我们每天接触的知识载体太多了:PDF 电子书、EPUB、DOCX 文档、团队内部的 Markdown 笔记……这些文件都会面临一个同样的问题:翻了好几遍,就是记不住。
你想让 AI 帮你记住它们,但格式五花八门,有的甚至连标题都没有。更麻烦的是,不同的格式提取效果差别很大——纯文字的书籍可以瞬间提取,但技术书籍里的表格、代码块却全部丢失。
最近在 GitHub 上发现了一个叫做 book-to-skill 的开源项目,可以支持 9 种不同的文档格式,并且会对技术书籍进行布局感知提取。目前已经获得 5000+ Star。
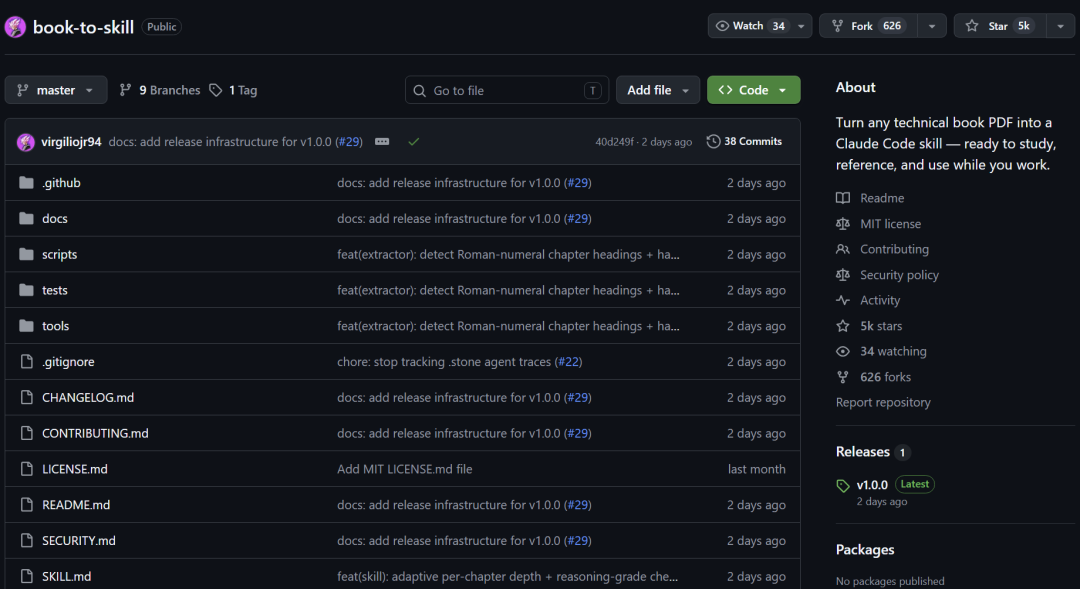
这是目前最聪明的让 AI 学会一本书的方法。并不是让你读得更好,而是让 AI 直接学会书中的结构。
实际使用体验
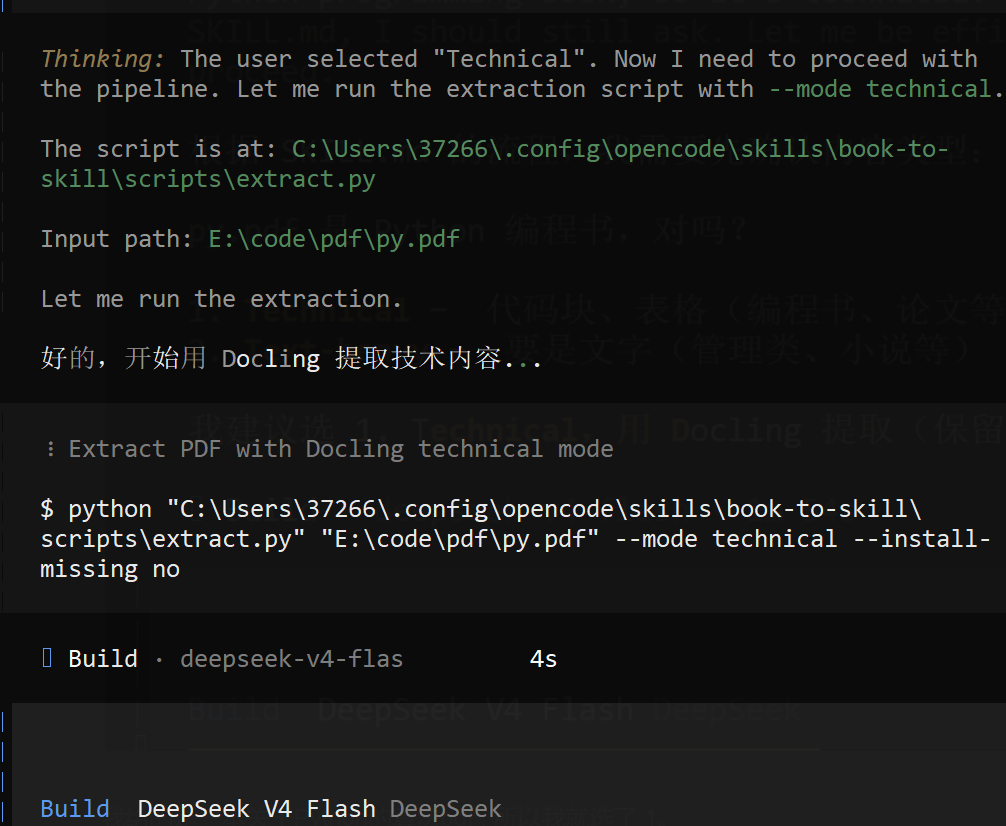
用 OpenCode 执行 /book-to-skill E:\code\pdf\py.pdf,模型选择 DeepSeek。给的是 Python 算法 PDF,选择 1 开始识别提取。
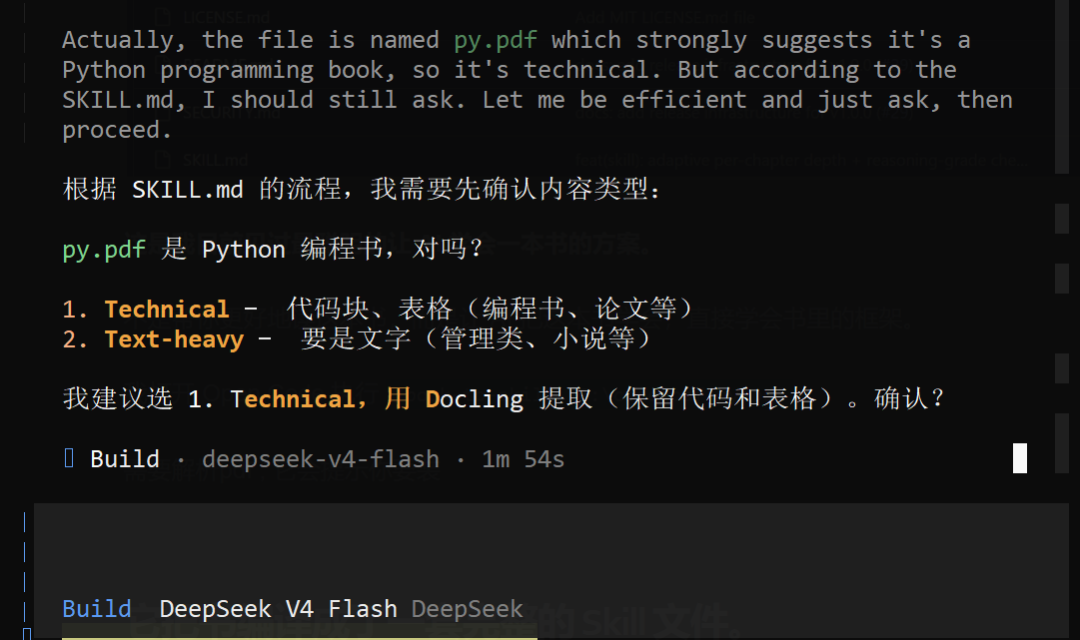
等待 3 分钟后,解析完毕就可以提问了。相关章节都已经找到,可以继续追问。
编译产物结构
book-to-skill 把书编译成一个完整的 Skill 文件,生成的结构如下:
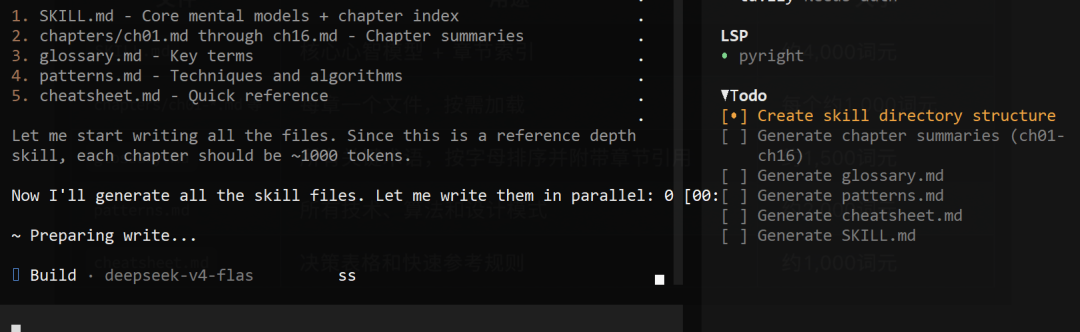

- SKILL.md 核心框架文件:包含心智模型和章节索引,是平时加载的核心部分。提出问题时,它会读取相应章节的内容。
- chapters/ 按需加载章节:每章对应一个文件,每章约 1000 tokens。400 页的书约 20 万 tokens,采用按需加载机制,启动时只读取 SKILL.md,询问具体内容时才加载相关章节。
- glossary.md 术语表:按字母顺序排列所有术语和章节索引。
- patterns.md 模式库:收集所有技术、算法和设计模式。
- cheatsheet.md 决策速查表:相当于书的"导航页",集中整理重要框架、决策规则和常见反模式。
苏米注:按需加载的设计很关键。如果每次对话都把整本书塞进上下文,Token 成本会非常高。这种架构让每次提问只消耗少量 Token 就能调用到书中知识结构。
与直接给 PDF 的区别
直接把 PDF 交给 DeepSeek,它做的是搜索——在原文里找到关键词并告诉你所在页码范围。而 book-to-skill 做的是提取——在编译时把作者花几年建立的框架、命名、心智模型都抽取出来。
当问到"Python 递归算法"时,得到的是"这本书上有关于递归算法的章节",而不会是一堆页码。
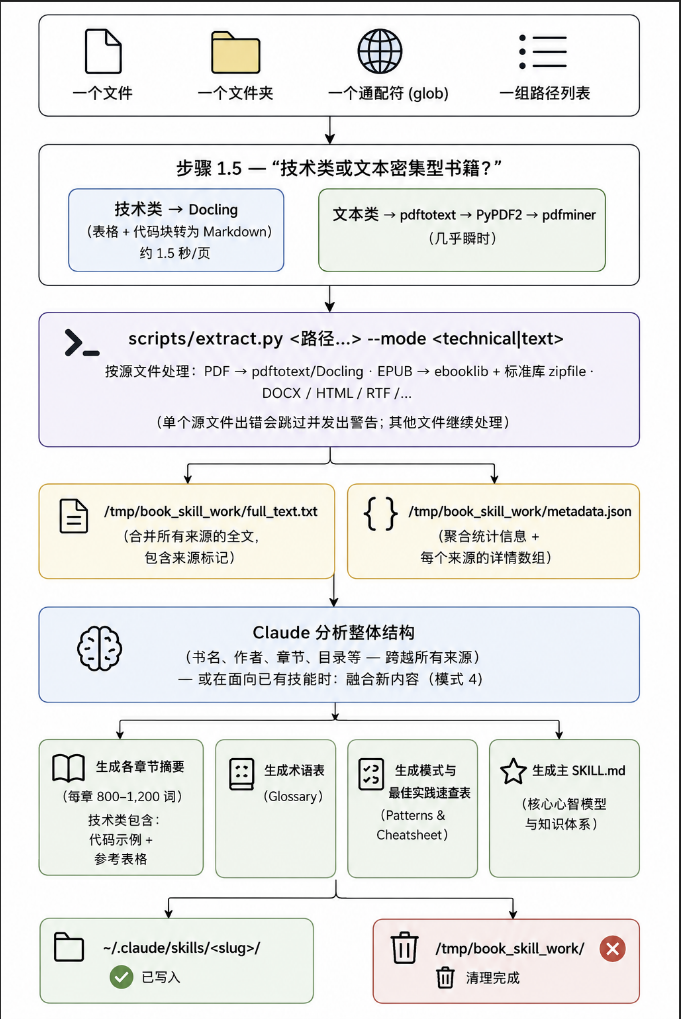
效率方面,官方给出的对比数据:
| 提取方式 | 耗时 | 表格保留 | 代码块保留 |
|---|---|---|---|
| 普通文本提取(pdftotext) | 0.1 秒 | ❌ 全部丢失 | ❌ 全部丢失 |
| 布局感知提取(Docling) | 164 秒 | ✅ 48 个 | ✅ 36 个 |
支持的 9 种格式
格式支持很全面:PDF、EPUB、DOCX、MOBI/AZW/AZW3 五种电子书格式,加上 TXT、Markdown、reStructuredText、AsciiDoc、HTML、RTF 等共 9 种。
安装使用
打开 OpenCode 直接说:帮我安装 https://github.com/virgiliojr94/book-to-skill。Claude Code、Codex、Hermes 等 AI 编程工具也可以。
在 OpenCode 中直接调用:
~/path/to/your-book.pdf/book-to-skill
/your-book-slug replication 查询主题
/your-book-slug ch05 深入章节注意事项
功能看起来很好,但实际使用有一些限制:
- 章节识别有限制:一般需要"Chapter 1"或罗马数字等明显的章节标志。《Moby-Dick》这样的裸标题排版或《Pro Git》这样的文档可能无法正确拆分。
- 技术 PDF 建议用 technical 模式:直接提取文本容易丢失标题层级和文档结构,用 Docling 按技术文档模式解析,虽然速度慢一些,但结构更完整。
踩坑记录:第一次用时拿一本章节标题不符合规范的书测试,结果整本书内容被当作一章。后来才发现要用 technical 模式,速度慢但结构完整。
总结
以前想让 AI 帮自己读一本书,只能把 PDF 塞进上下文或搭建 RAG。即使跑通了,每次对话消耗大量 Token,且 AI 一般只能给出零散信息,无法完整解释整本书的结构。
book-to-skill 的思路不同——它把一本书先编译成可复用的 Skill,之后提问时只需很少的 Token 就能调用书中知识结构。拿到的不是某几页的内容片段,而是一本书完整的思维框架。