最近在 X 上刷到一篇很火的帖子,作者 Rahul 是 NicheTrafficKit 的创始人,长期关注 AI 领域和产品构建。这篇帖子标题是「Loops: What Every AI Engineer Needs to Know in 2026」,发布才几天阅读量就超过 250 万,在 AI 圈子里讨论得很热烈。
文章的开始提到了两位行业顶尖 AI 工程师几乎在同一时间说的意思完全相同的话。
Peter Steinberger,OpenClaw 创建者,现在在 OpenAI 工作:
"You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."
Boris Cherny,Anthropic 旗下 Claude Code 负责人:
"I don't prompt Claude anymore. I have loops running that prompt Claude and figure out what to do. My job is to write loops."
两个大佬一致的判断,让很多人开始思考:这到底是什么意思?
我是循环中的一环
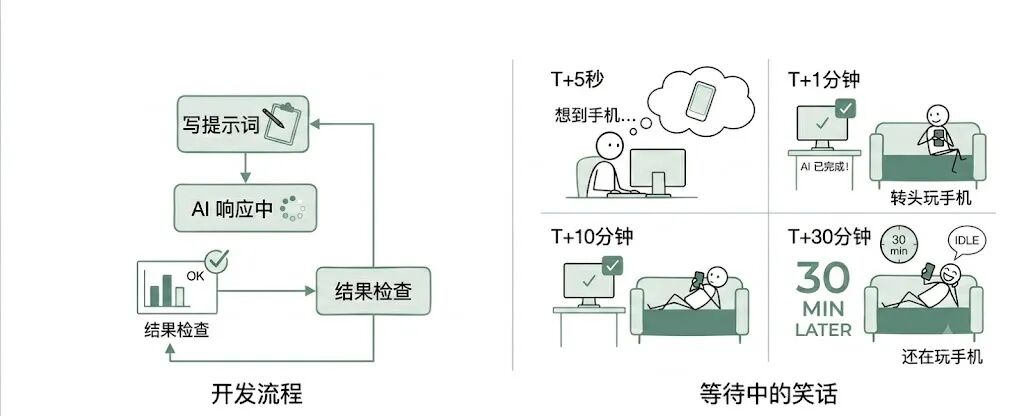
看到这个论述,深有体会。在 AI 开发的过程中,大多数人的流程是:写提示词 → 等待 AI 响应 → 查看测试结果 → 继续下一个提示词。
一个笑话:多数等待 AI 响应过程中,你可能玩手机,AI 已经结束了,半个小时过去了,你还在玩手机。
循环需要成本
循环听起来美好,但实际跑起来才发现,Token 成本是个大问题。这也是没人愿意提前说的隐藏门槛。
一个单 Agent 循环跑一个中等编程任务,需要消耗 5 万到 20 万个 Token。一个编排器带三个专业 Agent 的舰队循环,Token 消耗量会达到 50 万到 200 万。如果是每天定时运行的循环,一周下来就是几百万 Token。
按照传统的 API 定价,一周认真做循环工程的花费,可能比大多数人一个月的 AI 预算还要多。这就是为什么 Peter 那篇帖子下面,很多人会评论"说得轻松,你又有无限额度"。
他们说得没错,在普通预算下做循环工程,成本很容易失控。每次重试、每次自我纠错、每个子 Agent、每轮验证都要花钱。开放式探索的开放循环,烧 Token 的速度快到让人睁不开眼睛。
所以说,循环不难设计,难的是烧不起。
Rahul 认为,现在中国的大模型解决了这个经济可行性问题。像 DeepSeek、Kimi、MiniMax 这些模型,让 Agent 循环在普通人的预算下也能跑起来。
而 DeepSeek V4,是目前跑大规模循环最便宜的前沿模型之一。它的优势很明显:
- 1M 上下文窗口
- 384K 最大输出
- DeepSeek V4 Flash + Pro 双模型
- 极低的 Token 定价
- 支持工具调用和 JSON 输出
- Flash 版本支持高达 2500 并发请求
为什么 1M 上下文窗口这么重要?因为循环需要记忆。一个跑在大项目上的编程循环,需要同时记住之前的运行结果、当前错误、架构文档、测试结果和代码库上下文。大多数模型跑到一半就会丢失上下文,循环开始忘记之前发生的事情。DeepSeek 能装下更多上下文,所以长时间运行的循环也能保持连贯性。加上定价极低,循环终于不会让人破产了。
旧方式 vs 新方式
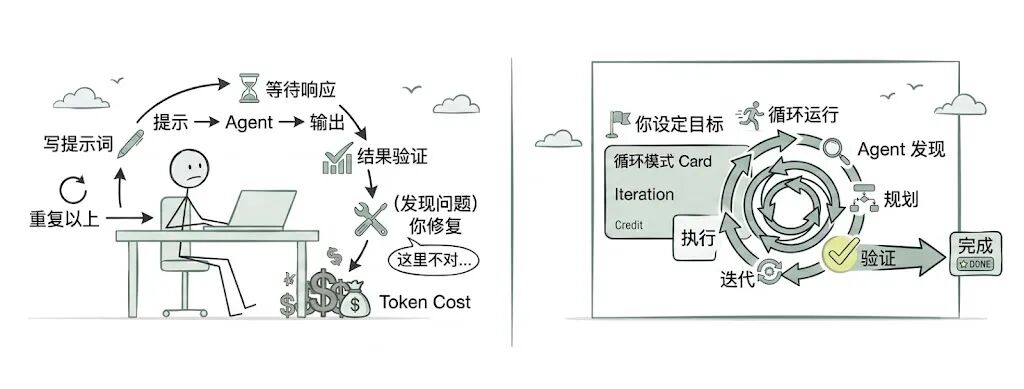
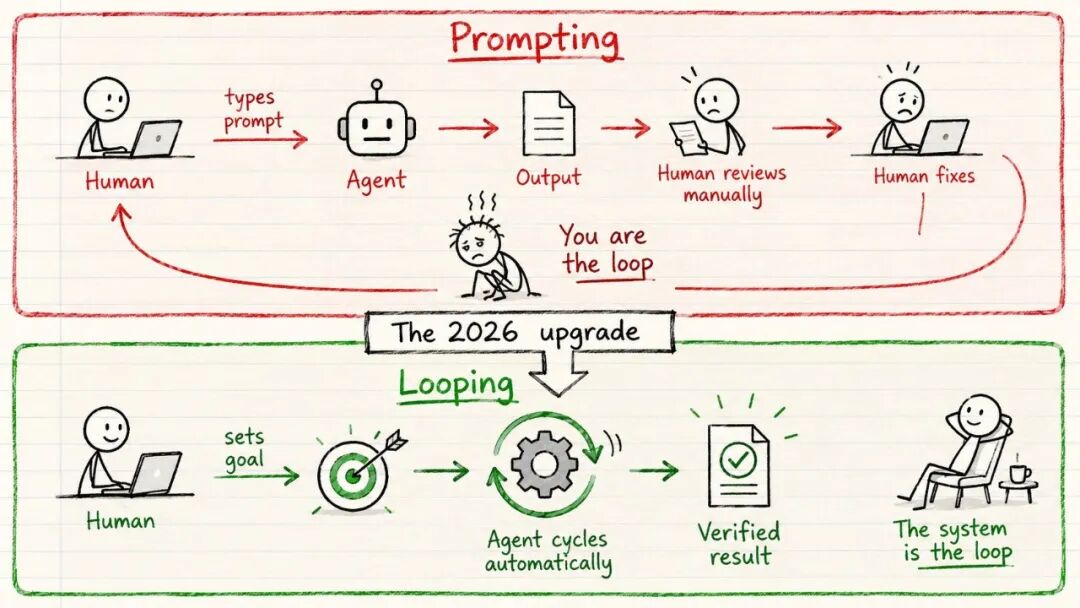
以前一直都是一次一个任务地提示 Agent。你输入 Prompt,Agent 回复,你审核,修复错误,再提示一遍。你自己就是那个循环。
现在这个模式正在改变。不再需要你一步步驱动 Agent 完成任务,而是设置一个循环,让它自己完成发现、规划、执行、验证、迭代,直到目标达成。
旧的提示模式:你 → 提示 → Agent → 输出 → 你审核 → 你修复 → 重复
新的循环模式:你设定目标 → 循环运行 → Agent 发现 → 规划 → 执行 → 验证 → 迭代 → 完成
你不再需要一步步提示,Agent 会替你重复这个循环。一个 Prompt 给 Agent 指令,一个循环给 Agent 一份完整的工作。
什么是循环工程
循环工程就是设计可重复反馈循环的实践,引导 AI Agent 从尝试到获得验证结果,整个过程不需要持续人工干预。
循环是你搭建好的装置,几乎任何 Agent 框架都能运行,区别只在于你怎么连接。最简单的情况,一个 Agent 自己改进自己:研究 → 打草稿 → 对照目标检查 → 修复薄弱环节 → 再次循环直到满足要求。
不管循环简单还是复杂,都会经历五个相同的阶段:
发现 → 规划 → 执行 → 验证 → 迭代
通过验证就交付,没通过就再来一圈。核心思想就这么多。
单 Agent vs 舰队
循环有两种规模。
单 Agent 循环,就是一个 Agent 自己跑完整个流程。就像一个人反复修改自己的稿子,自己发现需求、规划工作、执行、验证质量、有问题就迭代。适合专注任务、简单目标、范围有限的工作。一个大脑,一个循环,自我改进。
舰队循环是更大规模的玩法。你给编排器 Agent 一个目标,它把目标拆成小块,分给专业 Agent,专业 Agent 再把更细的工作分给自己的子 Agent。整棵树上的每个 Agent 都在不断跑发现、规划、执行、验证,直到目标达成,就像一整个团队端到端运行项目。
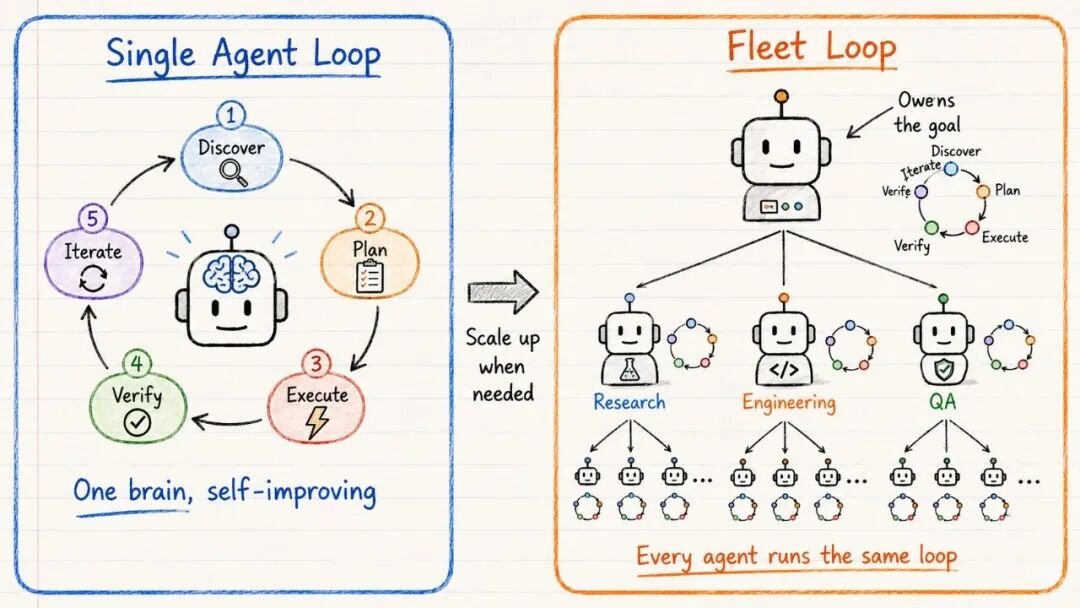
典型结构如下:
- 编排器(掌握使命)
- 研究专家 → 网页研究员
- 工程专家 → 代码编写者 + 调试者
- QA 专家 → 测试编写者 + 缺陷追踪者
树上的每个 Agent 都跑同样的五阶段循环:发现 → 规划 → 执行 → 验证 → 迭代。
关键区别在于,单 Agent 循环像一个人改自己的稿子,舰队循环像一整个团队端到端跑项目。
开放循环 vs 封闭循环
Rahul 认为,这是 2026 年最重要的实践区分。不是所有循环都一样,主要分两类。
开放循环是探索式的,活动空间很大。你给 Agent 一个目标,让它自由探索,它可以尝试不同路径,发现新东西,产出你没有完整定义的成果。这是最令人兴奋的方向,也是 OpenAI 现在在做的事情。但缺点是 Token 消耗非常大,对于 90% 没有无限 API 预算的人来说,目前还不实用。如果指向标准松散的项目,很容易变成垃圾生产机器,特点就是快、乱、贵。
封闭循环是有边界的,人先设计好端到端路径。目标清晰、步骤明确、每一步都有评估、有明确的停止点或者交还给人类的节点。Agent 依然在循环,但只是在你搭建的框架内循环。每次运行结果都能为下一次提供反馈,所以会越跑越好。在普通预算下就能运行,因为路径是收紧的,标准让输出保持诚实。
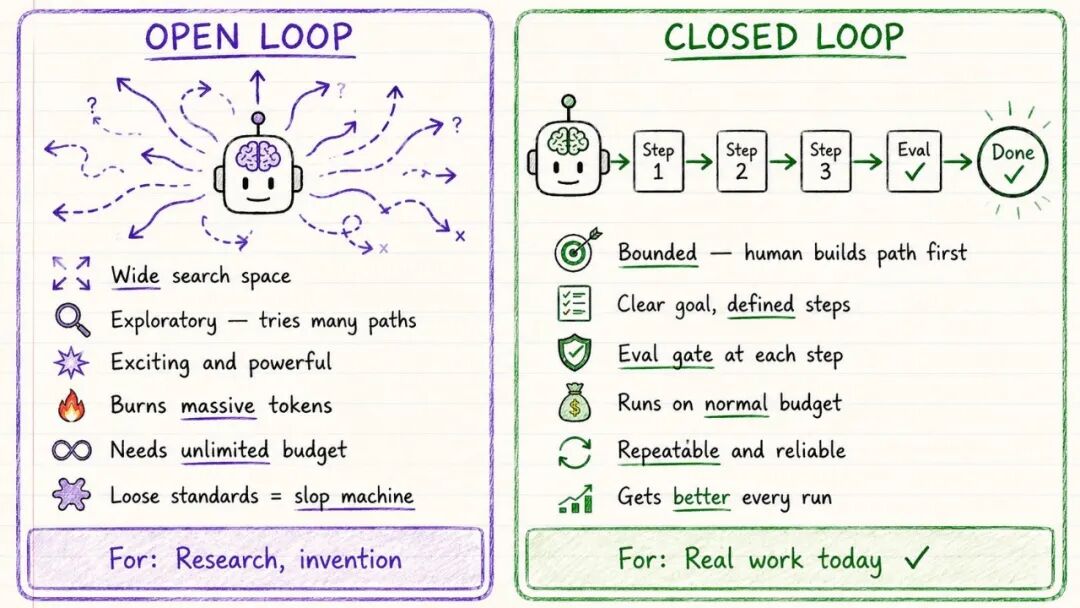
苏米注:没有质量门槛,AI 会跑偏;有了质量门槛,AI 会持续改进。对今天大多数实际工作来说,封闭循环是真正能产生价值的选择。建议从封闭循环开始,先搭建一个可靠的紧凑系统,有了质量门槛之后再慢慢开放。
循环怎么做
每个能稳定运行的循环都包含六个模块,Claude Code 和 Codex 现在都已经内置了全部六个。
1. 自动化
这是触发发现阶段、启动循环的机制,是循环的心跳。自动化让循环成为真正的循环,而不是只运行一次的任务。你定义提示、运行节奏和目标,循环按时运行,结果自动推送给你,不需要你自己到处检查。
/loop— 按节奏重复运行/goal— 持续运行直到你设定的条件满足
你可以给它这样的条件:「test/auth 目录下所有测试通过,lint 检查干净」,然后就可以走开了。
2. 工作树
让多个执行阶段并行运行且互不干扰,实现并行 Agent 不混乱。只要跑多个 Agent,文件就会冲突。两个 Agent 写同一个文件,就像两个工程师不沟通就同时往同一行代码提交一样危险。Git 工作树给每个 Agent 提供独立的隔离工作目录和独立分支,共享同一个仓库历史,零冲突。
3. 技能
让发现阶段更快,Agent 开工前就已经了解你的项目。不用每次从零开始解释项目。一个技能就是一个文件夹,里面放一个 SKILL.md,记录项目规范、构建步骤、那些「我们不用这种方式是因为出过事故」的经验。写一次,每次循环都读。
通常包含三个文件:
- VISION.md — 成功是什么样子
- ARCHITECTURE.md — 技术栈和文件夹结构
- RULES.md — Agent 绝对不能做的事情
4. 插件和连接器
让执行阶段变得真实,循环可以在你的真实环境中操作,不只是文件系统。基于 MCP 构建的连接器,让 Agent 能读取 Issue 追踪器、查询数据库、调用测试环境 API、往 Slack 发消息。这就是「Agent 说这是修复」和「Loop 自己开 PR、关联 Linear 工单、CI 绿了之后自己 ping 频道」之间的区别。
5. 子 Agent
让验证阶段保持诚实,检查者永远不是制造者。不要让写代码的人给自己打分。写出代码的模型,评价自己的作业总是手下留情。第二个 Agent,指令不同,有时候甚至用不同模型,能抓住第一个 Agent 自我说服漏掉的问题。
有效的拆分方式:
- 一个 Agent 探索
- 一个 Agent 实现
- 一个 Agent 按规范验证
6. 记忆
让循环持久化,第 47 次运行的发现阶段,知道前 46 次都试过什么。这是整个循环的支柱。一个 markdown 文件,或者一个 Linear 看板,任何存在于单次对话之外的东西都行。模型在两次运行之间会忘记一切,仓库不会忘。记忆文件记录:哪些尝试过了、哪些通过了、哪些还在开发。明天早上循环从今天停下的地方继续。

实际循环示例
看看实际应用中循环长什么样。
编程循环
没有人在中间环节,Agent 自己写、自己测、自己修复、自己验证:
读 VISION.md + ARCHITECTURE.md → 规划下一次改动 → 编辑代码 → 自动运行测试 → 如果测试失败 → 读报错 → 修复 → 重新测试 → 如果测试通过 → 总结改动 → 停止
研究循环
定义研究问题 → 搜索来源 → 总结发现 → 对照来源验证声明 → 比较冲突信息 → 合成最终答案 → 达到置信度阈值后停止
内容循环
定义话题 + 受众 + 目标 → 草稿完成 → 审查 Agent 评审草稿 → 根据评审重写 → 按成功标准打分 → 分数通过 → 发布 / 分数不通过 → 再次重写
销售外展循环
定义理想客户画像 → 找到匹配画像的线索 → 用公司数据丰富信息 → 按标准筛选 → 个性化消息 → 质量审查 → 发送或升级给人处理
每个循环的骨架都是一样的:目标 → 行动 → 检查 → 修复 → 重复直到完成。
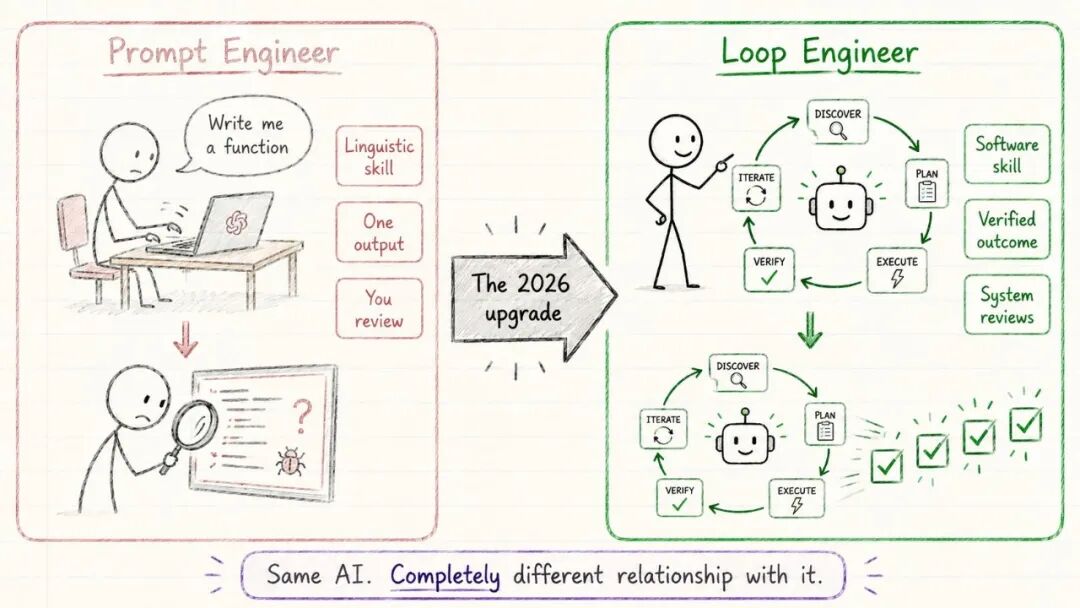
提示工程师 vs 循环工程师
这是 2026 年正在拉开的技能差距。
| 维度 | 提示工程师 | 循环工程师 |
|---|---|---|
| 核心技能 | 打磨更好的指令,依赖语言技巧 | 设计更好的反馈周期,依赖软件工程技巧 |
| 工作方式 | 更好的 Prompt 带来更好的单次输出 | 更好的循环带来可靠的验证结果 |
| 审核方式 | 每次运行后手动审核输出,你自己就是反馈循环 | 系统自己运行、检查、自我纠正,系统本身就是反馈循环 |
| 典型说法 | "给我写一个函数" | "写 → 测 → 修,直到绿灯" |
工具还是那些工具,但思维模式完全不同。提示工程师向 AI 要输出,循环工程师设计产生验证结果的系统。
总结
如果要做好循环工程,需要两个条件:足够的预算和好的循环设计。人在原来循环中起到的最大作用就是验证与检查,如果这个工作由 Agent 来完成,需要判断它是否能完成得很好,因为很多好与不好的判断是非常主观的。但是有一部分的好与不好的判断,Agent 是可以做的。
循环工程是一个趋势,以后检查判断的工作会慢慢被 Agent 取代,但是现在还是需要一定的技术水平的。
核心要点:
- 六样东西:自动化(心跳)、工作树(并行不冲突)、技能(知识累积)、插件和连接器(真实工具操作)、子 Agent(制造者和检查者分离)、记忆(运行之间不忘记)
- 两种规模:单 Agent(一个大脑,自我改进)/ 舰队(编排器 + 专家 + 子 Agent)
- 两种类型:开放循环(探索式,强大但昂贵)/ 封闭循环(有边界,可靠,负担得起)
- 五个部分:目标(精确定义完成标准)、上下文(VISION/ARCHITECTURE/RULES)、行动(只给真正需要的)、反馈(测试/lint/结构化错误)、停止条件(循环知道何时结束)
原文链接:https://x.com/sairahul1/status/2064277888216555684