这好像也算不上好消息,时隔大半年,我们依然没等到DeepSeek V4或R2的上线。
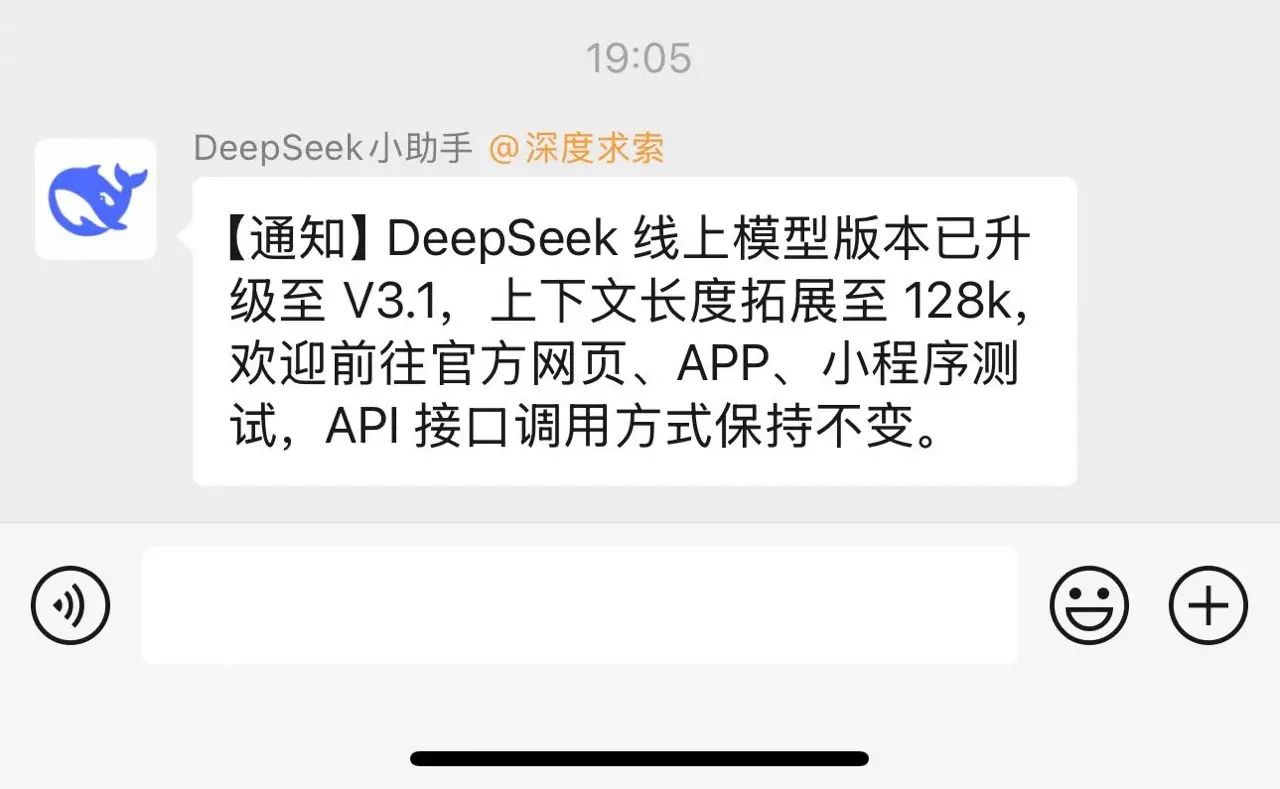
这真是一个让人又兴奋又有点无奈的消息!不过,先别急着欢呼,仔细看看,会发现这次更新有点“出乎意料”的微妙。
V4还没影子
V3.1的发布意味着什么?对我这种天天盯着大模型动态的人来说,有点像“久等的惊喜里带点失落”。自从上次版本更新到现在,已经过去大半年了,但我们仍然没有等到V4或者R2。短期内,看来也不会有重大版本更新出现。
从体验上看,V3.1的变化更像是在后训练强化学习(Post training RL)环节做了优化,而预训练语料仍停留在2024年7月。具体表现:
-
它仍然认为世界最佳大模型是GPT-4 turbo;
-
知道6月份的法网冠军,但在奥运女单冠军上出现了小幻觉;
-
编程能力没有明显提升,但处理简单非结构化提示词时已经能给出不错的效果。
所以,如果你期待一次“翻天覆地”的升级,可能得再等等。
V3.1开源来了
但就在大家稍微有点失望的时候,DeepSeek团队在Hugging Face上投下了一颗炸弹:DeepSeek-V3.1的基座模型正式开源了!没错,是V3.1,不是V4,也不是R2。这个基座模型传说拥有万亿参数,采用MoE(Mixture-of-Experts)架构,一时间整个开源社区都炸开了锅。
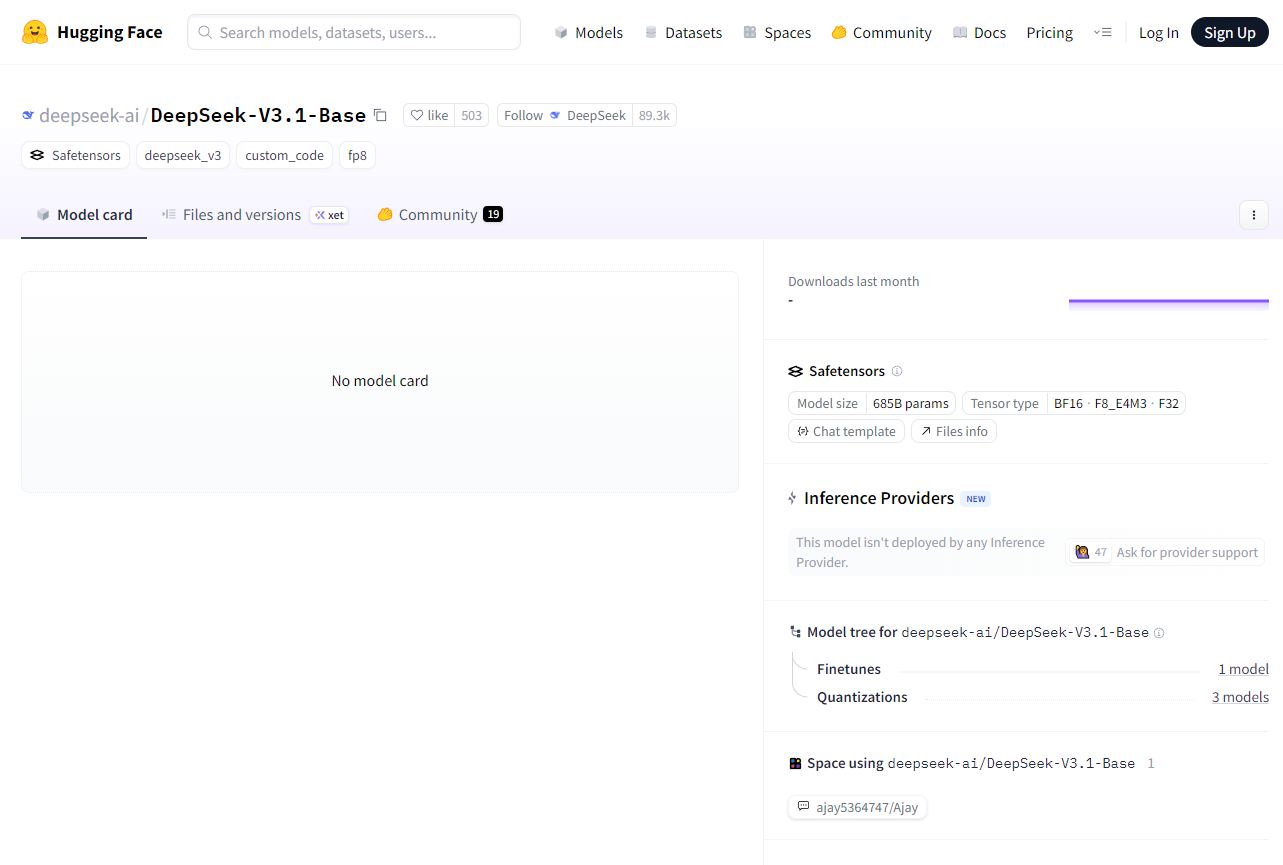
对我们开发者来说,这意味着可以在自己的项目里直接试用接近旗舰级别的模型,甚至可以研究MoE架构在真实场景下的应用和优化。
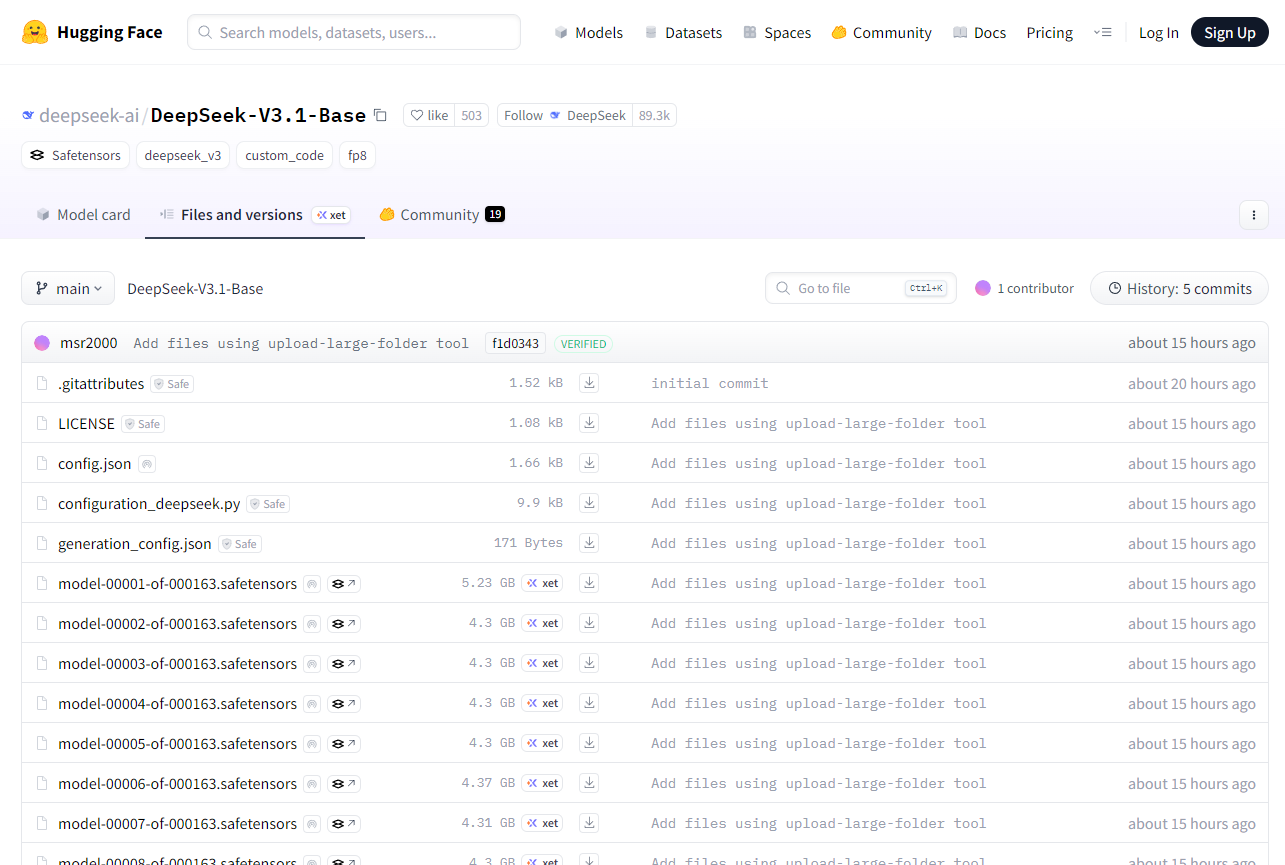
DeepSeek-V3.1-Base核心亮点
-
6850亿参数:庞大的模型规模,结合MoE架构,在复杂任务中表现出色。
-
MoE架构:只激活部分专家网络就能推理,大幅提高效率,同时降低计算成本。
-
多精度支持:BF16、F8_E4M3和F32灵活选择,尤其是FP8量化优化,让推理更高效。
-
Safetensors格式:相比传统PyTorch pickle,更安全、更快加载。
-
预设对话模板:直接应用于对话式AI场景,降低集成门槛。
-
推动开源生态:降低高性能大模型使用门槛,让学术研究、企业创新和个人开发者都能快速上手。
MoE架构,为什么值得关注?
简单来说,MoE就是把一个大模型拆成多个“小专家”,再用一个“门控网络”动态选择最合适的专家处理当前任务。优势明显:
-
参数效率:推理时只激活部分参数,节约计算资源;
-
性能提升:不同专家专注不同类型任务,多样化场景表现更好;
-
可扩展性:容易扩展到更大规模,为未来AI能力边界提供可能。
所以,这次开源的V3.1-Base,对想研究MoE的开发者和学术团队来说,是个宝贵资源。
部署与使用
目前,V3.1-Base还没有被第三方推理服务提供商部署,但估计很快就会有厂商适配。大家可以直接去Hugging Face下载和探索:
总结
作为一个每天都在折腾AI工具的产品经理,如果你和我一样喜欢折腾AI模型,不妨直接去下载V3.1-Base,亲自感受一下MoE的魅力,也许会有意想不到的收获。
你怎么看DeepSeek-V3.1的开源?评论区聊聊你的期待吧!