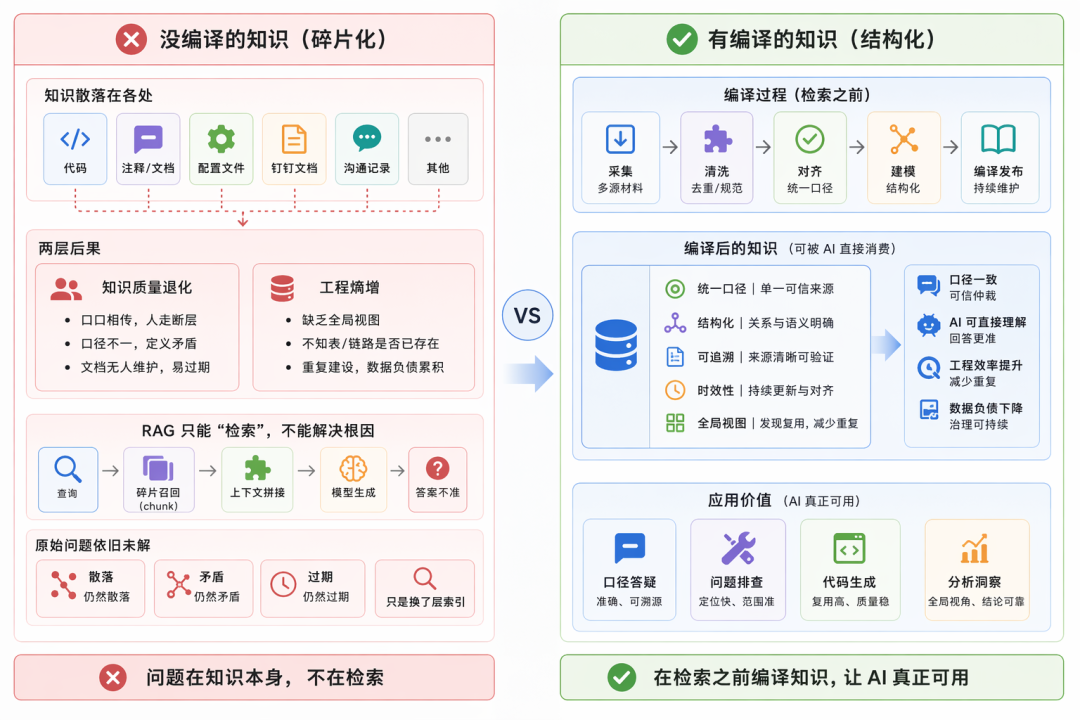
领域知识决定了 AI 在业务中能发挥多大的价值。任何 AI 系统都由模型、知识、架构三部分组成——模型由供应商提供,架构常因模型升级而失效重做,只有领域知识只能从内部积累,不可替代且持续变化,是最值得长期投入的部分。
然而在实际团队中,知识散落在代码注释、配置、文档、沟通记录各处,带来两个严重后果:知识质量退化(口径不一致、文档无人维护)和工程熵增(重复建设、数据负债累积)。直接套 RAG 解决不了这个问题——RAG 只是给散落材料加了向量索引,知识本身的问题一个没解决。
LLM Wiki 的思路是:在检索之前加一道"编译过程"——把散落、矛盾、易腐化的源材料,预先加工为可被 AI 直接消费的结构化知识。
核心思想:LLM 作为编译器
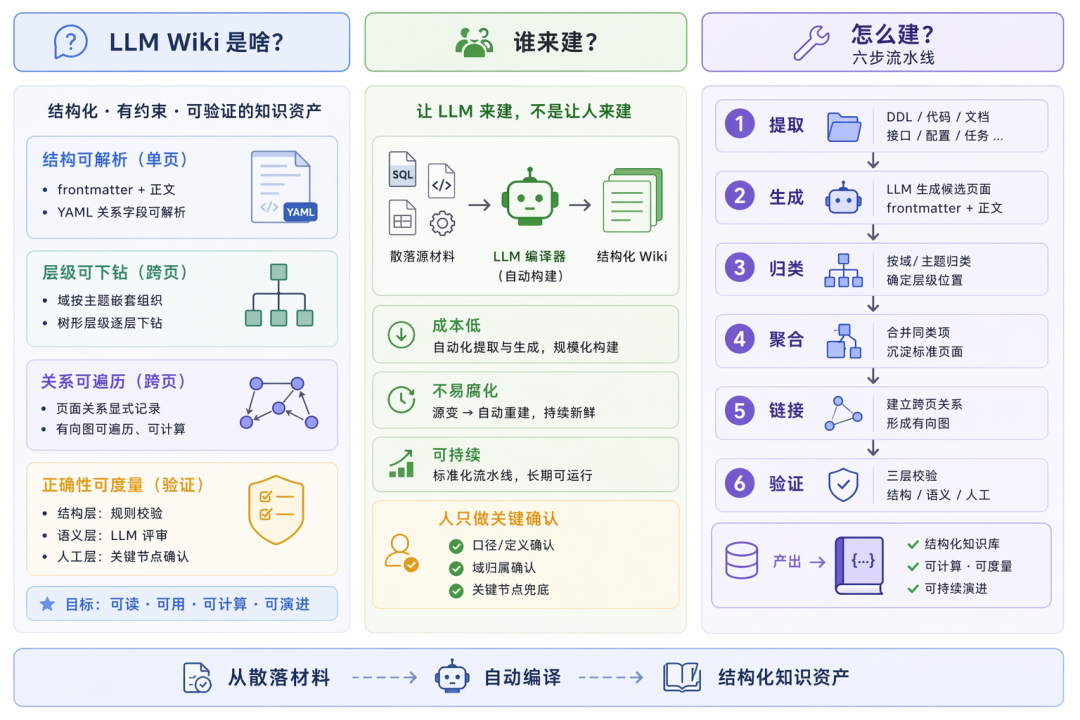
LLM Wiki 不是一份"用 LLM 写出来的文档",而是一份结构化、有约束、可验证的知识资产。它和传统文档的区别在四个层面:
- 结构可解析——每个页面是 frontmatter(YAML 元数据)+ 正文的双层结构,脚本可直接读取关系信息
- 层级可下钻——域按业务主题嵌套组织,形成可逐层下钻的树,支持渐进式披露
- 关系可遍历——页面之间的血缘、归属、消费关系以有向图形式显式记录
- 正确性可度量——分结构、语义、人工三层校验,从主观判断转为可度量的工程指标
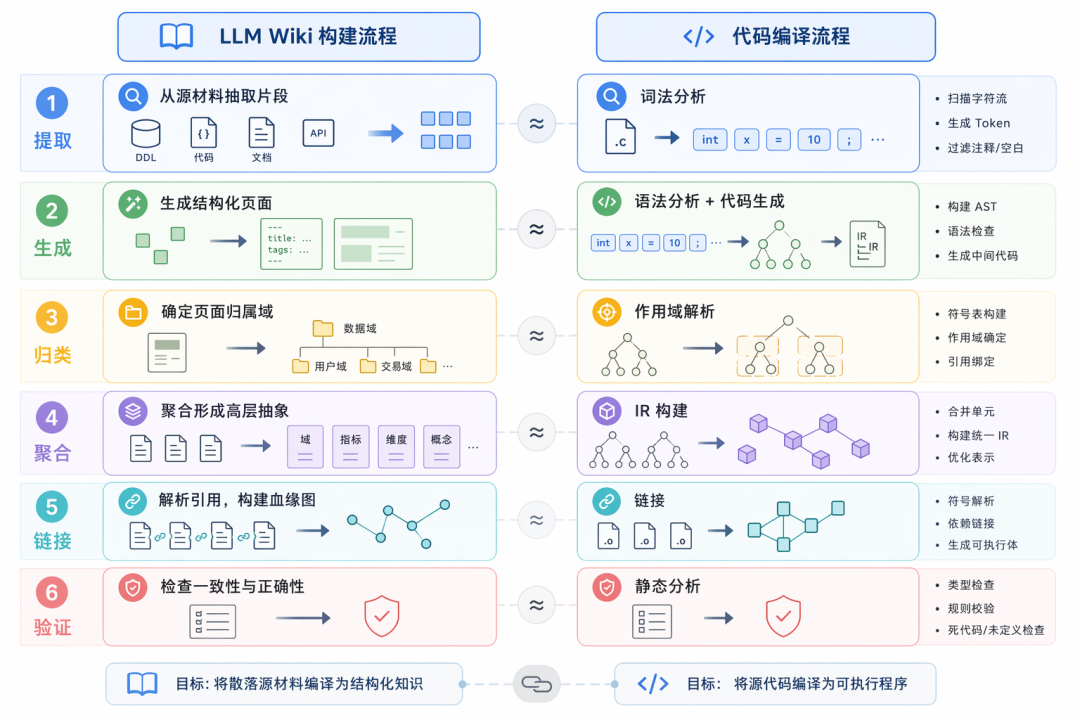
构建过程抽象为六个步骤:提取 → 生成 → 归类 → 聚合 → 链接 → 验证,对应编译器的词法分析、代码生成、作用域解析、IR 构建、链接、静态分析,本质是一条将散落源材料编译为结构化知识的流水线。

LLM Wiki 与 RAG:互补而非冲突
用"编译时 vs 运行时"来理解:LLM Wiki 是编译时产物,把原始材料预处理成高质量的知识页面;RAG 是运行时手段,在查询时刻做精准召回。Wiki 提供高质量语料,RAG 提供精准召回,组合起来才是完整的检索栈。
知识构建的四个关键原则
1. 知识来源要全
编译时知识(DDL、任务代码、文档、接口配置、看板元数据)在构建阶段固化为 Wiki 页面;运行时知识(物理表数据、任务日志、监控指标)通过 Agent 工具调用现取。每张表不止抓 DDL,还要抓任务代码——DDL 提供结构信息,任务代码提供计算逻辑。
2. 知识构建要准
- 噪音过滤:入口粗筛 + 生成细筛,降低冲突量
- 代码即真相:不同来源描述不一致时,以任务代码为权威(它每天跑在生产上)
- 生成与判断分离:生成阶段强制留空推断内容,判断阶段独立跑一轮,经过机械门禁 + 人工门禁双重校验
- 证据链可追溯:每个页面保留 sources 字段,指向具体源材料
3. 知识的骨架是关系
把关系从正文中抽出来,显式存储为图。显式建图带来三个能力:
- 影响范围可计算——修改一张表后,沿图向下游遍历即可得到完整影响面
- 归属关系可聚合——任何一个域包含哪些资产,一次查询完成
- 枢纽节点可识别——按引用频次排序,发现数仓中的公共依赖和关键路径

4. 为检索而组织
- 知识聚合:把数百个分散页面收敛到少数几个域入口
- 渐进式披露:从全景概览定位相关域 → 从域定位关键页面 → 从页面获取字段和逻辑细节
- 多路召回:命中一个节点后,沿边扩展到血缘相关但关键词未命中的知识
架构设计
Wiki 系统以文件为底座,三层主干:
- 存储层:多级文件系统(pre/ → raw/ → wiki/),按生命周期隔离物料
- 知识模型层:Schema 定义页面契约(frontmatter + 正文模板),类似数据库的 DDL
- 计算层:Agent 编排,编排层与干活层分离

系统由 7 个 Skill 组成:编排器负责意图路由、用户确认、子 Agent 调度;6 个干活 Skill 各自覆盖编译流水线的一个阶段(材料预处理 → 基础生成 → 高阶生成 → 图构建 → 健康检查 → 运行时检索),通过文件系统约定的目录交互,可并行、可独立调试、可单独复用。
编译流水线三阶段
Phase 0:材料预处理——从外部系统抓取 DDL、任务代码等材料,经过完整性验证和三态分流(ready/pending/archive)。全脚本化执行,不依赖 LLM,支持断点续传。
Phase 1:Wiki 生成——基础生成(表、接口、数据集、概念四种基础页面,一对一映射)+ 高阶生成(域、看板、指标、维度等多对一聚合)+ 图构建(扫描 frontmatter 和 Wikilink 沉淀关系图)。批间串行、批内并行,5 路并发提速且上下文隔离。
Phase 2:健康检查——执行结构、链接、格式等多项校验,未通过的标记重生成。
实际效果
在数据模型迭代场景中,传统人工做法依赖逐表排查 SQL 代码,耗时易出错。基于 LLM Wiki:
- 血缘查询时间:30 分钟 → 2 分钟(15× 提效)
- 下游表遗漏率:20% → 0%(强制完整性校验)
- SQL 生成时间:0.5 天 → 10 分钟(72× 提效)
- 风险判定:从"凭经验"升级为标准化二维矩阵
模型迭代影响分析从半天缩短到小时级,数据研发工程师从"查代码、写 SQL"的机械工作中解放,聚焦在"决策确认"的高价值环节。
总结
LLM Wiki 的本质是把知识管理从"人写文档"升级为"LLM 编译 + 人工确认"。领域知识只能从内部积累,而 LLM 编译器把散落的源材料加工为结构化、可验证、可检索的知识资产。它不取代 RAG,而是为 RAG 提供高质量的语料基础。两者组合,才是 AI 时代知识管理的完整方案。