| 媒体内容处理 | 视频分析、字幕生成、多语言翻译 | 支持视频帧级别操作,自动管理时间序列数据 |
安装与快速开始
环境要求:Python 3.8+,推荐使用虚拟环境隔离依赖。
安装命令:
pip install -qU torch transformers openai pixeltable基础示例 - 图像处理流水线:
import pixeltable as pxt
from pixeltable.functions import huggingface, openai
# 创建表,定义多模态列
t = pxt.create_table('images', {'input_image': pxt.Image})
# 添加计算列:目标检测(自动管理模型)
t.add_computed_column(
detections=huggingface.detr_for_object_detection(
t.input_image,
model_id='facebook/detr-resnet-50'
)
)
# 提取检测结果的标签文本
t.add_computed_column(detections_text=t.detections.label_text)
# 集成OpenAI Vision API,内置限流和异步管理
t.add_computed_column(
vision=openai.vision(
prompt="Describe what's in this image.",
image=t.input_image,
model='gpt-4o-mini'
)
)
# 插入数据(自动触发所有计算列)
t.insert(input_image='https://example.com/image.jpg')
# 查询结果(结构化和非结构化数据混合返回)
results = t.select(
t.input_image,
t.detections_text,
t.vision
).collect()生态集成与扩展性
Pixeltable内置支持主流AI服务和模型库:
- LLM服务:OpenAI、Anthropic、Together等
- 视觉模型:Hugging Face Transformers、CLIP、Replicate
- 数据导出:支持导出至pandas DataFrame、PyTorch Dataset,便于与现有ML工具链集成
- 自定义函数:支持用户定义UDF(User Defined Functions),扩展处理能力
配置与性能考虑
关键配置要点:
- API密钥管理:通过环境变量或配置文件管理OpenAI、Anthropic等服务凭证,避免硬编码
- 批处理和异步执行:框架自动处理API速率限制和并发控制,无需手动配置
- 存储后端选择:支持本地文件系统或云存储(S3、GCS),可根据数据量灵活选择
- 增量计算触发:默认仅对新数据或修改数据执行计算,可通过显式刷新全表重新计算
与其他方案的对比
| 维度 | Pixeltable | LangChain | Apache Airflow |
|---|---|---|---|
| 数据建模 | 表格结构,原生多模态 | 链式调用,文本为主 | DAG定义,通用编排 |
| 学习曲线 | 低(SQL-like接口) | 中(链式API) | 高(DAG配置) |
| 版本控制 | 内置自动追踪 | 需手动管理 | 需手动管理 |
| 适用规模 | 中小型AI应用 | 快速原型、演示 | 大规模生产工作流 |
总结
从产品经理的角度看,Pixeltable的核心价值在于降低多模态AI应用的开发门槛。它不是试图替代所有工具,而是在特定场景(多模态数据处理、快速迭代)中提供更高效的抽象。
适合选择Pixeltable的团队特征:
- 需要处理图像、视频、音频等多种数据类型的AI项目
- 频繁迭代模型和处理逻辑,需要快速验证想法
- 希望减少基础设施维护成本,专注于业务逻辑
- 对数据血缘和可重现性有明确要求
需要谨慎的场景:
- 超大规模分布式计算(TB级以上数据),可能需要结合Spark等引擎
- 完全自定义的复杂工作流编排,Airflow可能更灵活
总的来说,如果你的团队正在构建多模态RAG系统或计算机视觉流水线,不妨在下一个项目中尝试Pixeltable。它能显著减少胶水代码,让你把更多精力投入到模型优化和业务创新上。