上个月他们开源的 GLM-4.1V-Thinking 刚冲上 HuggingFace Trending 第一,下载量破 13 万。
结果上周又不手软,直接丢出 GLM-4.5 和轻量版 GLM-4.5-Air。
我本以为这已经是终点,结果人家又整了个更猛的来了:GLM-4.5V。

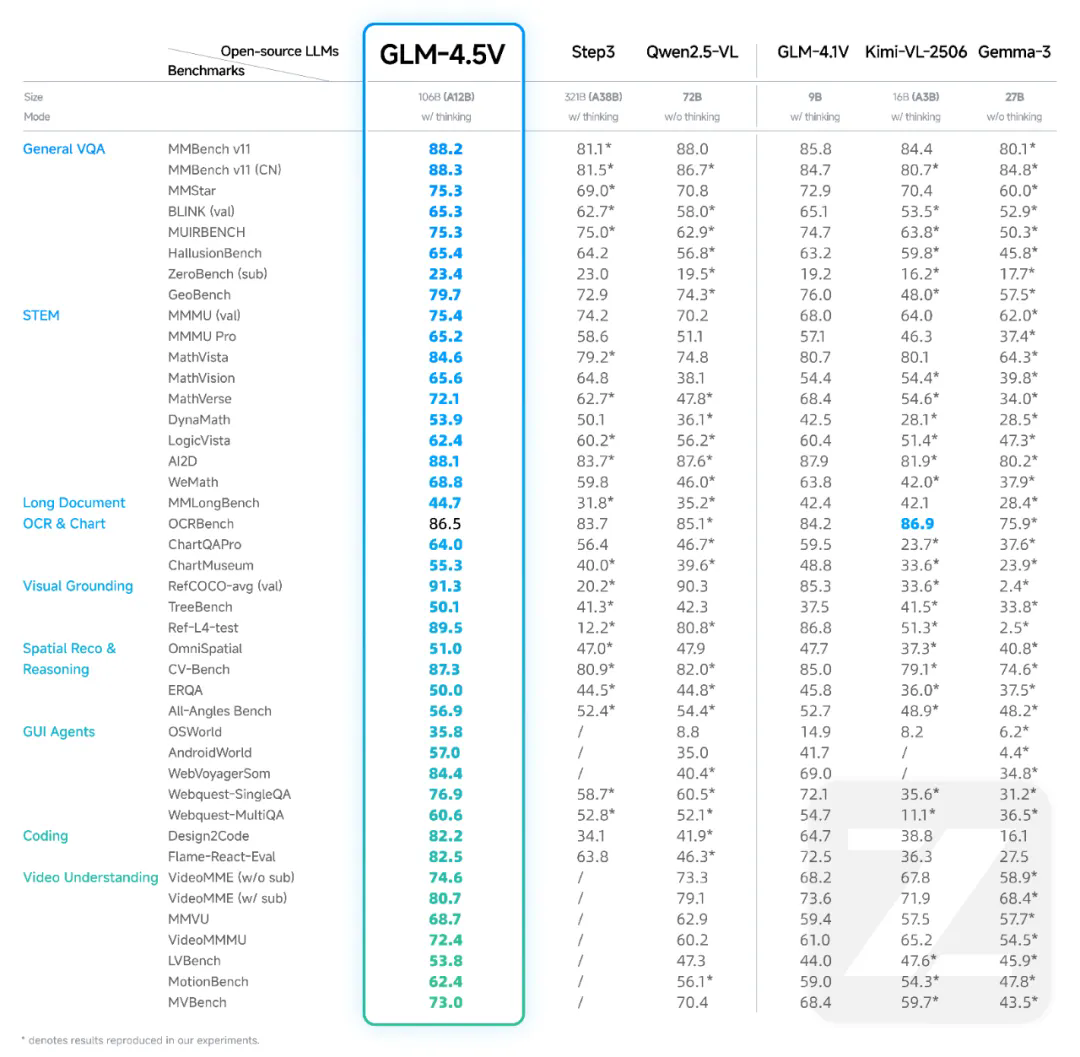
它基于 GLM-4.5-Air 升级视觉能力,42 个榜单里拿了 41 个 SOTA,成为全球 100B 级最强的开源视觉推理模型(参数 106B,激活 12B)。
而且没搞什么“商业授权+注册排队”这一套,直接开源,GitHub 和 Hugging Face 都能下。
GitHub: https://github.com/zai-org/GLM-V
Hugging Face: https://huggingface.co/zai-org/GLM-4.5V
他们还贴心开源了一个桌面小助手,可以接入 GLM-4.5V,通过截屏、录屏直接理解你的屏幕内容,做成你自己的多模态助手。
我实际体验了几个场景
我直接找了几个日常场景试试,看它是不是真有传说中那么强。
① 猜车型 我在小红书上找到了一个猜车的图片,反正我是猜不出来,结果GLM-4.5V很快就识别出车的品牌和车型。

② 猜地点 还是在小某书上找了一张不知道位置的摄影照片,我发给GLM-4.5V问它:猜猜照片这是哪里,以及拍摄这张照片所在的位置。
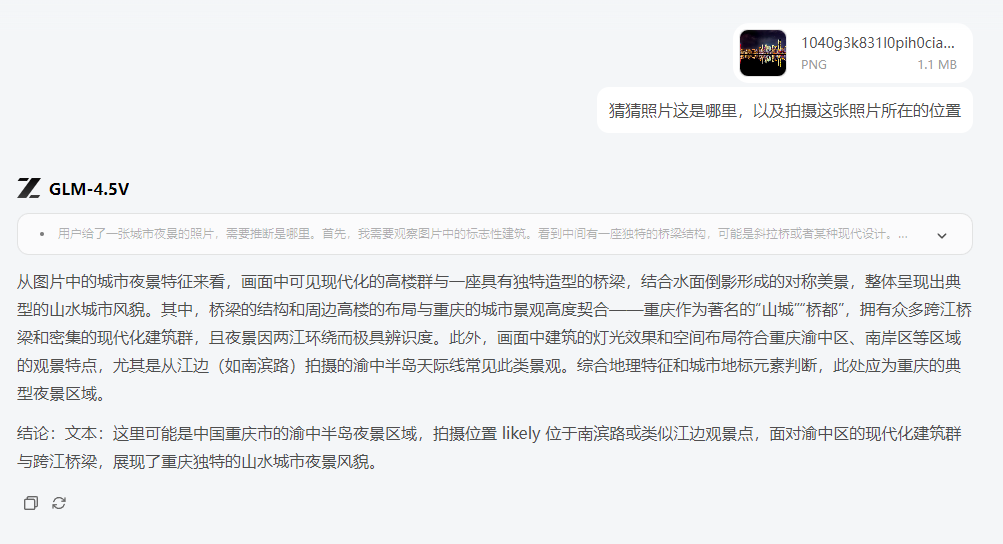
很快就给出了位置信息和拍摄地点:中国重庆市的渝中半岛夜景区域,拍摄位置 likely 位于南滨路或类似江边观景点
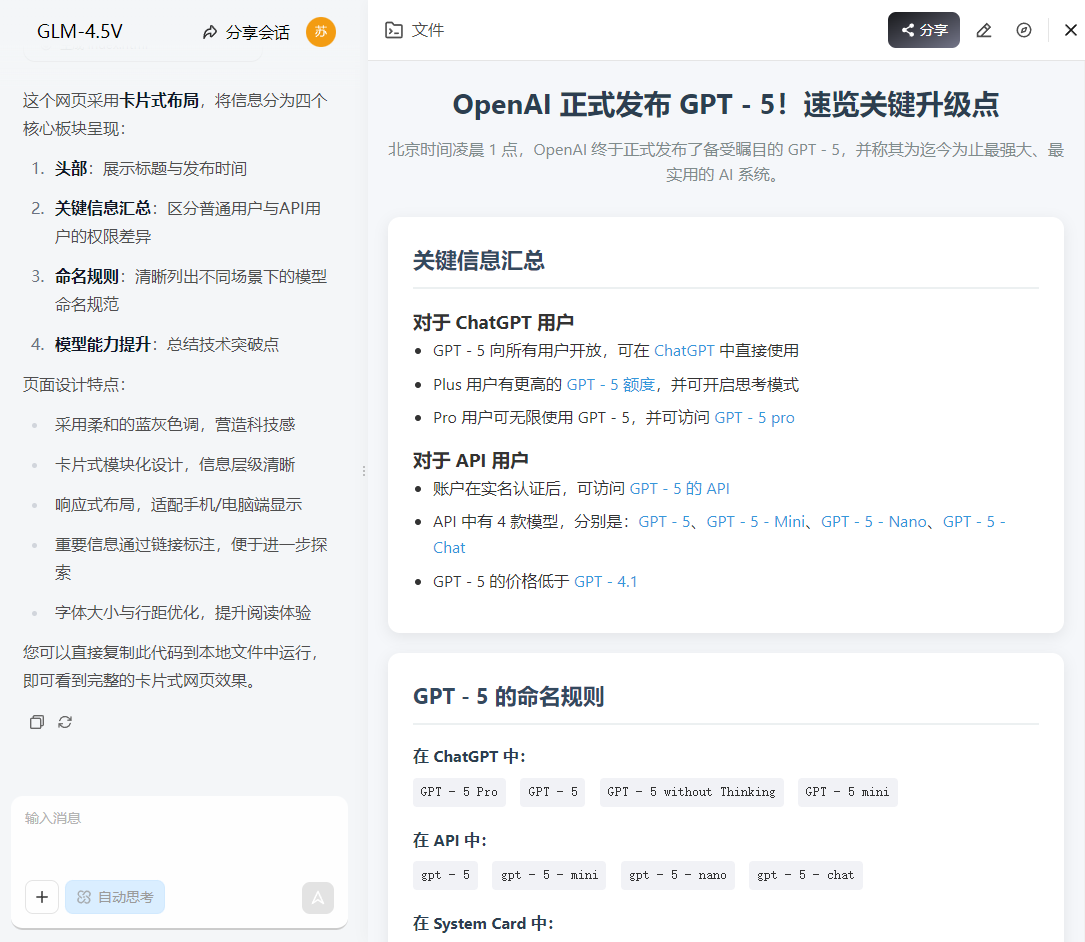
③ 从图片生成网站 发给它一张我写过的文章 Markdown 格式内容的图片,让它直接生成了一个美观的 HTML 网页。
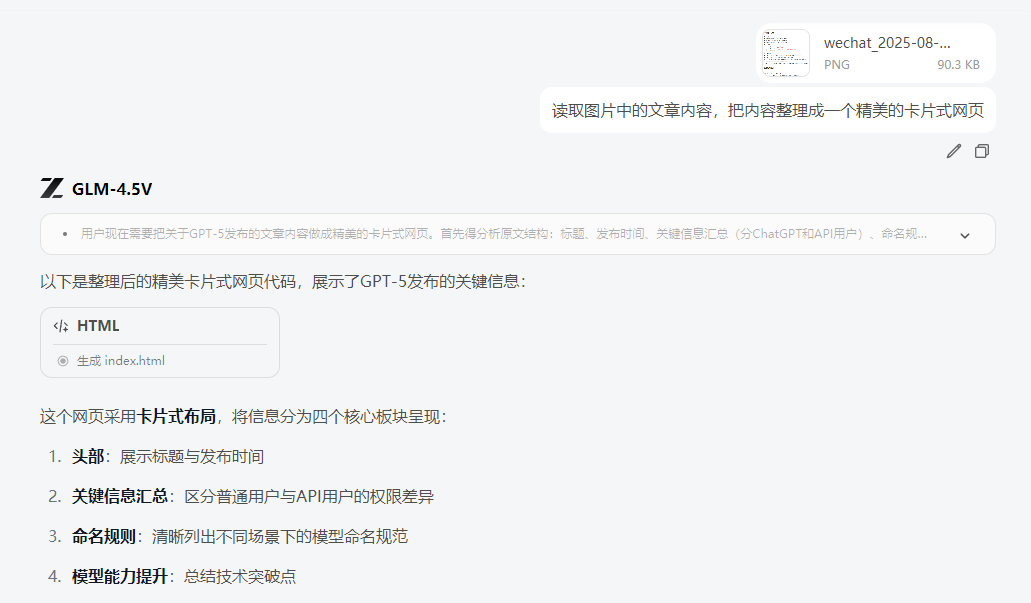
别说,排版确实是符合预期的,只是缺少一点风格。
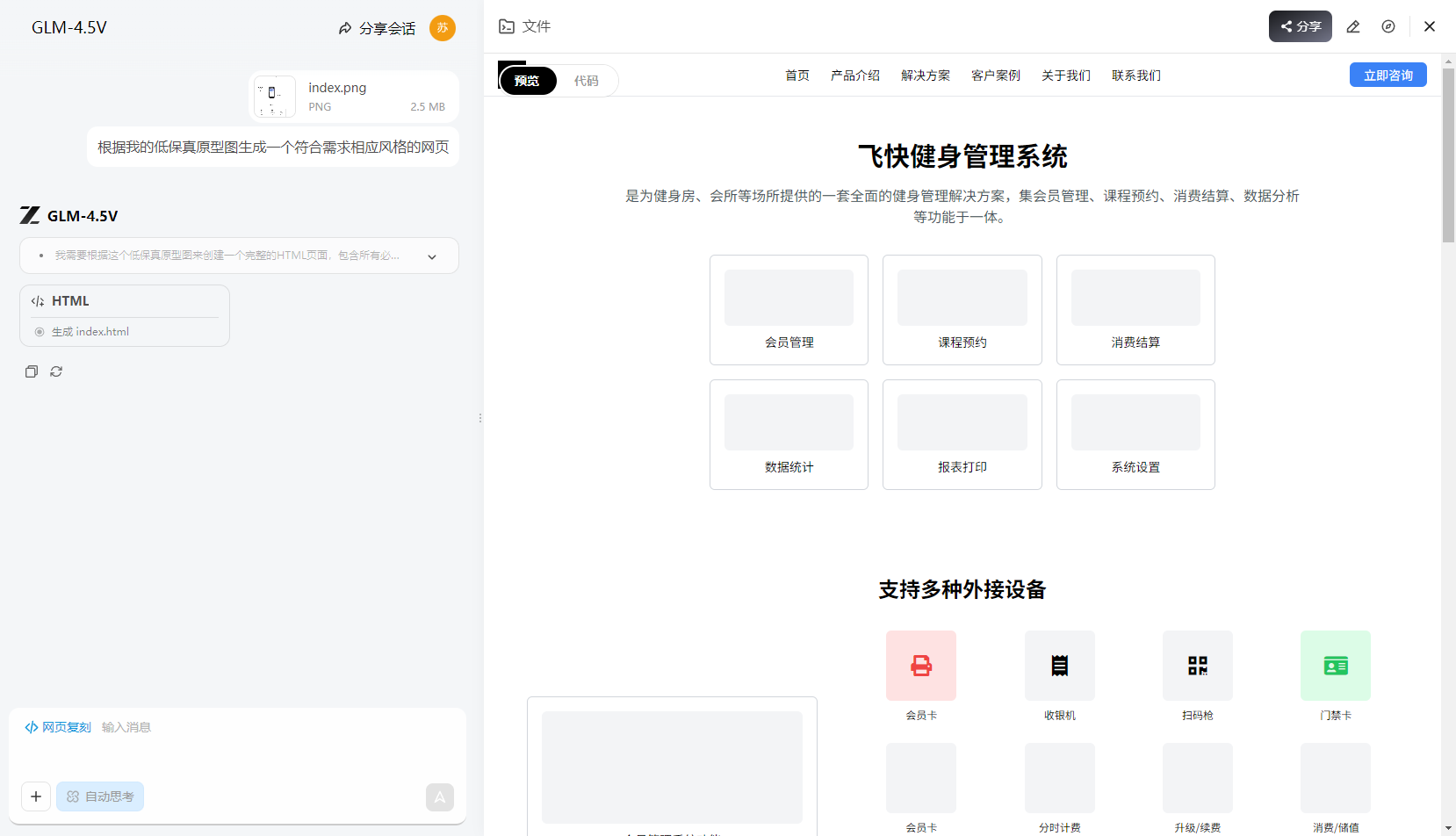
④原型图复刻 日常工作最多的就是原型图了,把原型图直接扔给GLM-4.5V,我用一个我做好的低保真原型图让它直接生成前端 HTML 代码,不得不说,还挺符合要求的。
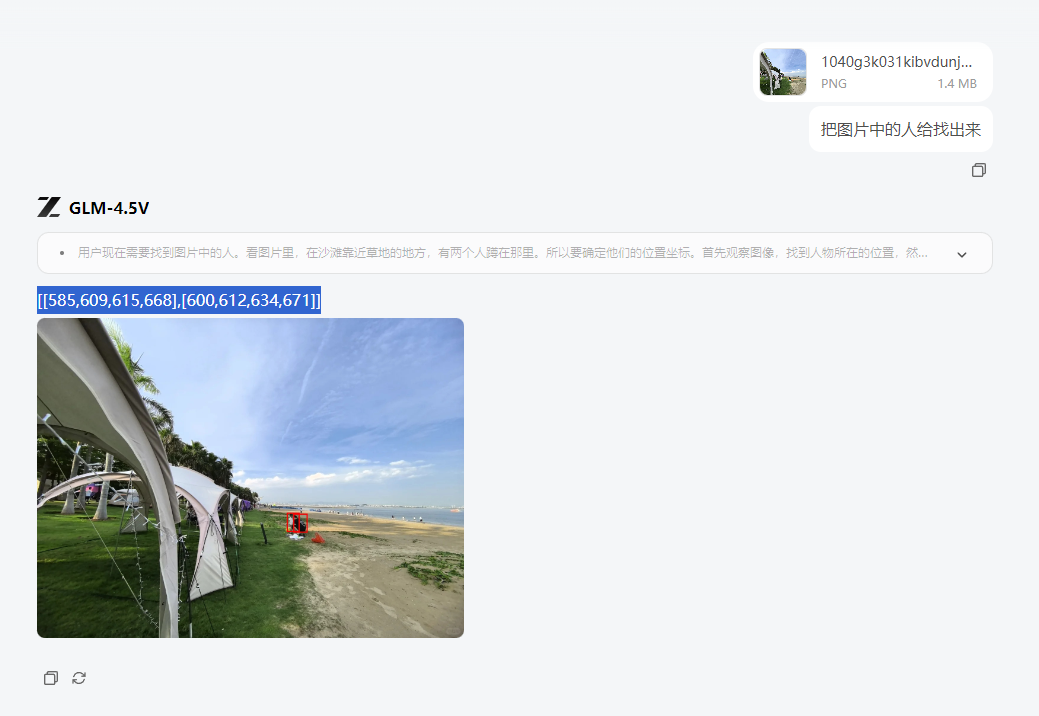
⑥ 圈出特定物体 我找了一张在海边的图片,让它找出图片里的人给找出来,虽然图片中的人物很小,但它不仅给了坐标,还圈出了标注图片。
我觉得它厉害的地方
GLM-4.5V 不只是多模态识别能力强,它更像是能把“看、听、读”融在一起思考的 AI。
无论是图像推理、视频理解、GUI 操作,还是复杂图表和长文档解析,它的表现都非常稳。
这种“通感”式的 AI,是往真正智能方向迈出的一大步。对于开发者来说,它已经能做出很多实用落地的功能,不是实验室里的花架子。
在线体验地址:https://chat.z.ai
桌面助手开源版:https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
我的总结
如果你对 AI 多模态感兴趣,这个模型几乎是必试的。 它开源、能力全、落地快,而且是真正能帮你干活的那种工具,不只是用来刷榜单。 我觉得未来半年会有一波基于 GLM-4.5V 的新应用涌出来,谁先玩转它,谁就能吃到第一波红利。