AI 海报生成的痛点:改一个字等于重做整张图
用 GPT Image 2、Midjourney、Flux 这些 AI 生图工具做海报,效果确实惊艳。但一旦需要改一个字、换个元素、调整一下布局,问题就来了——只能改 prompt 重新生成。
重新生成意味着整个版式又变了。AI 不会记住"上次那个 layout"。
这个问题在商业场景中尤其突出。海报、社交媒体首图、活动 banner,所有"上线前再微调一下"的需求,AI 生图都接不住最后 10% 的修改。以前只有两个绕法:转 Photoshop 分层抠图手动改(耗时、精度差),或者用 prompt 反复 reroll 最后接受一张"差不多"的(妥协)。两个都不优雅。
苏米注:这个问题我深有体会。之前用 AI 做公众号封面,标题错了一个字,重新生成后整个背景色都变了,只能放弃。
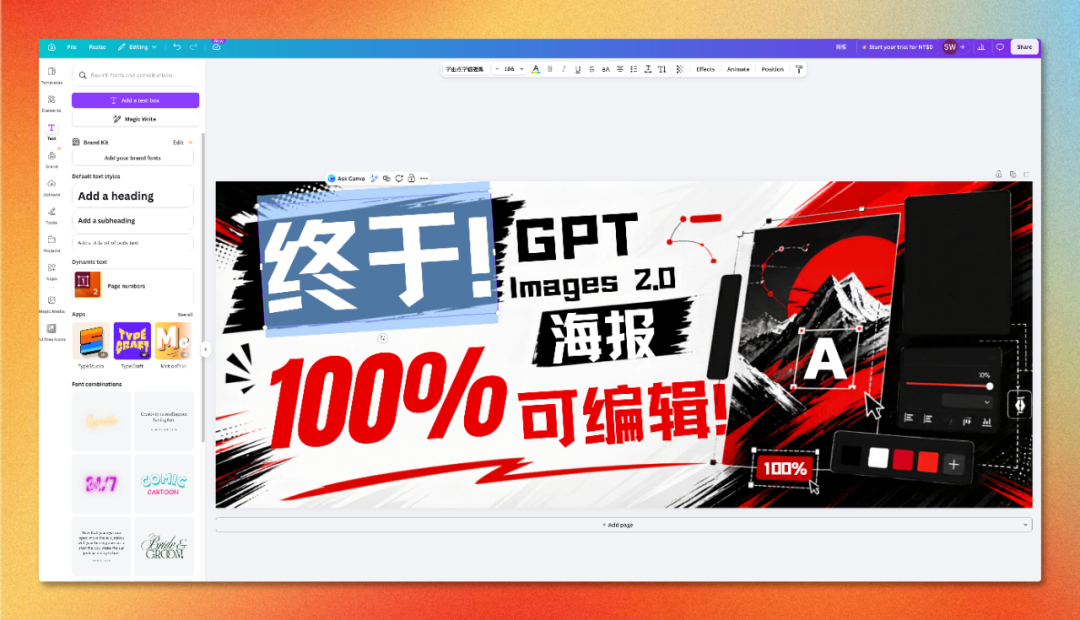
现在,Canva 推出的 Magic Layers 功能,把这个问题解决了。一张平面 AI 图像,可以被自动拆成数十个独立图层——文字、人物、背景、光效、签名——全部可以单独选中、移动、删除、替换、改字体。
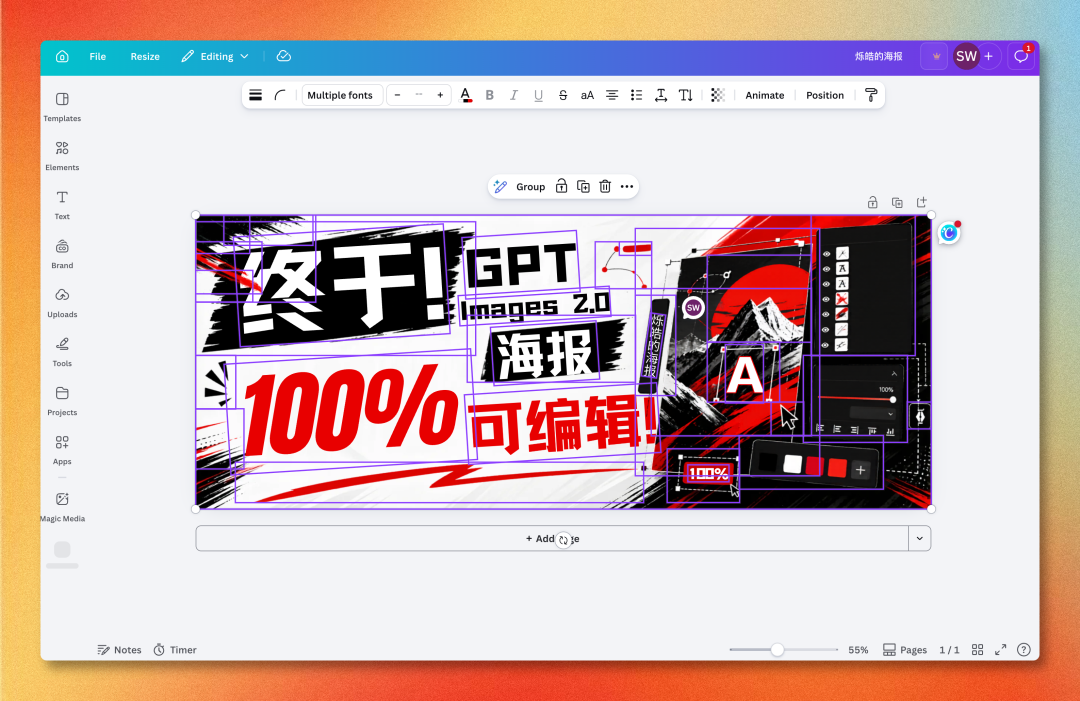
Magic Layers 做了什么?
Magic Layers 本质上做的是一件事:反向工程一张静态图,把它还原成 Canva 原生的可编辑工程文件。
不是简单的抠图,也不是 OCR 识别文字再贴上去——而是语义级的图层分离:
- 文字 → 可编辑 textbox(识别字体、字号、对齐方式)
- Logo / icon → 独立 element
- 背景纹理、装饰图形 → 各自图层
- 阴影、光斑 → 单独可调
拆完之后,整张图就是一个普通的 Canva 工程,所有 Canva 原有的编辑能力都能直接用——换字体、调色、加动效、一键导出多平台尺寸。
完整操作流程
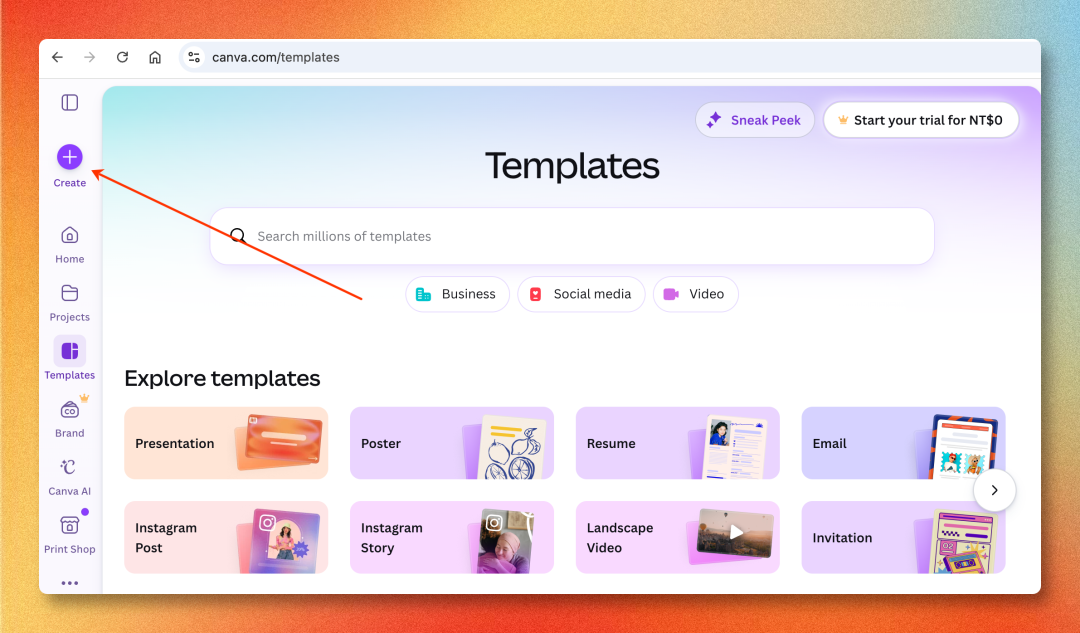
第一步:打开 Canva,点击 + Create
打开 canva.com,登录后会停在 Templates 页。左侧栏第一个按钮 + Create(添加)就是入口。
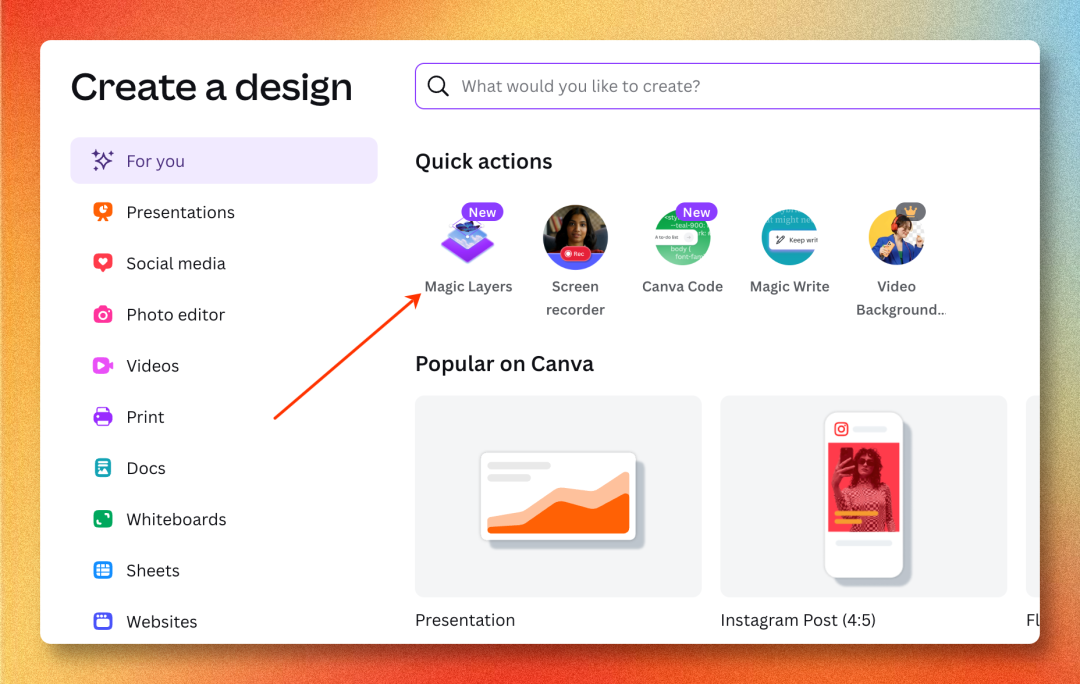
第二步:在 Quick actions 里找到 Magic Layers
点完 Create 后会进入 "Create a design" 面板,左侧选 For you → Quick actions,第一个就是带 New 标签的 Magic Layers。
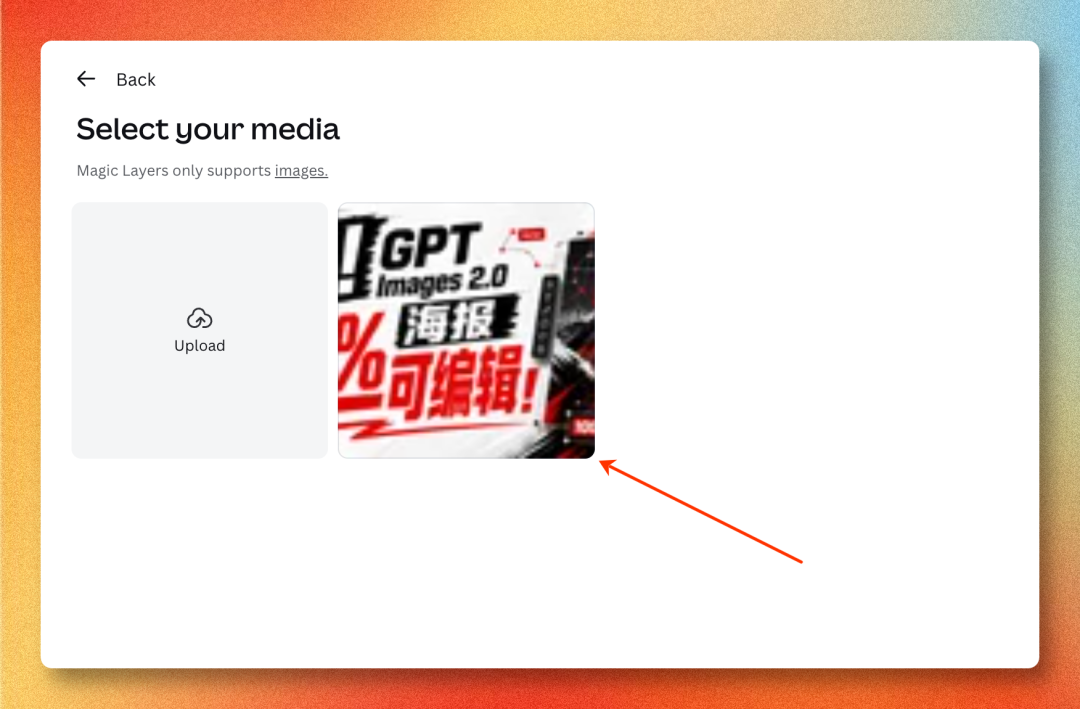
第三步:上传 AI 生成的海报
点 Magic Layers → "Select your media",把 GPT Image 2 出的海报拖进去。目前只支持图片格式,PDF / SVG 暂不支持。
第四步:等待自动拆解
上传后大约 5-10 秒,Magic Layers 会分析整张图的元素,把每一块拆成独立图层。左侧 Edit image 面板可以看到所有可调项——Adjust、Magic Edit、Magic Eraser、BG Remover、3D Generation 全都直接挂在拆完的图上。

第五步:像普通 Canva 工程一样编辑
进入编辑器之后,每一个文本、每一个图形都能单独点选、移动、改字、换色。
这套工作流的价值
把整套流程拉直了看,一共四个环节:
- 创意/草图:用 ChatGPT 写 prompt,描述要什么
- 出图:用 GPT Image 2 生成视觉成品
- 微调/编辑:靠 Canva Magic Layers 改字、换色、调位
- 多平台导出:用 Canva 原生功能搞定横竖屏和社交尺寸
这条链路在过去的"微调"环节是断的,AI 出的图就是终点。现在它变成中间产物,下游接 Canva,整套工作流第一次跑通。
对个人内容创作者来说,会写 prompt 的人 + 一个 Canva 账号,能完成过去需要"提示词工程师 + 平面设计师"两个人才能干完的事。
局限与适用场景
Magic Layers 不是万能的,实测下来有几个局限:
- 复杂插画(多人物、密集元素)的拆解精度有限,部分元素会被合并
- 字体识别偶尔失误,需要手动重新选字体
- 拆解后的图层数量大约 30-50 上限,超过会被合并
最适合的场景:
- 社交媒体海报(小红书、X、公众号封面)
- 活动 banner、产品发布图
- 简单插画类内容图
不太适合的场景:
- 摄影类成片(拆解意义不大)
- 多人物复杂插画
- UI 设计稿(建议用 Figma)
苏米的看法
AI 生图在 2024-2025 解决了"能不能画出来",2026 这一波在解决"画完之后能不能动"。
Magic Layers 在技术上不算多新——抠图、OCR、分层都是老技术——它真正的价值是把这些能力打包成对设计师友好的入口,并且直接接在 AI 生图工具的下游。
下次再有人说"AI 出的图改不动",让 ta 试试这个。