次更新不仅在推理能力、代码编写、中文写作等方面实现了全面提升,更是在 Web 前端开发领域碾压Claude,剑指GPT-4.5!
推理任务增强
新版 V3 模型借鉴 DeepSeek-R1 模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过 GPT-4.5 的得分成绩。
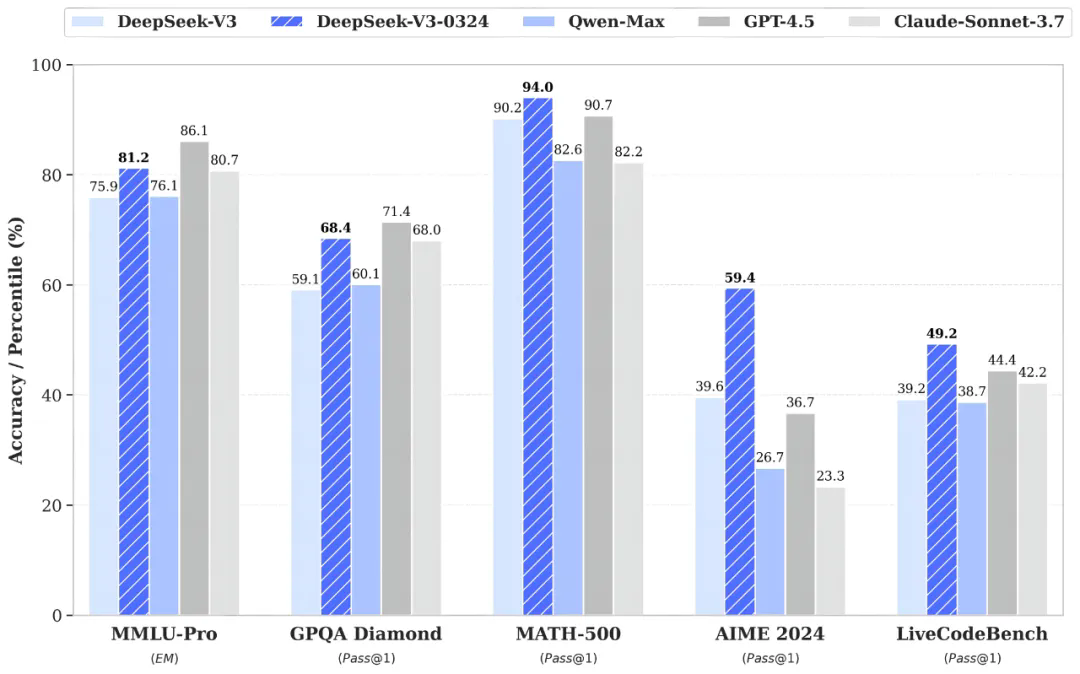
美国数学邀请赛 (AIME): DeepSeek V3 在该测试中进步最为显著,展现了其强大的数学推理能力。
LiveCodeBench: 这是一个评估模型编写、理解和调试代码能力的基准。DeepSeek V3 在此项测试中的表现预示着其代码理解和生成能力的提升。
MMLU-Pro: MMLU 测试模型在多个学科(人文、社会科学等)的知识和推理能力。DeepSeek V3 的进步表明其知识面和跨学科推理能力得到了增强。
GPQA: GPQA 是通用问答基准,用于评估模型在开放性或多样性问题上的表现。DeepSeek V3 的提升意味着它在处理更复杂、更开放式问题时将更加得心应手。
代码能力飞跃
中文模型一直在代码能力上一直与Claude相去甚远,这次代码编写能力可以说是有质的飞跃,尤其是前端开发。这一点与目前最新的Claude 3.7 Sonnet 非常相似。主要体现在代码准确率的提升,以及模型本身审美的提升。

上图由deepseek生成
SVG生成提示词
提示词太长,苏米把提示词放到公众号下载,可通过关注《苏米客》公众号,回复“提示词”获得。

在前端代码上,新版 V3 模型生成的代码可用性更高,视觉效果也更加美观、富有设计感。苏米测试生成了一个手机UI原型测试了一下。

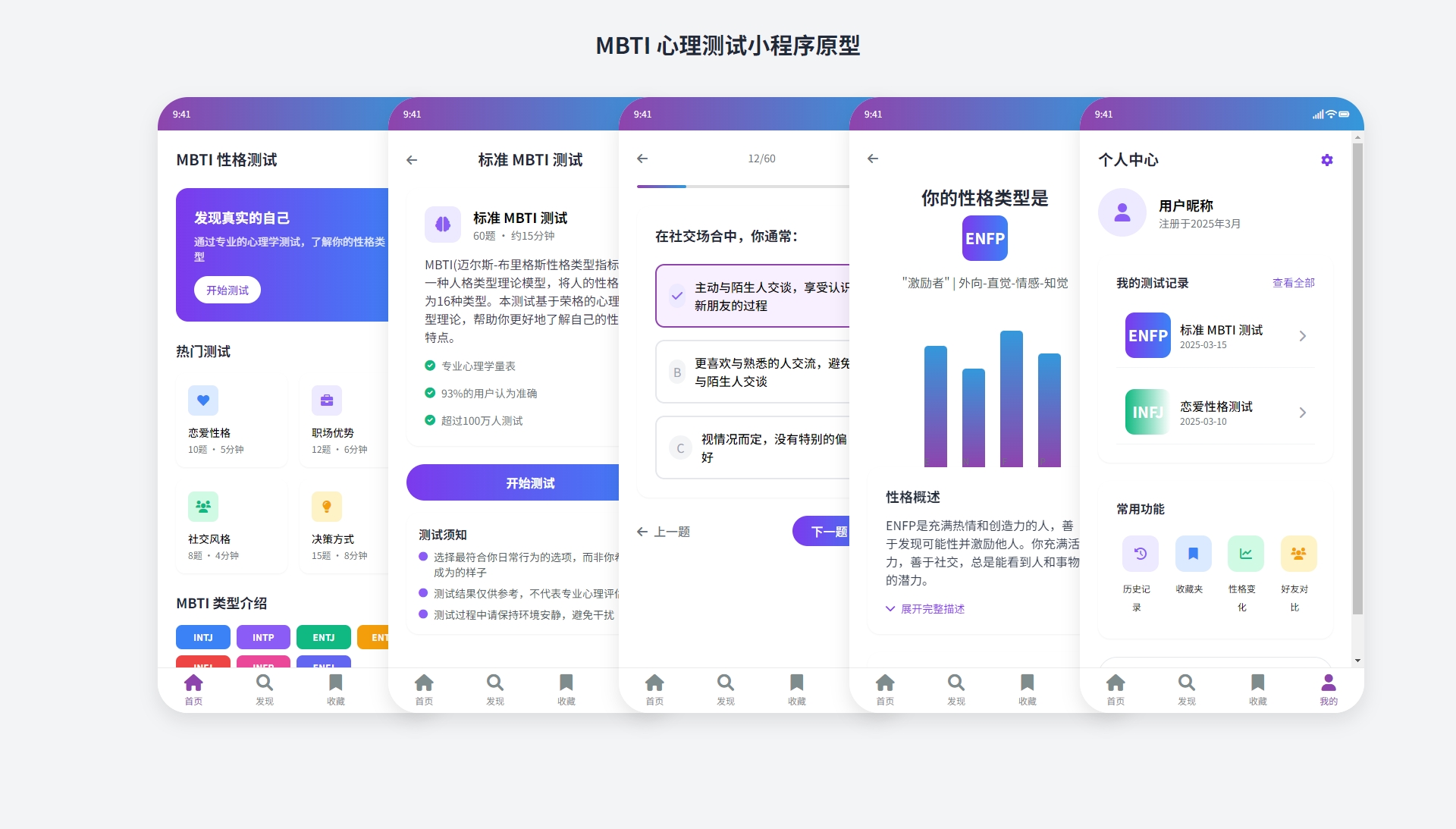
上图由deepseek生成的原型界面
原型生成提示词
提示词太长,苏米把提示词放到公众号下载,可通过关注《苏米客》公众号,回复“提示词”获得。
中文写作能力
DeepSeek作为优秀中文大语言模型,在中文写作能力上是毋庸置疑的,此次升级更是对中文写作的风格和内容进行了优化,风格和 DeepSeek-R1 对齐,内容主要是中长篇写作质量的提升。

上下滑动查看完整内容
功能增强方面有三点:多轮交互改写能力提升(上下文);翻译质量和书信类写作的优化;中文搜索能力的优化。
模型开源
DeepSeek-V3-0324 与之前的 DeepSeek-V3 使用同样的 base 模型,仅改进了后训练方法。私有化部署时只需要更新 checkpoint 和 tokenizer_config.json(tool calls 相关变动)。模型参数约 660B,开源版本上下文长度为 128K(网页端、App 和 API 提供 64K 上下文)。V3-0324 模型权重下载请参考:
Model Scope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3-0324
Huggingface:
总结
就在更新之后不久,苏米已经在各大博主的分享中看到了非常多关于这几项升级后的能力测试,从技术角度看,它代表了中国AI代码编程技术的又一次跃升;从应用角度看,它预示着中文内容创作领域的又一次降维打击。这是国外一众AI大模型无法企及的。