作为产品经理,伴随智能体的研究深入我逐步把数字员工的蓝图打磨一套完善的系统,这套系统分为四个层面来解决企业智能体的整个业务流程。
分别是:应用场景层、核心功能层、基础能力层、硬件与框架层。
真正的差异不是模型参数,而是把这四层和业务深度融合,让智能体像一个可靠的同事,按规则、用工具、带记忆地稳定服役。
先来看一张图:
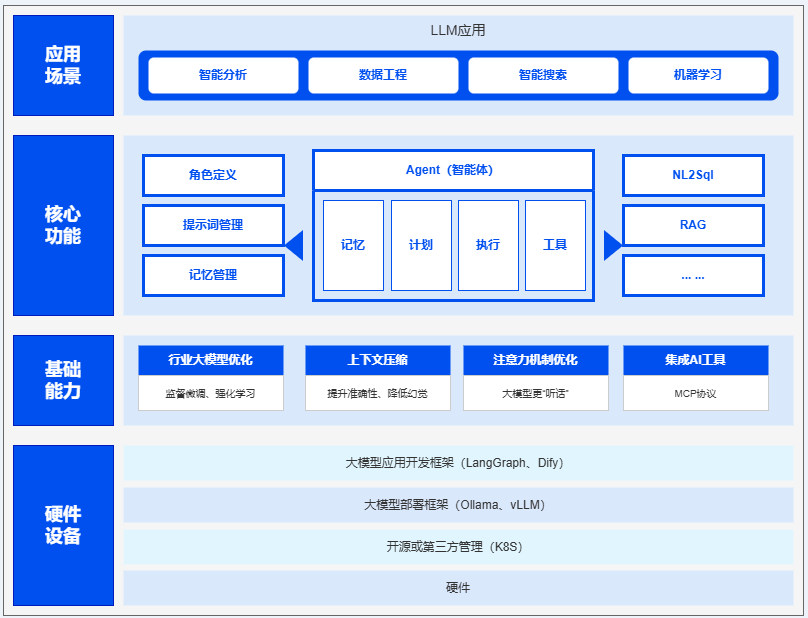
应用场景层:从“能聊”到“能干”的四条前线
业务一线关心的不是模型多聪明,而是它帮我哪儿省时间、降风险、提效率。四条典型战场是:智能分析、数据工程、智能搜索、机器学习。我重点谈“怎么落地”,以及产品经理需要盯的指标和边界。
1. 智能分析:从“人跑数据”到“数据找人”
传统 BI 的使用方式,是人围着数据转;智能体把它倒过来,让“数据主动找人”。当业务问:“为什么本月华北销量下滑?”智能体应能:
- 自动拉取历史趋势,横向对比各大区。
- 关联天气、线下活动、竞品促销、投放波动等外部/内部因素。
- 输出“可读的结论 + 支撑数据”,附上可信度与引用来源,并给出“下月优化建议”。
PM落地方法:
- 维护“问题模板库”:把高频业务问题标准化(如销量下滑、库存异常、转化率突降)。
- 建立“结论溯源规范”:每条结论必须附数据来源与口径说明。
- 设计“建议采纳回路”:建议一键生成行动清单,进入后续跟踪,闭环评估效果。
关键指标:分析生成时间、结论可溯源率、建议被采纳率、复盘周期缩短比例。
2. 数据工程:从“脏活累活”到“智能流水线”
80% 的数据项目时间耗在清洗、对齐口径、补缺失。智能体最适合接管这类“繁琐但有规则”的工作:
- 自动识别脏数据与业务规则冲突。
- 生成标准化清洗脚本与可读计划,人审阅后上线。
- 将每次调整沉淀为复用规则,减少重复劳动。
PM落地方法:
- 引入“Human-in-the-loop”:高风险变更需要人工复核与回滚预案。
- 建立“规则版本库”:清洗规则可版本化、可追溯、可灰度发布。
- 把工程师从“保洁员”解放为“架构师”:时间转向语义层、指标体系与数据产品设计。
关键指标:工时节省比例、数据错误率/回滚率、规则复用率。
3. 智能搜索:从“关键词链接”到“可执行的答案”
企业搜索不应该停留在“给链接”。基于 RAG(检索增强生成),智能体先检索,再读懂、总结、重组,输出有引用的可执行答案。例如 HR 问试用期离职补偿,答案应:
- 结合当前日期、地区与公司制度,给出具体结论。
- 清晰列出参考条款:制度与法规的具体条目。
- 一键生成标准说明邮件或办理流程。
PM落地方法:
- 构建“知识分层”:制度、流程、FAQ、案例分层管理,提升检索精准度。
- 设置“引用门槛”:无充分引用不出结论,优先提示信息不足与补充路径。
- 对答案可执行性做评审:模板、流程按钮直达工具。
关键指标:一次到答率、引用覆盖率与点击率、幻觉率、从问题到办理的端到端时长。
4. 机器学习:从“专家游戏”到“民主化协作”
过去 ML 项目是算法工程师的闭门游戏。智能体介入后,业务可以用自然语言描述规则,智能体翻译为特征与约束,算法侧自动生成特征工程代码、调参建议、实验记录与报告。
PM落地方法:
- 搭建“智能白板”:业务-算法共同工作空间,决策与假设透明记录。
- 引入语义层与特征库:避免 NL2SQL 或特征选择的隐性口径偏差。
- 形成“实验档案”:每次迭代都有可对比的证据链。
关键指标:从需求到上线时长、实验可复现实验、业务参与度、模型上线后的业务指标提升。
核心功能层:数字员工的大脑与神经系统
这一层回答“它是怎么做到的”。一个能上岗的智能体,必须有灵魂、会思考、能学习。
1. 灵魂注入:角色定义与提示词管理
从聊天机器人到数字员工的第一步,是明确角色与边界:
- 角色与受众:你是谁,面对谁。
- 规则与红线:合规要求、对外话术、不能编造。
- 不确定策略:信息不足时,明确说不知道、主动追问。
PM实操:把提示词工程做成“可管理系统”:模块化(角色、语气、格式)、版本化、A/B 测试、行为手册沉淀。
2. 感知—规划—执行:让智能体像员工一样工作
智能体的工作循环:
- 感知:理解任务与上下文。
- 规划:拆解步骤、设定完成标准与优先级。
- 执行:调用工具、生成中间结果、进行自我反思并迭代。
把它想象成有三样东西的员工:任务清单、工具腰带、工作日志。
PM实操:为每类任务定义 SOP、异常处理策略与“人工接管”阈值;所有工具调用留审计日志,便于回溯与优化。
3. 记忆管理:短期与长期,让智能体越做越熟
- 短期记忆:会话级上下文,保证任务内不忘前文。
- 长期记忆:跨任务经验与用户偏好,如客户历史问题、接口稳定性提醒。
PM实操:为记忆做隐私分级(个人/团队/全局)、过期策略与污染防治;让记忆成为可治理的数据资产,而非隐性黑盒。
4. 两大赋能利器:RAG 与 NL2SQL
- RAG:先查再答,答案来自企业知识库,引用可查,显著降低幻觉。
- NL2SQL:把自然语言翻译成 SQL,再把结果翻译成可读解释与图表,让人人用母语和数据库对话。
PM实操:为 NL2SQL 配语义层与口径治理,要求澄清关键条件再查询;为 RAG设“引用阈值”,不足则提示补充信息。
基础能力层:让智能体“靠谱、专业、能干”
1. 专业化培训:用 SFT 与 RL 把通用模型变行业专家
- 监督微调(SFT):用行业专家标注的高质量数据训练表达方式与解决方案。
- 强化学习(RL):训练偏好与价值观:合规优先、风险保守、不确定提示人工复核。
PM实操:搭数据与标注治理;把行业红线与合规策略产品化,进入模型偏好;明确训练数据“能与不能”。
2. 可靠性保障:上下文压缩与注意力优化
- 上下文压缩:对长文档做摘要与结构化抽取,只喂关键信息。
- 注意力优化:提示聚焦当前问题所需信息,信息不足优先追问与标注不确定。
业务效果:更“听话”、更“有分寸”。
3. 能力扩展:集成企业工具,MCP 做统一插座
- 接入内部 API、检索服务、文件系统、工作流引擎等,智能体从“会说”变“会做”。
- 用 MCP 等协议统一工具接入标准,减少重复对接,聚焦权限与流程设计。
PM实操:设计最小权限与幂等性、审计日志、回滚机制与“四眼原则”(关键操作需人确认)。
硬件与框架层:数字员工的“身体”与“孵化器”
1. 快速成型:选对开发框架
- LangGraph:复杂、有状态、多 Agent 协作与长流程任务,图式状态机便于可视化与调试。
- Dify:面向业务与产品的低代码装配平台,提示管理、RAG 配置、工具集成可视化,适合快速试错与 PoC。
选型经验:长期演进走 LangGraph;快速验证走 Dify。两者可组合,先原型后工程化。
2. 高效服役:模型部署与流量管理
- Ollama:本地化、轻量化试炼场,适合开发阶段与内网快速迭代。
- vLLM:生产级并发性能引擎,优化吞吐、延迟与显存,适合多模型多租户在线推理。
PM关注:流量路由(大小模型分层)、结果缓存与复用、批处理策略,成本与体验两手抓。
3. 规模化基础:K8s 与硬件
- K8s:弹性伸缩与编排,灰度发布、滚动升级与跨环境迁移。
- GPU集群:在线推理与离线微调分池管理;成本控制策略(何时用大模型/小模型/缓存)。
加一层观测:建立“LLM 可观测性”:请求量、token 成本、延迟、质量指标(准确率、引用完整率、行动成功率),才能运营而非祈祷。
路线与角色:从试点到规模的产品方法
我们正在经历从“对话式 AI”到“智能体驱动业务”的范式转移。作为产品经理,我更关心如何一步步做大做稳。
三步走路线
- PoC:选 1-2 条价值明确的场景(如智能搜索+RAG),验证可行性与用户接受度。
- 试点:把 SOP、权限、审计、观测补齐,形成闭环指标与复盘机制。
- 平台化:统一工具插座、提示词版本库、知识分层、语义层与记忆治理,上线为企业级能力。
角色行动清单
- 决策者:用四层架构规划,不买“一个模型”,而是建设“一个系统”。从场景试点牵引技术与基础设施,而非反过来。
- 创业者:在基础能力层与核心功能层寻找确定性机会:更易用的 RAG、NL2SQL、工具集成;深耕垂直行业的 Agent 产品。算力大战不适合多数团队。
- 开发者:别停留在 Prompt 与 API;深耕感知-规划-执行、记忆/RAG/NL2SQL 模块与工程化落地,熟练掌握 LangGraph、Dify,做可维护、可演进系统。
- 产品经理:把智能体当同事来设计——角色、边界、SOP、风控、指标与复盘;推进知识与数据的产品化治理;建立“AI 运营”职能,持续优化提示、工具与流量成本。
结语
这场革命的本质,不是某个模型的版本号,而是你能否用软件架构的思维,把 AI 的能力系统化、工程化地注入业务的每一处毛细血管。
作为产品经理,我学到的最大教训是:少做“好看的聊天窗”,多做“能上岗的数字员工”。
当智能体拥有角色与边界、会规划与执行、能记忆与学习,并在企业级的框架里稳定运行,它才会从一时的热闹,变成长期的生产力。