两个月,90,000 GitHub Stars。Hermes Agent 凭什么让开发者关注?它有一个其他 AI Agent 框架都没有的核心能力:用得越久,它越聪明。
这篇文章把它的底层逻辑拆给你看。
每个 AI Agent 的共同问题
每个 AI Agent 都有同一个问题:每次开新会话,它忘了所有东西。
你纠正了它三次的代码风格,忘了。你花 10 分钟帮它解决的那个 Bug,忘了。下次再开,又从头来。
这不是某个产品的 Bug,是整个行业都在忍受的架构缺陷。
Nous Research 的 Hermes Agent 选择正面解决这个问题。它不只是"能记忆的 Agent",而是一个会自己写技能、自己管理记忆、还能在离线状态下优化自己的框架。
Hermes 和其他框架最本质的区别
市面上 Agent 框架不少,Hermes 的架构选择跟主流完全不一样。
跟 OpenClaw 的对比最直接——原文里有一句话说得很清楚:"Hermes 是在 Agent 外面包了一个消息网关,OpenClaw 是在消息网关外面包了一个 Agent。"
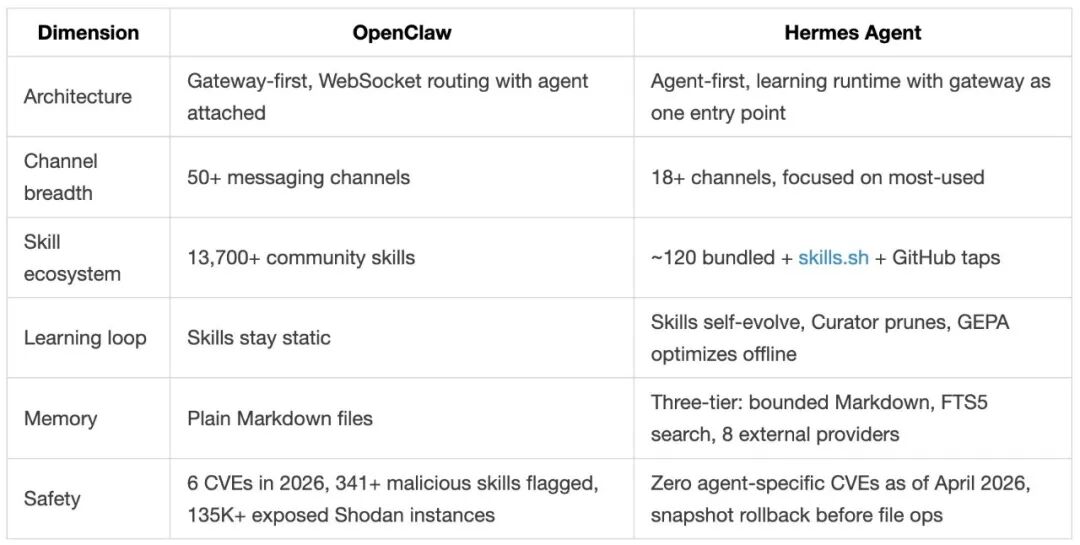
两种完全相反的设计哲学。Hermes 的核心是那个会学习的 Agent,所有渠道(Terminal、Telegram、API)都只是接入层。
整个系统基于一个单文件 AIAgent 类,通过 run_agent.py 跑起来。这意味着不管你用命令行、消息机器人还是 IDE 插件,底层用的是完全一样的 Agent——不是"相似的 Agent",是同一个。
几个工程细节:
- 6 种执行环境:本地 Terminal、Docker、SSH、Modal、Daytona、Singularity,配置一行改,代码不动
- 几乎支持所有主流模型:Claude、GPT、Gemini、Ollama 本地模型,通过统一的翻译层接入,一个命令切换,什么都不会坏
- 90 轮硬限制:防止 Agent 陷入死循环烧你的 API 钱,子 Agent 也共享这个预算
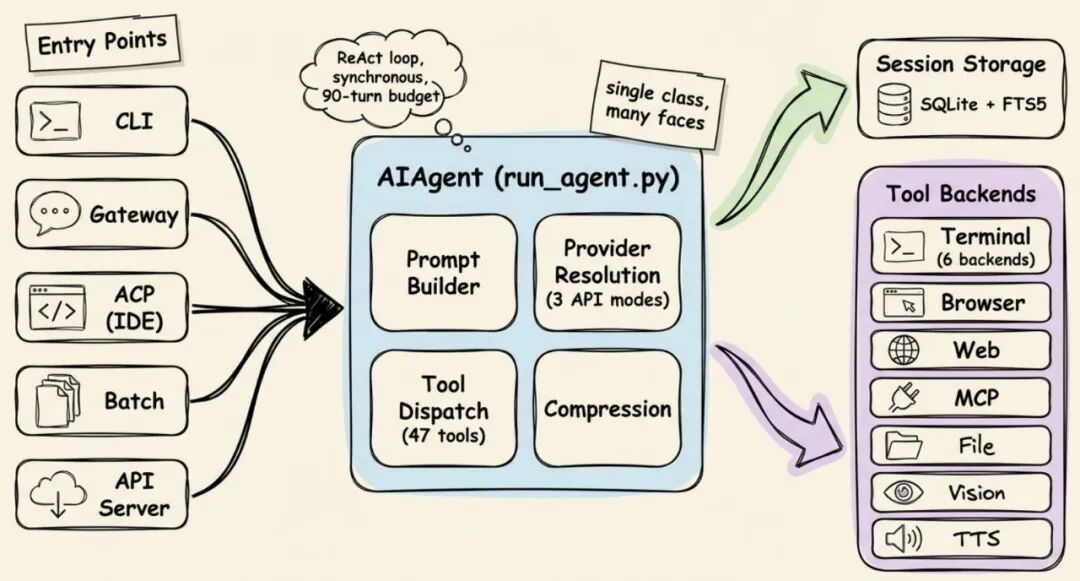
三层记忆系统
这是 Hermes 最有意思的部分,不是靠一个"记忆 API"解决问题,而是分了三层,各有用途。
第一层:两个小 Markdown 文件
只有两个文件:
- MEMORY.md(2200 字符上限):Agent 记录的环境信息、项目惯例、工具坑
- USER.md(1375 字符上限):你的个人档案,沟通偏好、技能水平、雷区
每次会话开始,这两个文件整个塞进 System Prompt。中途写的新记忆当场存盘,但要等下次开会话才生效。
当记忆快满(80% 容量),Agent 会自动合并相近的条目,提炼信息密度,让有用的东西活下来。
第二层:SQLite 全文检索
所有对话(Terminal 和消息渠道)都存在 SQLite 里,支持全文搜索。你可以跨好几周的对话找上下文。
第一层:永远在上下文里,但很小。第二层:容量无限,但要主动搜索。两层互补,而不是互相替代。
第三层:8 个外部记忆插件
对于需要更持久记忆的场景,Hermes 支持 8 个可插拔的记忆提供商。开启之后,Agent 会:每轮之前预取相关记忆,每轮之后同步这轮内容,会话结束后提取关键信息。
Skills:Agent 给自己写使用手册
记忆解决的是"知道什么",Skills 解决的是"怎么做"。
Skills 是带 YAML 头部的 Markdown 文件,本质上就是操作手册:碰到这种情况,按这些步骤做,注意这些坑,最后验证这几点。
一个 k8s 排障的 Skill 长这样:
---
name: k8s-pod-debug
description: >
Activate for crashing pods, CrashLoopBackOff,
"why is my pod restarting", container failures.
version: 1.2.0
author: agent
---
## Procedure
1. Get pod status → check events → pull logs
2. Look for OOMKilled, ImagePullBackOff, config errors
## Pitfalls
- Forgetting --previous flag on restarted containers
## Verification
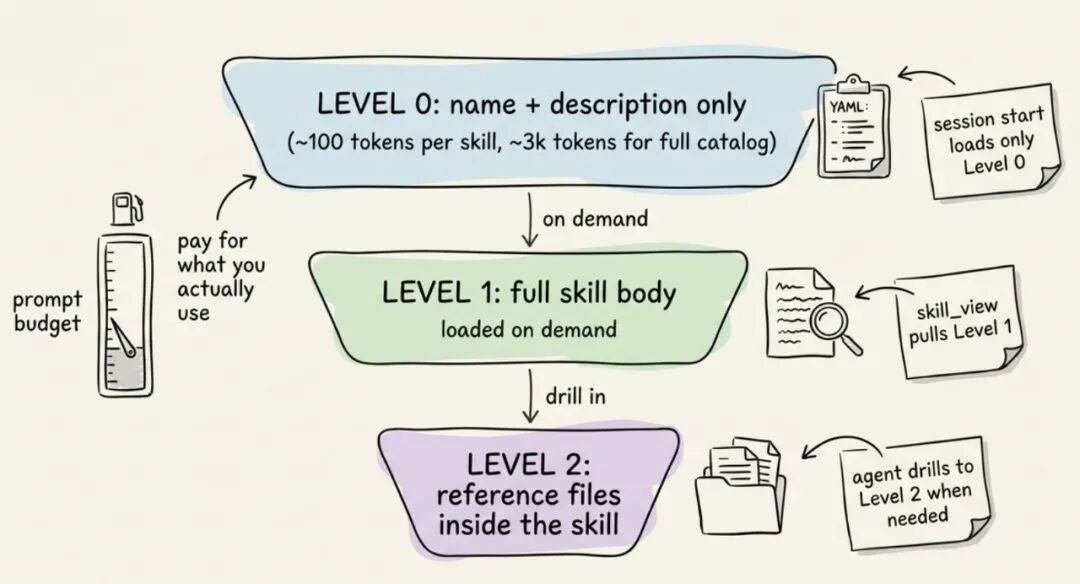
- Pod stays Running with 0 restarts for 5+ minutes为了省 Token,Skills 用三层渐进式加载:
| 层级 | 内容 | 触发时机 |
|---|---|---|
| Level 0 | 名字 + 描述摘要 | 每轮默认加载,整个目录约 3k tokens |
| Level 1 | 完整 Skill 内容 | 判断需要时加载 |
| Level 2 | Skill 内嵌的参考文件 | 需要深入细节时 |
自我进化:Agent 自己创建 Skill
这是 Hermes 最核心的差异化能力。
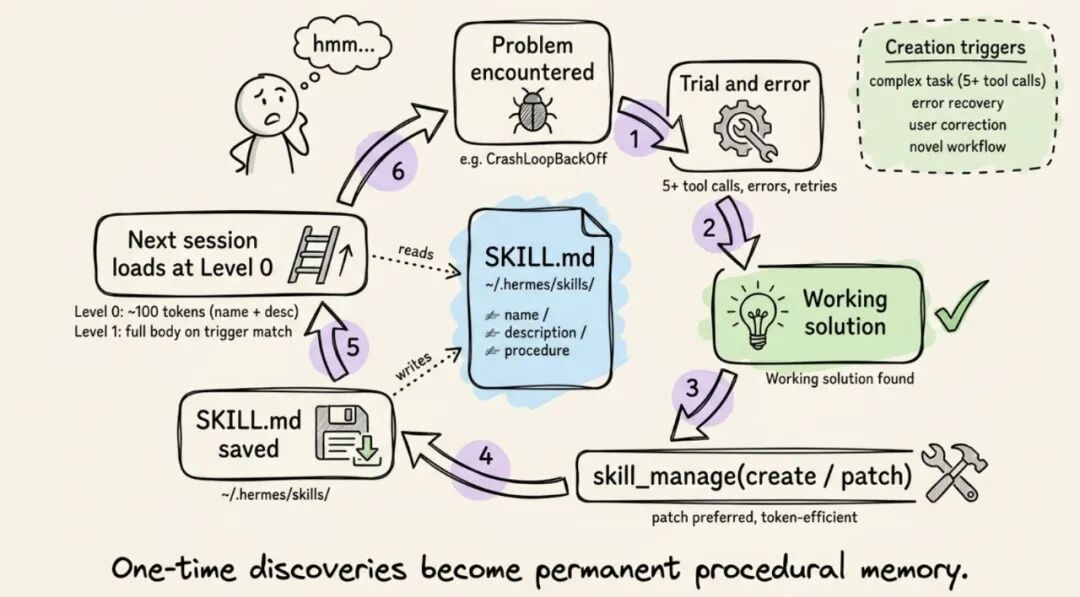
Agent 用 skill_manage 工具自主创建 Skill。触发条件:
- 完成了一个复杂任务(用了 5 次以上工具调用)
- 遇到错误或死路,找到了通路
- 用户纠正了它的做法
- 发现了一个非显而易见的工作流
逻辑很直接:遇到问题 → 试错解决 → 把成功路径存成 Skill → 下次遇到类似问题直接走已验证的路,不用重新摸索。
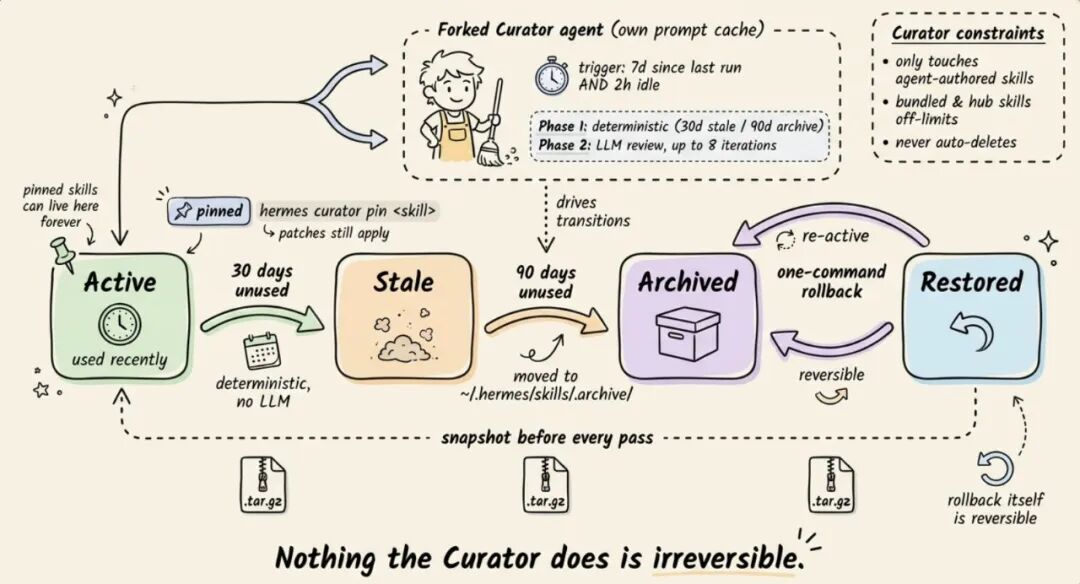
Curator:技能库的垃圾收集器
没有维护,技能库会越来越臃肿——几十个窄且重叠的 Skill,既浪费 Token 也污染目录。
Curator 解决这个问题。它不是定时任务,是惰性检查:如果距上次运行超过 7 天,且 Agent 已空闲 2 小时以上,就在后台启动一个独立 Agent 进程,不打扰当前对话。
分两个阶段:
- 自动转态(不用 LLM,确定性规则):30 天没用的 Skill 变为 stale,90 天变为 archived
- LLM 审查(最多 8 轮):决定每个 Skill 是保留、修补、合并还是归档
两个重要约束:Curator 不碰官方内置和社区安装的 Skill,只管 Agent 自己创建的。永远不自动删除,最坏结果是归档到 ~/.hermes/skills/.archive/,一个命令就能恢复。
每次 Curator 运行前,Hermes 都会对整个 Skills 目录做 tar.gz 快照备份。
GEPA:离线进化引擎
这是整个体系里最"黑科技"的部分,也是最不被人注意的部分。
运行时的自我学习有个已知弱点:Agent 倾向于对自己的表现过度乐观——几乎永远觉得自己做得不错,哪怕实际上并没有。而且同一个生成 Skill 的系统,也可能把你手动定制的 Skill 覆盖成更差的版本。
GEPA(Genetic-Pareto Prompt Evolution)是这个问题的离线解法。它不内置在运行时里,单独在 NousResearch/hermes-agent-self-evolution 仓库,作为独立优化管道运行。今年拿了 ICLR 2026 Oral。
核心思路:不问 Agent "你觉得你做得好吗",而是读执行轨迹,从里面找到失败原因,再用进化搜索提出针对性改进。
流程:
- 读当前 Skill
- 生成评估数据集(Claude Opus 合成测试用例,或真实会话历史,或手动黄金集)
- GEPA 优化器:读执行轨迹 → 理解失败点 → 生成候选变体
- 用 LLM 打分(用评分标准,不是 pass/fail 二元判断)
- 限制条件:测试套件必须 100% 通过,Skill 不超过 15KB,语义目的不能漂移
- 最佳变体作为 PR 提交,不直接 commit
不需要 GPU。全靠 API 调用。每次优化大概 $2-10。
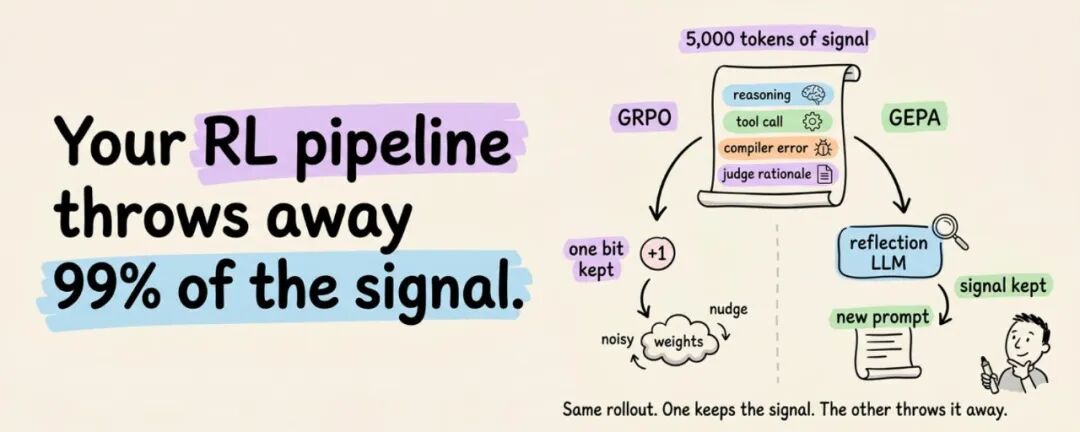
这是对 GRPO 等 RL 微调路线的一个替代方案——不动模型权重,只优化 Prompt/Skill 文本本身。
快速上手
安装和初始化
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
source ~/.bashrc # 或 ~/.zshrc
hermes setup # 交互式设置:模型提供商、API Key、工具配置
hermes # 开始对话连接 Telegram
从 @BotFather 获取 Bot Token(运行 /newbot),从 @userinfobot 获取你的 Telegram User ID,然后在 setup 时配置。完成后,手机就能直接跟 Agent 聊了。
~/.hermes/ 目录结构
~/.hermes/
├── config.yaml # 所有非密钥配置
├── .env # API Keys 和密钥
├── SOUL.md # Agent 身份定义(System Prompt 第一位)
│
├── memories/
│ ├── MEMORY.md # 持久记忆
│ └── USER.md # 用户画像
│
├── skills/ # 所有 Skills
│ ├── mlops/
│ ├── devops/
│ └── .hub/
│
├── sessions/ # 会话元数据
├── state.db # SQLite(FTS5 全文搜索)
├── cron/ # 定时任务
└── logs/几个关键文件:config.yaml 是非密钥配置的唯一来源;.env 存密钥;SOUL.md 定义 Agent 人格;state.db 是会话搜索的数据库。
从 1 到 10 个 Agent
单个 Agent 够用,多个专职 Agent 才有意思。
Hermes 有 Profile 系统:每个 Profile 是一个完全独立的 Hermes 实例,有自己的配置、记忆、Skills 和 SOUL.md,默认不共享任何东西。
可以设置三个 Agent:程序员、研究员、设计师。每个 Profile 需要各自的 Telegram Bot。
SOUL.md:给每个 Agent 不同的人格
这是让三个 Agent 真正不同的地方。
设计师的 SOUL.md 关键词是"手绘风格插图,解释 AI/ML 概念,白板草图而非精致营销图"。程序员的是"简洁务实的资深工程师,读代码再写代码,最小改动解决问题"。研究员的是"每日 AI/ML 领域深度摘要,涵盖 GitHub 趋势、大厂动态、新论文、X/Reddit/HN 社区脉搏"。
让程序员 Agent 用 Claude Code 执行
发一条激活提示:
I already have a Claude Max subscription. You are my staff engineer who helps me with my day-to-day coding tasks, and under the hood you use Claude Code for all the executions. Set yourself up accordingly.
Agent 会自己安装 autonomous-ai-agents/claude-code Skill,验证 claude 在 PATH 里,然后所有编码任务都通过 Claude Code 执行。前提是 claude 已经在 PATH 里。
用自然语言设置定时任务
告诉研究员 Agent:
Every weekday at 8am India time, prepare a deep digest of what's new in the AI and machine learning space over the last 24 hours. Cover four streams in this order: Trending GitHub repos, Big tech and lab announcements, Fresh research papers, Social pulse from X/Reddit/HN. Keep it under 800 words. Deliver to Telegram. Set this up as a recurring cron job.
Agent 自动创建定时任务,明天早上 8 点 Telegram 里就有摘要了。
Hermes Skills Hub
Hermes 官方维护了一个 Skills Hub,当前有 687 个 Skills,分 18 个类别:
| 来源 | 数量 |
|---|---|
| 内置 Skills(默认加载) | 87 |
| 可选 Skills(按需启用) | 79 |
| Anthropic 官方 | 16 |
| LobeHub 社区 | 505 |
可以添加任何 GitHub 仓库作为自定义 Skill 源:
hermes skills tap add yourname/your-skills-repo
hermes skills install yourname/your-skills-repo/skill-name团队共享 Skills、维护私有 Skills 库都走这个路径。
社区现状

@aakashgupta 说了一句更直接的话,大意是:
Anthropic 没办法在 Claude Code 里写"切换到 GPT,你的 Skill 文件带走"。OpenAI 也没办法在 ChatGPT 里写"你的记忆存本地,明天切去 Claude"。不锁定供应商的中立运行时,只能由没有模型护城河要守的实验室来做。Nous Research 做了这个东西。
这个判断有意思。闭源 AI 公司做 Agent 框架,天然的利益冲突就在这——你不可能真正中立。
至于 GEPA——建议是:先别管它,等你在运行时的自进化上撞到墙了,再去研究 GEPA。用几千美元解决微调要花几十万的问题,可以考虑。
苏米的总结
Hermes Agent 的三层记忆 + 自写 Skill + GEPA 离线优化,构成了一个完整的"复利飞轮"。用得越久积累越多,而不是每次重置。
现在 2 个月 90K Stars,GitHub 增速超过了 Claude Code。开源 Agent 的格局还在形成中,这个方向值得认真看。