Mistral 发布了 Mistral 3 系列,上一次模型更新已是一年多之前。

Mistral 是法国公司,被视为欧洲重要的开源力量,估值约 140 亿美元。
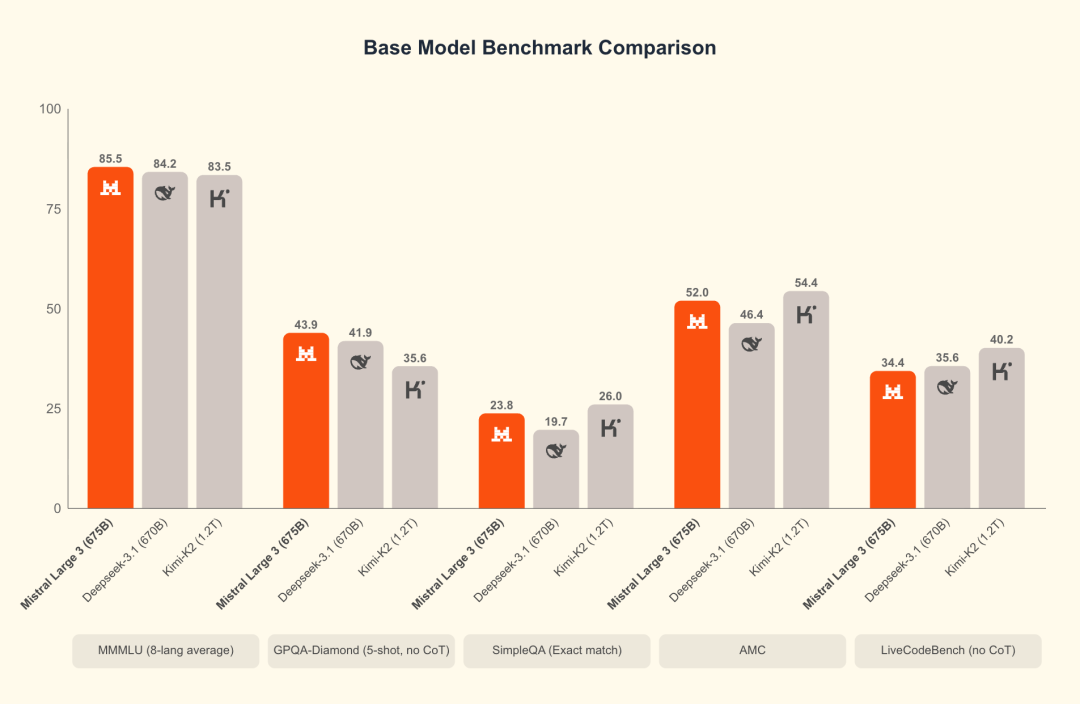
旗舰模型 Mistral Large 3:Mixture-of-Experts(MoE)架构,675B 总参数、41B 激活参数;全系列采用 Apache 2.0 开源许可;Large 3 的 reasoning 版本“即将推出”。
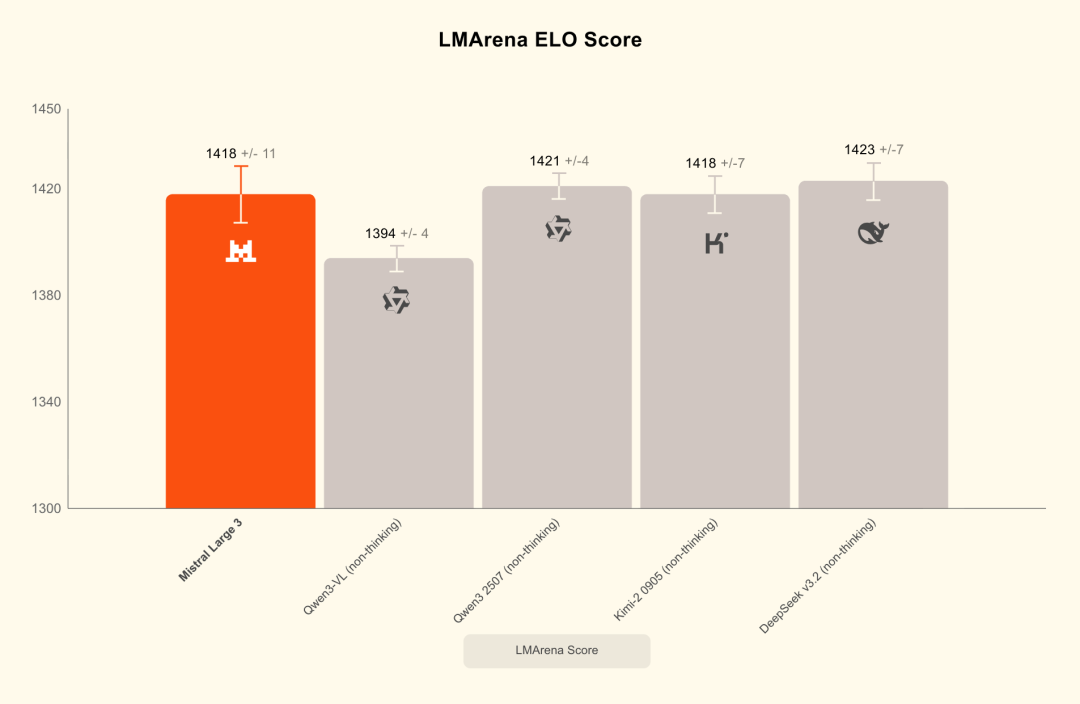
LMArena 榜单:Large 3 在“开源非推理模型”中排名第二、总榜第六(榜单随时间更新,需以当期为准)。
训练基础设施:官方披露使用了 3000 张 NVIDIA H200。
小模型线:Ministral 3(3B/8B/14B)
- 架构:dense 模型;每个尺寸均提供 pretraining、instruct、reasoning 三个版本。
- 能力:全系列支持图像理解,覆盖 40+ 语言。
- 14B reasoning:官方称在 AIME ’25 上达到 85%;同时展示了 GPQA Diamond 的对比数据(未给出具体数值)。
- 生成风格:官方表示 Ministral instruct 的 token 使用量比同级别模型少一个数量级;我自己的短测里,确实能看到更紧凑的回答风格,但不同任务差异较大。
官方对标与评测结论
对标对象只选了中国模型:DeepSeek V3.1、Kimi K2。
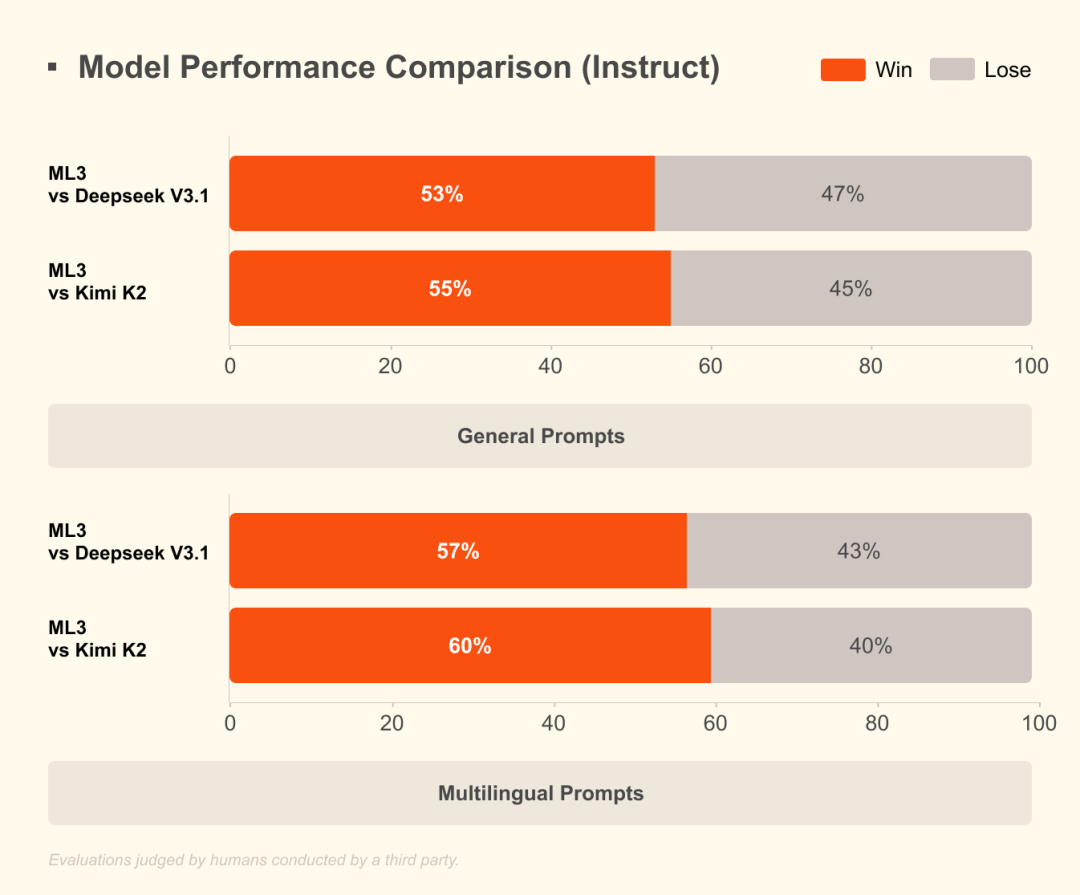
人类评估(第三方执行、但方法学未公开):Mistral 对 DeepSeek 胜率 53%,对 Kimi 胜率 55%。
多语言任务:对 DeepSeek 胜率 57%,对 Kimi 胜率 60%。
我的看法:这些数据可做“第一印象”,但在专业场景(代码、检索增强、数学推理)里,仍建议用自有评测集复核。
Ministral 3 系列还有几个小尺寸模型,3B、8B、14B 三个尺寸,都是 dense 模型
每个尺寸都有 pretraining、instruct、reasoning 三个版本
全系列支持图像理解,支持 40+ 语言
官方说 Ministral instruct 生成的 token 数量比同级别模型少一个数量级
14B reasoning 版本在 AIME '25 上跑到 85%

14B 系列跑分
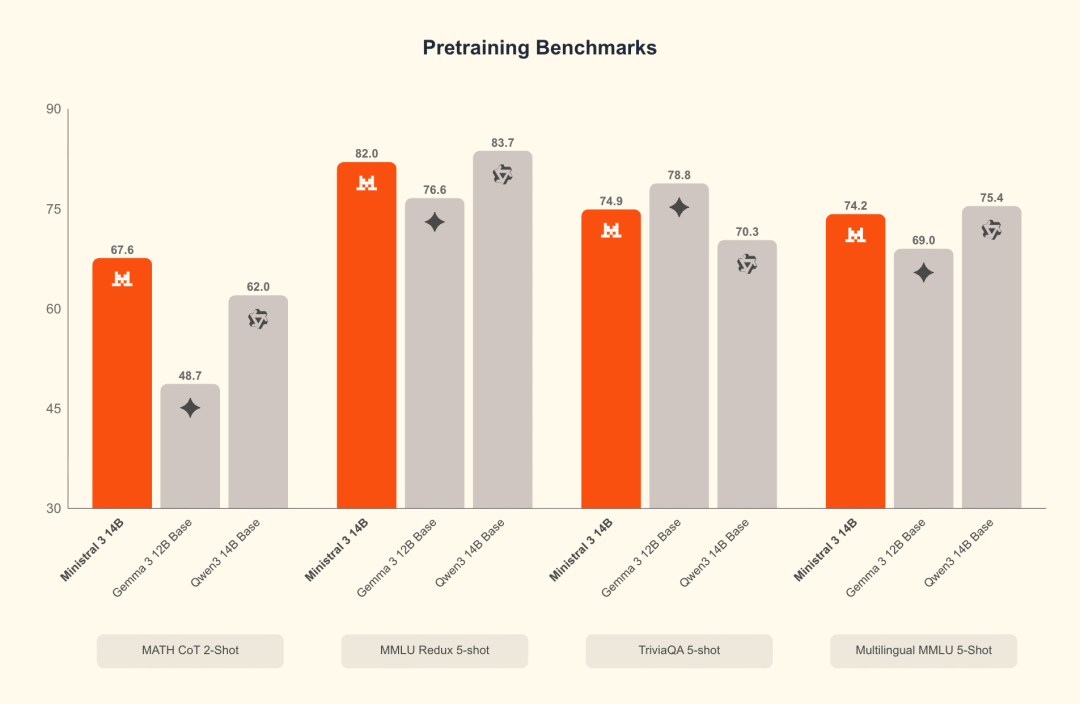
Ministral 14B benchmark: pretraining
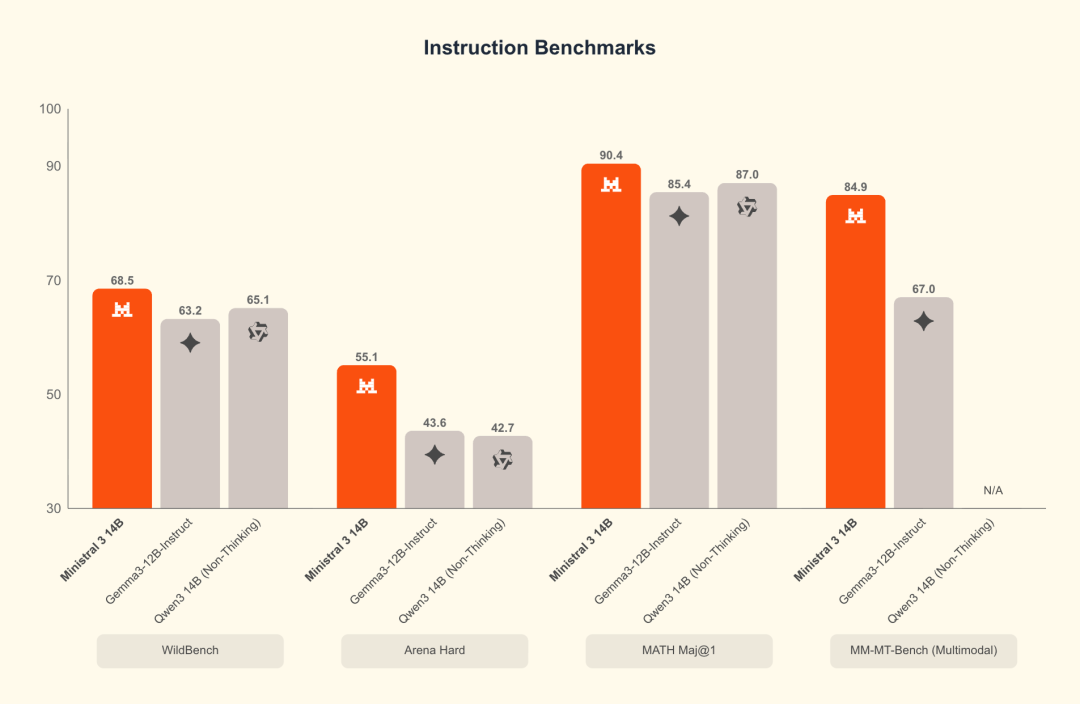
Ministral 14B benchmark: instruct
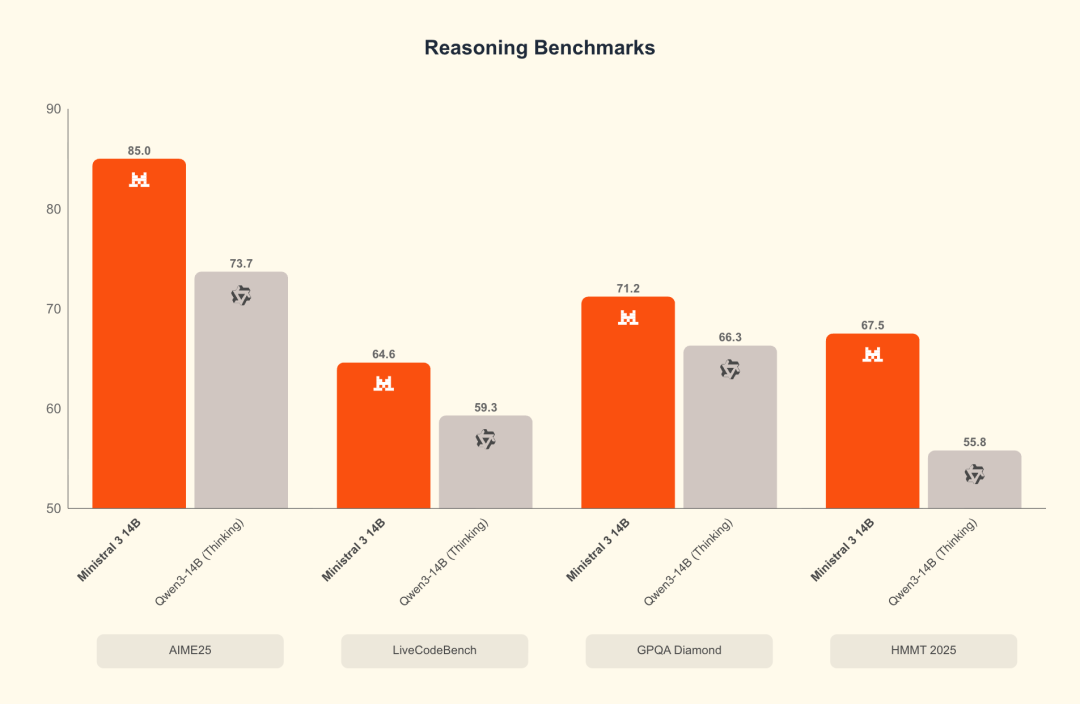
Ministral 14B benchmark: reasoning
8B 系列跑分
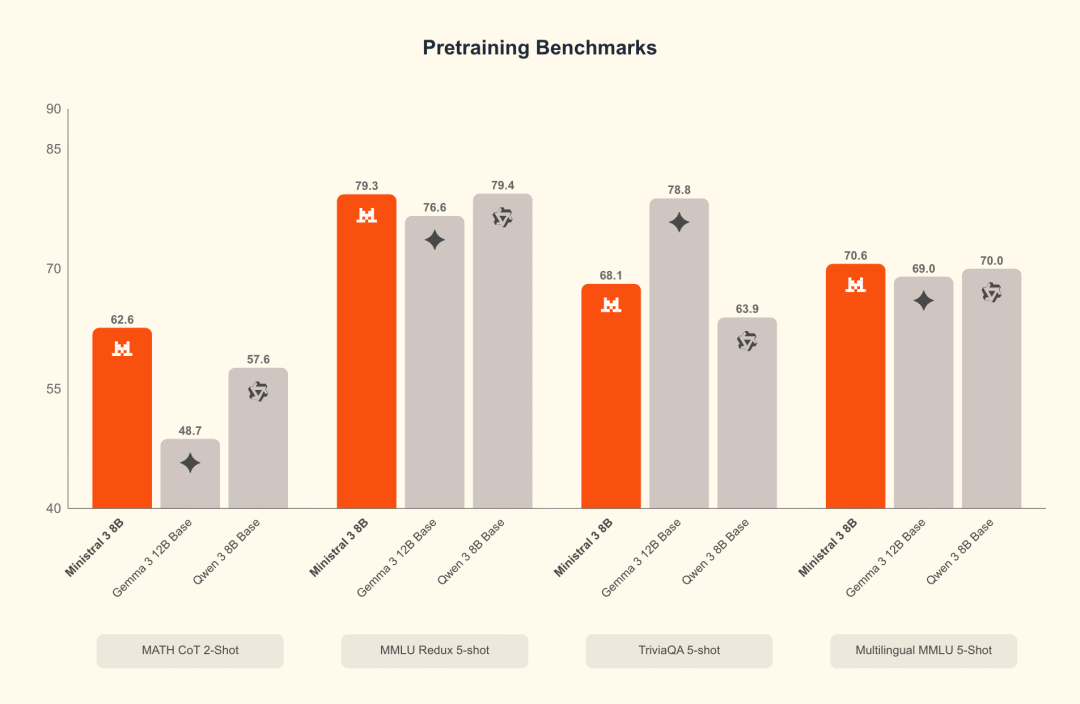
Ministral 8B benchmark: pretraining
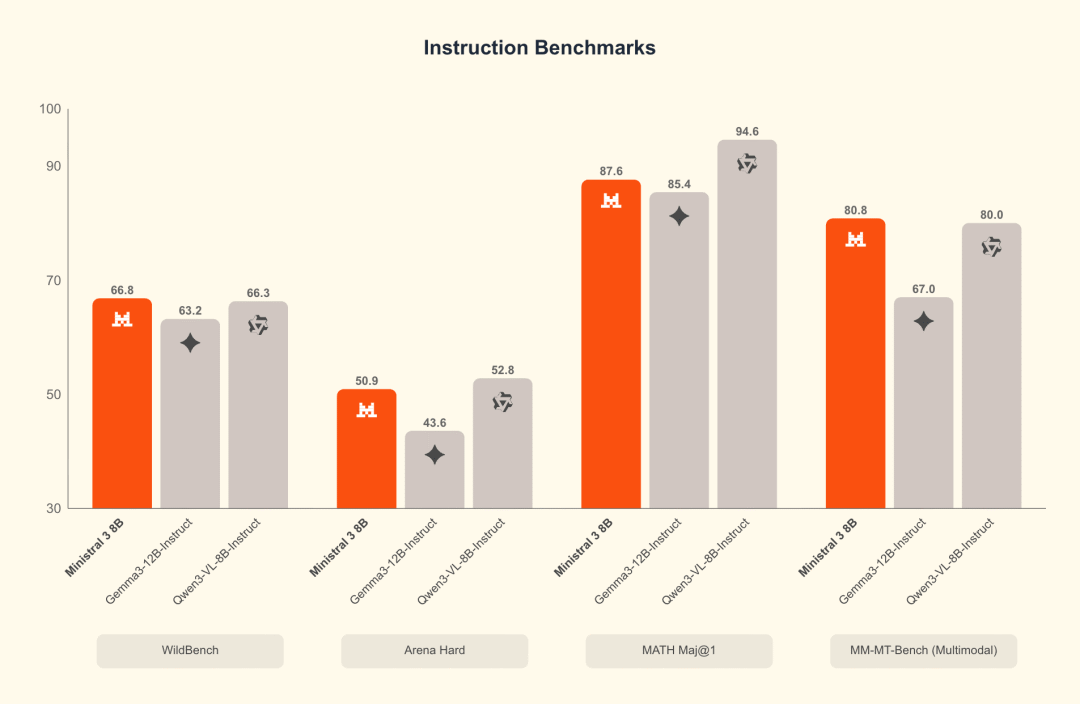
Ministral 8B benchmark: instruct
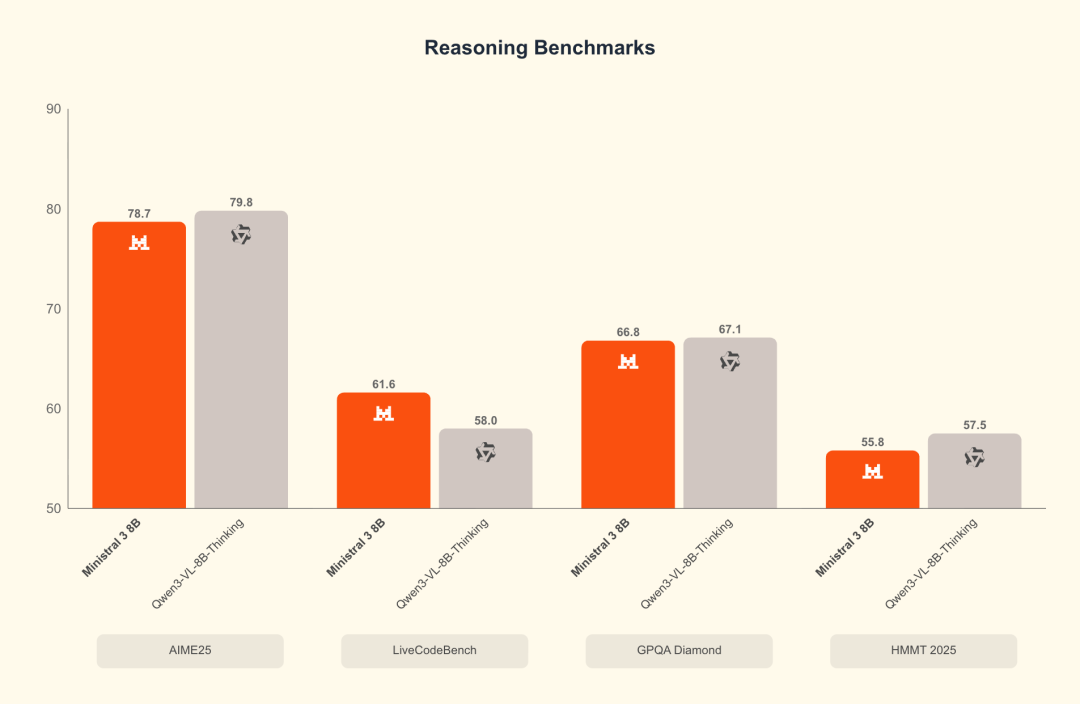
Ministral 8B benchmark: reasoning
3B 系列跑分
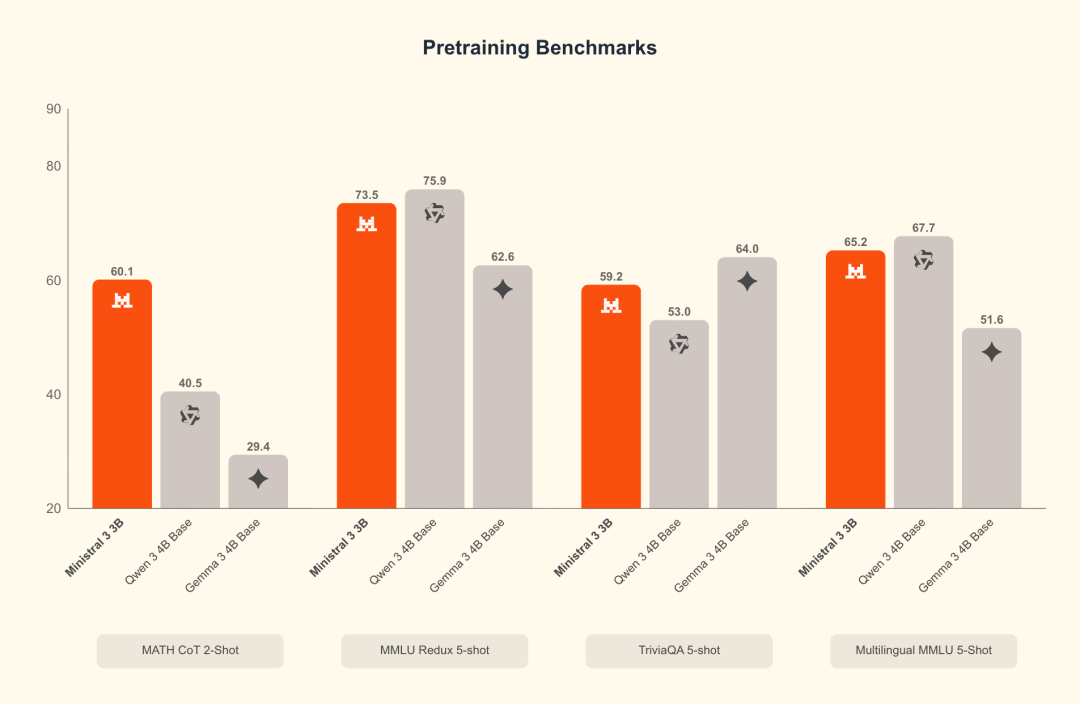
Ministral 3B benchmark: pretraining
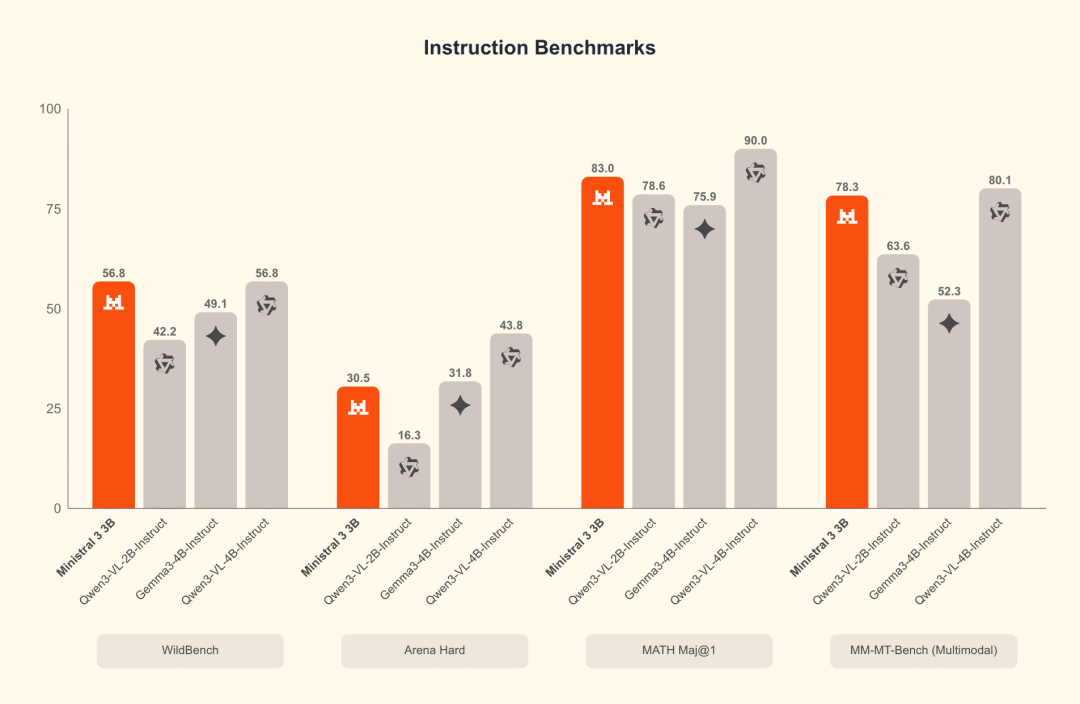
Ministral 3B benchmark: instruct
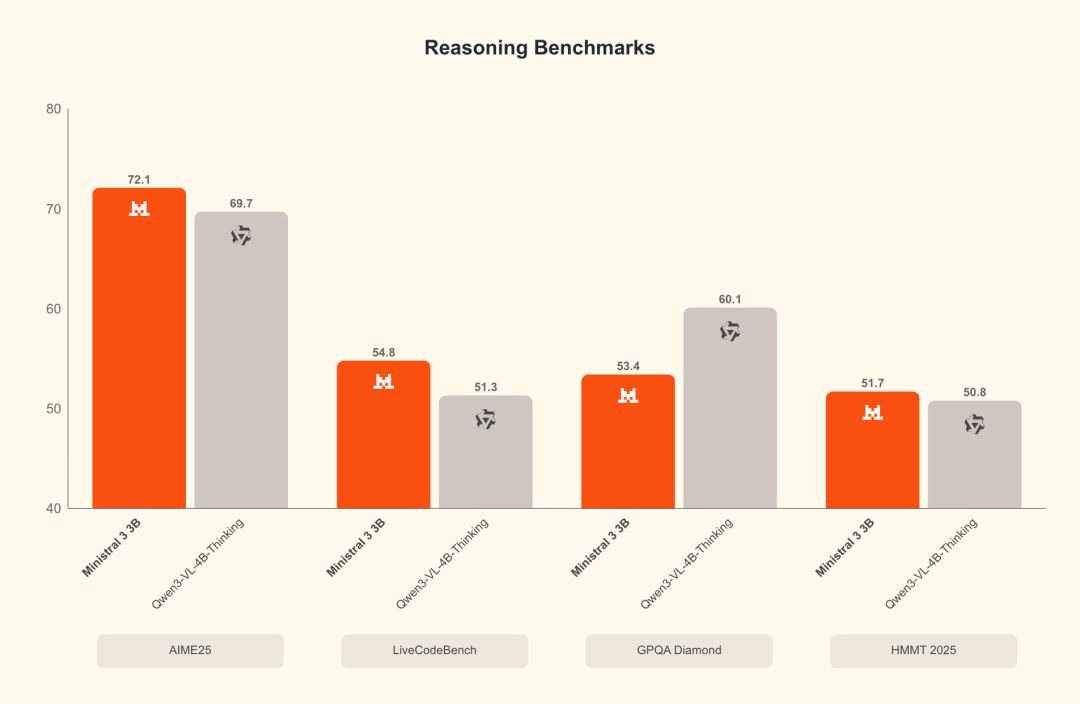
Ministral 3B benchmark: reasoning
怎么选更稳妥
| 型号 | 架构/规模 | 变体 | 能力要点 | 许可 | 部署备注 | 适合场景 |
|---|---|---|---|---|---|---|
| Mistral Large 3 | MoE,675B 总参/41B 激活 | Base;reasoning 即将推出 | 通用能力强;多语言;开源非推理榜名次靠前 | Apache 2.0 | Blackwell NVL72;亦可在 8×A100/8×H100 节点运行 | 服务器侧通用智能、复杂对话系统;等 reasoning 版再评估推理类任务 |
| Ministral 14B | dense,14B | pretrain/instruct/reasoning | 图像理解;多语言;reasoning 版在 AIME ’25 有较好成绩 | Apache 2.0 | DGX、RTX PC 等;量化后延迟较稳 | 中型后端服务;中文/多语言问答、轻量推理、研发验证 |
| Ministral 8B | dense,8B | pretrain/instruct/reasoning | 覆盖常见对话/总结;图像理解 | Apache 2.0 | RTX PC 友好;也适合边缘推理 | 应用内嵌智能、长驻对话机器人、低成本多语言支持 |
| Ministral 3B | dense,3B | pretrain/instruct/reasoning | 体量小;图像理解 | Apache 2.0 | Jetson、轻量服务器;本地化容易 | 端侧/边缘设备、离线场景、隐私敏感环境 |
部署与生态:准备程度如何
- 推理栈:与 NVIDIA、vLLM、Red Hat 做了优化,工程集成成本相对可控。
- 硬件覆盖:Large 3 面向 NVL72 等高端系统,也能在单个 8×A100 或 8×H100 节点上运行;Ministral 3/8/14B 可跑在 DGX Spark、RTX PC、Jetson 等设备上。
- 服务形态:已在主流算力平台上线 API,并提供定制训练服务;对企业侧落地较友好。
为何只对标中国模型
对比对象从 GPT/Claude/Gemini 转为 DeepSeek、Kimi,一方面说明中文与多语言开源模型已成为“现实参照系”,另一方面也意味着开源阵营内部的竞争焦点在向“可落地能力”靠拢。需要同时看到,和头部闭源模型在长期推理、工具使用等方面仍可能存在差距,实际落地要用业务数据做二次验证。
适配性建议(按场景)
- 需要通用大模型、多语言覆盖,但可接受较高硬件成本:优先评估 Mistral Large 3,reasoning 版本上线后再做推理类任务的全面对比。
- 想要在自研后端中平衡成本与能力:Ministral 14B(instruct/reasoning)是一个稳妥的起点,量化后可在常见 GPU 上部署。
- 端侧/边缘或嵌入式场景:Ministral 8B/3B 更易部署;对图像理解有一定诉求时,建议先用内部数据做几组“图+问”的小测。
- 中文与多语言:官方数据对中文/多语言给出正向信号,但领域专业性(医疗、法律、工业)仍需自建评测集验证。
- 合规与商业化:Apache 2.0 许可降低商用顾虑,但如果涉及二次训练与数据合规,仍要按企业流程完整审计。
风险与注意事项
- 评测透明度:人类评估由第三方执行,但方法学未完全公开;将其视为“趋势参考”,不要直接等同于业务表现。
- reasoning 可用性:Large 3 的 reasoning 版本尚未发布;推理类任务的最终结论需要等待正式版本。
- 榜单波动:LMArena 等公开榜单会随时间、基准和样本变化,选型时注意时间戳与评测集差异。
结语
从产品经理角度,我把 Mistral 3 看作“可落地的开源全家桶”:上有 MoE 大模型承接高通用需求,下有 14B/8B/3B 覆盖本地化和边缘部署,许可与生态准备度也比较完整。
更值得注意的是,它把对标对象换成了中国模型,这对中文与多语言应用是利好,但也提醒我们:不要只看总分,更要看是否适配你的数据与工作流。
我的建议是:先用 Ministral 14B/8B 做小范围验证,关注 Large 3 reasoning 上线后的对比,再决定是否做大规模替换或迁移。
在开源阵营竞争日趋细分的背景下,把“适合”放在“更强”之前,通常能更快落地