越来越多的大模型没有你想象那么占空间了,不管是CPU还是GPU都能运行,对于一些小任务,本地搭建的大模型是完全能够胜任的。
传统的云端API方案存在隐私、成本和网络依赖的限制,而本地部署则提供了更多的自主性。
这次我手把手教大家用Ollama框架在Windows系统上部署DeepSeek模型,并通过Cherry Studio搭建个人知识库系统(新手也能轻松搞定)。
这套方案既保证了数据隐私,也避免了重复调用API的成本问题。接下来看实操,跟着我的操作一步一步做你也可以轻松搭建自己的专属本地知识库。
第一阶段:Ollama环境搭建
1. 安装Ollama运行环境
Ollama是一个本地大模型运行框架,支持多种开源模型的快速部署。
访问官方网站:https://ollama.com/
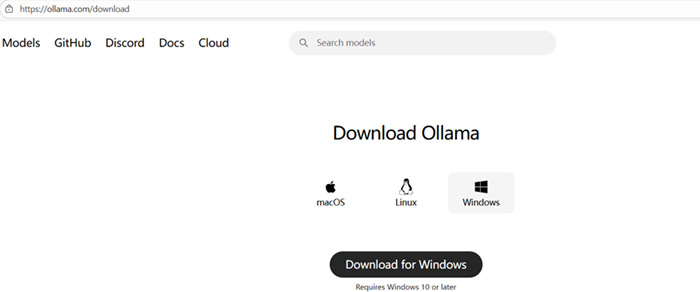
选择Windows版本下载安装程序
运行安装文件,保持默认安装路径(系统会自动配置环境变量)
2. 验证安装成功
安装完成后,需要确认Ollama能正常运行:
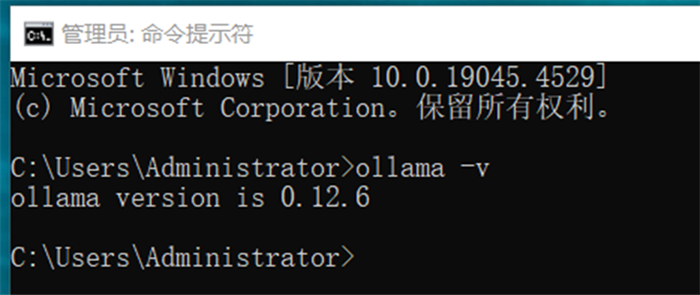
打开Windows命令行终端(CMD或PowerShell)
输入命令:ollama -v
显示版本号即表示安装成功,如:ollama version is 0.x.x
3. 下载DeepSeek模型
根据电脑硬件配置选择合适的模型规格:
访问Ollama官网的Models板块
搜索deepseek-r1,进入模型详情页

选择适配你硬件的版本规格:
1.5B参数版:对标准消费级PC友好,推荐配置为8GB内存及以上
7B参数版:需要12GB+显存,推荐使用独立GPU
32B参数版及以上:专业级硬件要求
我这里选择1.5B的小参数作为测试
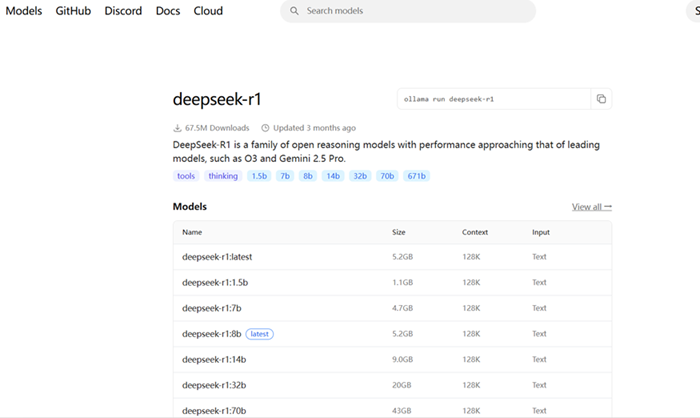
复制对应的运行命令,例如:ollama run deepseek-r1:1.5b
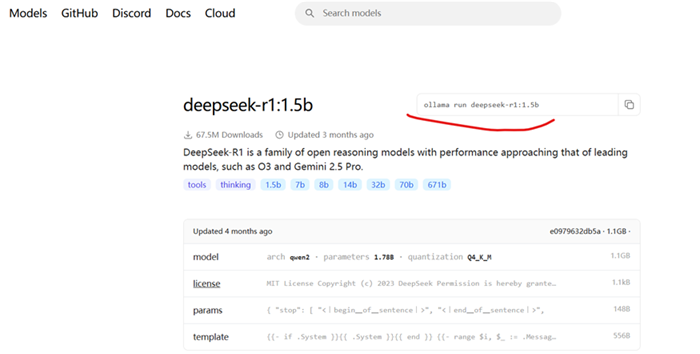
在终端中粘贴并执行命令,Ollama将自动下载模型文件

4. 验证模型下载完成
下载完成后,终端会进入交互式界面:
在>>>提示符后输入任意问题进行测试
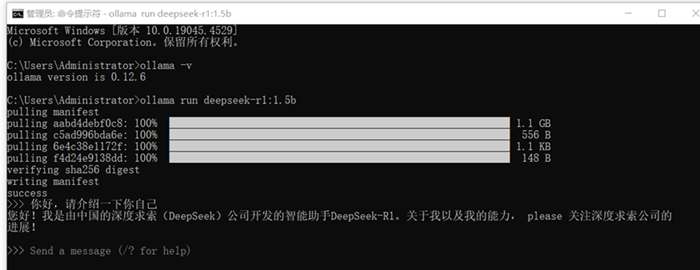
模型成功响应表示部署正常,查看ollama下载了什么模型,模型的占用空间等
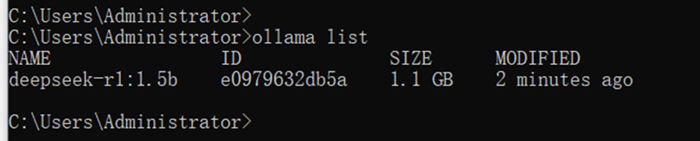
这个时候就可以在命令行与deepseek-r1:1.5b对话

输入exit退出对话界面
重要提示:如果你只需要在本地使用大模型而不需要知识库功能,可以在此阶段停止,Ollama已能独立运行推理任务。
第二阶段:嵌入模型与知识库配置
接下来就是搭建AI知识库,这里需要了解一个概念,那就是嵌入模型
嵌入模型(Embedding Model)是一种将离散数据(如文本、图像、音频等)映射到连续向量空间的技术。通过这种映射,模型能够捕捉数据的语义信息,使得语义相似的内容在向量空间中距离更近,从而实现语义理解和匹配。
嵌入模型的核心工作流程包括以下几个步骤:
-
分词(Tokenization):将输入文本分解为最小单元(如词、子词或字符)。
-
编码(Encoding):将每个单元转化为向量,通常通过预训练语言模型(如Transformer)完成。
-
聚合(Pooling):将句子或段落的所有向量整合为一个统一的表示。
-
归一化(Normalization):将向量标准化,以便在同一尺度空间中进行比较。
以下步骤仅在需要搭建个人知识库时执行
5. 安装词嵌入模型
知识库检索需要将文本转换为向量表示,嵌入模型用于这一转换:
这个时候我们需要回到Ollama官网并搜索:dmeta-embedding-zh
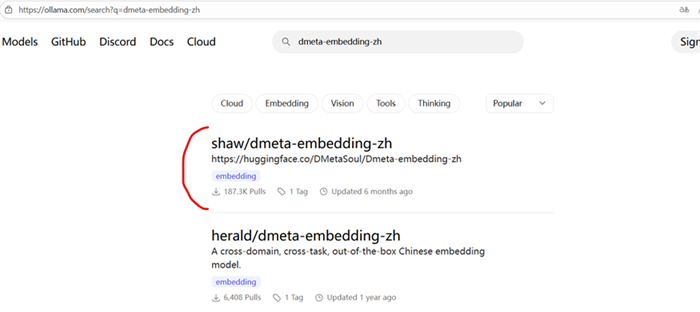
并找到一个嵌入模型,复制命令:ollama pull shaw/dmeta-embedding-zh

回到终端命令行,粘贴执行命令,下载dmeta-embedding-zh
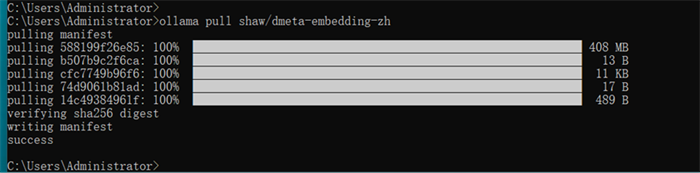
等待下载完成,该模型体积较小,下载较快

下载完成后终端显示完成提示
6. 安装Cherry Studio
上老朋友Cherry Studio,这是是一个开源的本地大模型管理界面,提供了更友好的交互体验:
访问官方网站:https://www.cherry-ai.com/

下载对应Windows版本的客户端
解压或直接运行安装文件
第三阶段:知识库集成与模型配置
7. 连接Ollama模型服务
在Cherry Studio中配置本地部署的模型:
打开Cherry Studio应用,保持Ollama软件在后台运行
点击右上角设置选项
依次进入:模型服务 → Ollama → 管理
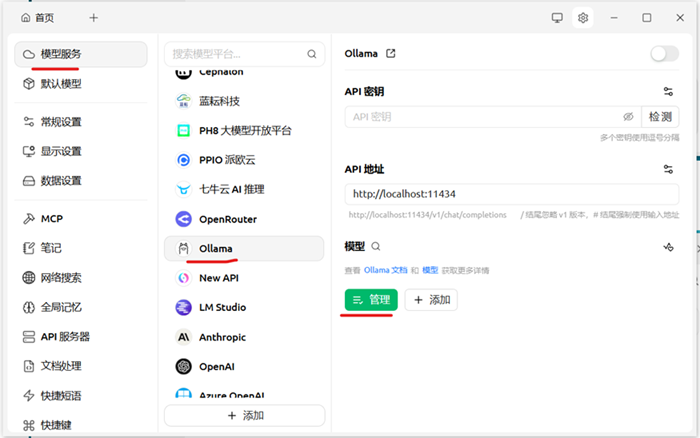
需要同时打开ollama软件,不然不会出现前面下载的deepseek-r1:1.5b大模型
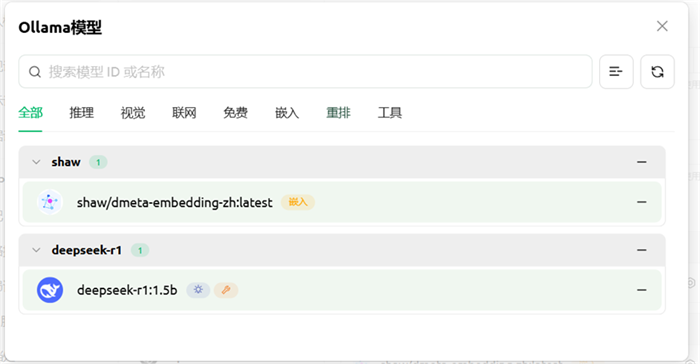
shaw与deepseek-r1 这两个都点击右边的“+”号

系统将自动扫描本地已下载的模型
在两个模型右侧点击"+"按钮进行激活,激活后按钮变为"-"
点击左上角首页返回主界面
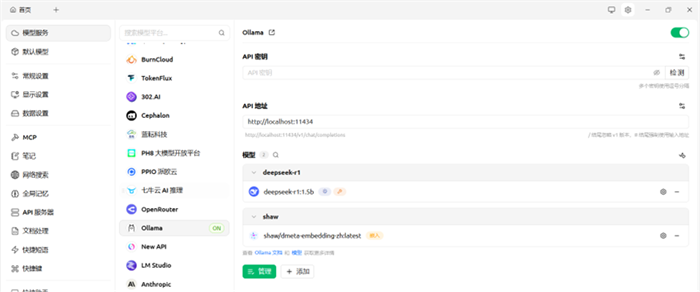
点击GLM-4.5-Flash|智谱开放平台
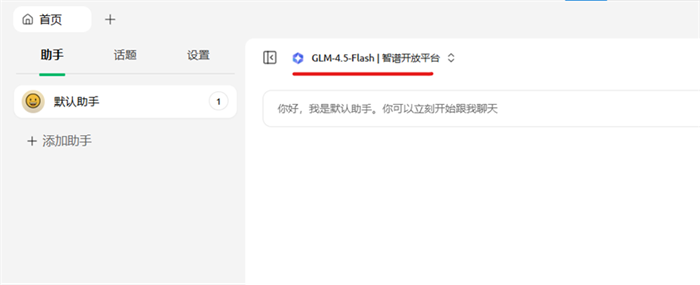
选择deepseek-r1:1.5b
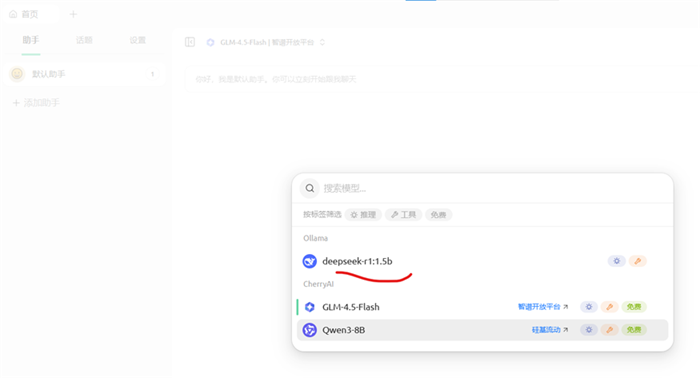
测试deepseek是否能正常对话
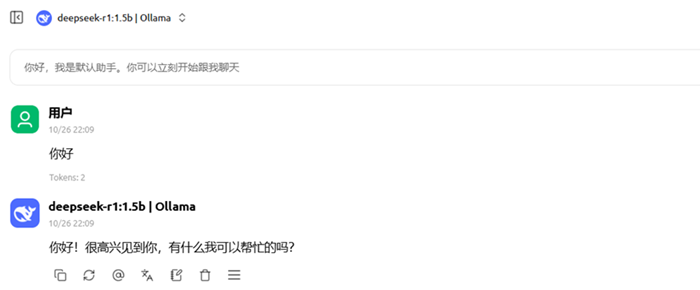
至此大模型对话功能就实现了,你可以直接在本地使用大模型,而且不用连网!
8. 构建个人知识库
接下来正式开始创建你的本地AI知识库
创建知识库用于存储和检索你的私有文档:
在Cherry Studio主界面点击知识库按钮

点击添加知识库

进入添加界面,再点击「+添加」

配置以下信息:
名称:为知识库取一个识别性名称(如"产品文档库""竞品分析库")
嵌入模型:选择shaw/dmeta-embedding-zh(中文语言适配)
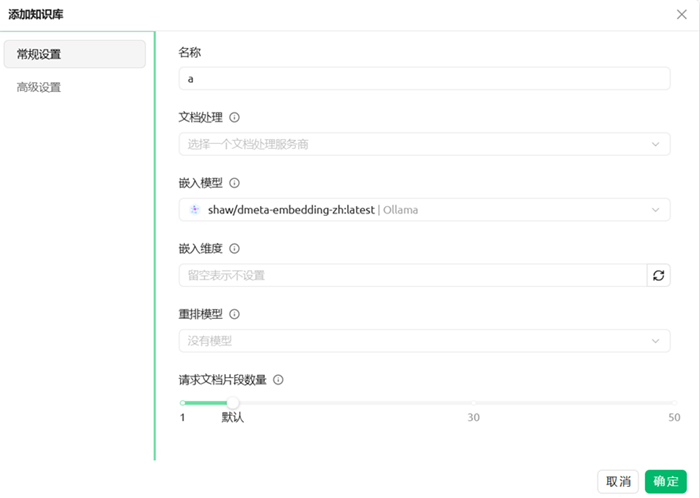
至此知识库的创建完成,但知识库现在还没有资料,所以还需要继续操作
9. 上传文档到知识库
将需要被检索的文档添加到知识库:
在创建的知识库中点击上传文档,选择本地文件(支持PDF、TXT、Markdown等格式),等待处理完成,绿色对勾符号表示上传和向量化成功
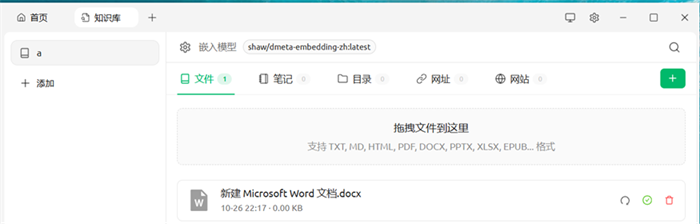
返回首页,在模型选择下拉菜单中选择刚创建的知识库名称

图标亮起,表示知识库选择成功

现在你可以基于知识库内容进行对话查询
备选方案:使用在线大模型API
如果本地硬件不足以运行大参数模型,也可以采用混合方案:
- 本地运行:仅使用本地嵌入模型进行知识库检索
- 云端推理:调用在线大模型API进行对话生成
- 配置方式:在设置中获取第三方API Key(如智谱、OpenAI等),添加到Cherry Studio中即可无缝切换
如果没有API key可以看看苏米之前分享的很多免费白嫖API的文章。
教程|从申请到管理完整配置 Google Gemini API Key 白嫖+无限续命全攻略
白嫖百亿Token!50+顶级大模型一站式调用,claude 4.5、gpt-5、glm-4.6一键适配
免费薅羊毛!Qwen3-Coder 每天2000次额度白嫖攻略
手把手教你如何免费薅 Qwen3 系列大模型 100万Token 额度免费API
总结
通过这套完整的本地部署方案,我实现了对数据的完全自主控制。
相比于纯云端依赖,本地部署的优势在于:无需网络连接即可使用、避免API调用费用、确保文档隐私不外传。
我认为这套方案特别适合以下场景:处理公司内部敏感文档、建设部门知识库、进行长期的本地AI工具实验。
当然,运行一些较大参数的大模型对硬件是有一定要求的,通过GPU调用大模型的速度与CPU运行是有一定差距的。
如果你也在寻找一个不依赖云端、可控且成本透明的大模型方案,不妨按这个流程试试。
下一步我计划探索如何将这个本地知识库系统与自动化工作流结合,敬请期待。