MiniMax 在 X 上发布预告:"M2 系列到头了,M3 要来了。"
工程负责人补充:"Tech blog coming soon. And M3 :)"。这条简短预告获得 37 万阅读、2000 多赞,社区嗅到了重要信号。

性能数据:架构级跃升
MiniMax 流出的基准测试显示,M3 对比 M2 的提升幅度:
- Prefill 速度:提升 9.7 倍
- Decoding 速度(100 万 token 上下文):提升 15.6 倍
- 100 万 token 任务延迟:从 1 秒降到 0.06 秒
以前处理超长文档可能需要等好几秒,现在几乎是瞬间。这不是调参能实现的,而是架构级的变化。
核心技术:MSA(MiniMax Sparse Attention)
M3 的核心创新叫 MSA——MiniMax Sparse Attention(稀疏注意力)。
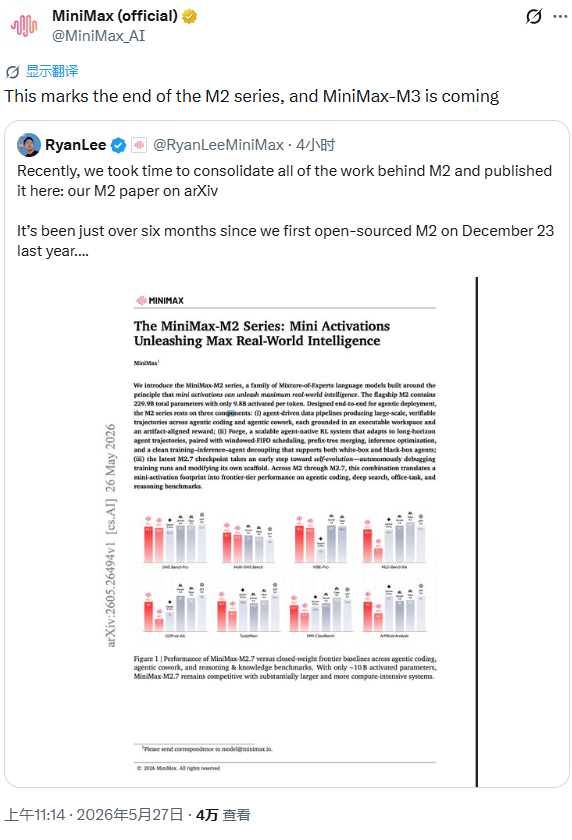
传统大模型处理长文本时,把所有内容一起计算,越长越慢。MSA 的思路是:先快速扫一遍,找出最重要的段落,然后重点计算这些区域,其他部分略过。速度快了,但该抓的重点没丢。
社区技术博主 eliebakouch 的评价广为传播(12 万阅读、696 赞):
"They didn't optimize attention, they rebuilt it from scratch."(他们没有优化注意力,他们重建了注意力。)
行业里大多数做稀疏注意力的方案是在现有架构上打补丁——加掩码、压缩维度、搞滑动窗口。MiniMax 是从零重新设计。
MSA 分两步:
- 用轻量级索引机制快速扫描全文,选出最重要的块
- 只对选出的块做精确的注意力计算
关键区别在于:它在真实数据上做注意力计算,不是在压缩后的近似值上做,信息没有损失。
与 DeepSeek 的路线对比
国内做稀疏注意力最知名的两家是 DeepSeek 和 MiniMax,但走的是完全不同的路线:
| 对比项 | DeepSeek V4 | MiniMax M3 |
|---|---|---|
| 基础架构 | MLA(多潜在注意力) | GQA(分组查询注意力) |
| 选择粒度 | block 级 | block 级 |
| 注意力对象 | 压缩后的近似值 | 真实 KV 数据 |
关键差异在最后一行:DeepSeek 在压缩过的数据上做选择,MiniMax 在原始数据上选。就像在模糊照片上找重点,不如直接看原图。
社区评价:"比 DeepSeek 的方案更干净。"另一条高赞评论:"真实 KV 注意力保留了质量——这才是正确的取舍。"
"先慢后快"的工程哲学
M2 系列用的是全注意力——不是稀疏的,是把所有内容都算一遍。M2 的 229.9 亿参数里每次推理只激活 98 亿,采用 MoE 架构,但注意力部分偏偏选了效率最低的全量计算。
MiniMax 在 M2 技术论文中解释了原因:
"We found no variant that reliably matches full attention quality in production settings."(在生产环境中,我们没有找到任何稀疏注意力变体能可靠地匹配全注意力的质量。)
翻译过来就是:他们知道稀疏注意力效率高,但当时做出来质量会下降。所以 M2 阶段故意选了慢的方式先把质量稳住。现在 MSA 被认为可以上线了,说明质量关过了,才放出来拼效率。
苏米注:这种"先质量后效率"的工程哲学,跟很多公司"先堆参数再调优"的思路完全不同。MiniMax 这次是反过来的:先告诉你能跑,再告诉你跑得快。这种纪律性在行业里不多见。
参数规模:可能是万亿级
关于 M3 的具体参数,官方尚未公布。市场传闻 M3 可能有 1 万亿参数。如果是真的,从 M2 的 229.9 亿到 1 万亿,翻了 4 倍多。
但关键不是这个数字,而是:配合 MSA 的 15.6 倍加速,万亿参数模型的推理成本可能跟 200B 参数模型差不多。大模型的经济学可能要被改写了。
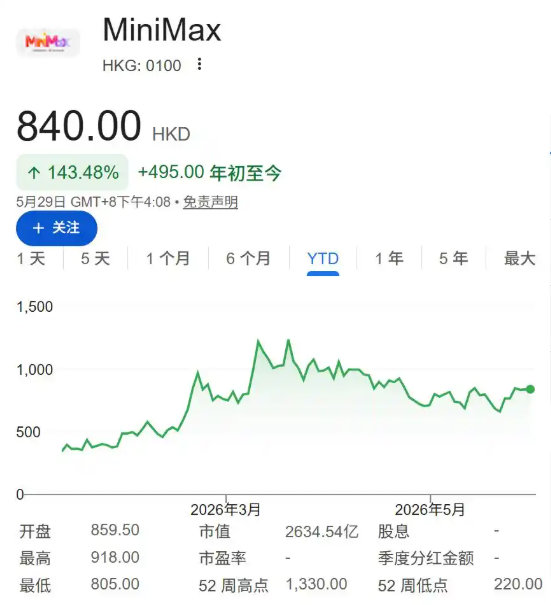
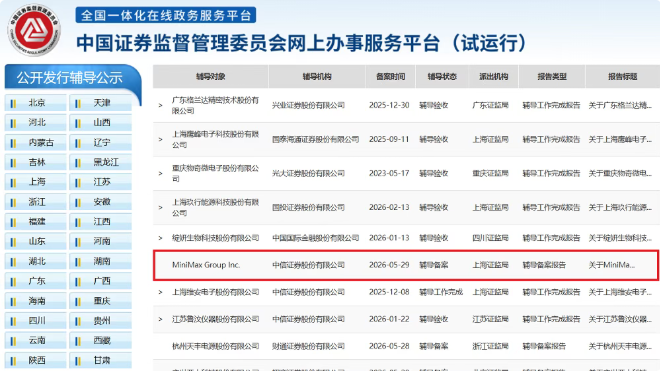
商业化进展
MiniMax 今年 1 月在港交所上市,发行价 165 港元,首日涨 109%。到 5 月底,市值 2625 亿港元,超过快手。上市才 4 个月,又启动了 A 股上市辅导。
核心财务数据:
- 2025 年营收 7900 万美元,同比 +159%
- 毛利率从 12% 提升到 25%
- 全球用户约 3 亿,企业客户突破 100 万
- ARR 最近半年翻倍,最新超过 3 亿美元
创始人闫俊杰,37 岁,中科院博士,2022 年创立。团队平均年龄 29 岁,研发占比超 70%。5 月 28 日,他出现在国新办记者见面会上——一个 AI 公司创始人站上那个平台,信号很清楚:MiniMax 已被列入"国家队"视野。
M3 不是孤立发布,MiniMax 正在搭建完整的 AI 平台:一个订阅解锁全部模型(文本、音乐、视频、语音),还有 Agent Teams、Mavis 个人 AI 助手。M3 将随模型一起开源。
竞争格局:六月是硬仗
M3 的发布时间窗口,正好赶上全球 AI 密集发布期。GPT-6 在安全对齐、Gemini 3.5 在路上、DeepSeek V4.1 下月发、Kimi K3 也在排队。
M3 有几个独特的卡位:
- 第一,开源:在闭源为主的市场里,万亿参数级别的开源模型冲击力不小
- 第二,长上下文:百万 Token 处理 + 15.6 倍加速,在长文档分析、代码库理解、多轮 Agent 对话等场景是实打实的优势
- 第三,价格:M2.7 的 API 价格已做到每百万 Token 0.22 美元,全球性价比最高之一。如果 M3 延续这个策略,行业价格战会更激烈
总结与判断
MSA 是认真的技术突破,不是噱头,有具体的数据和架构支撑。9.7 倍和 15.6 倍的提升,不是调参能搞出来的,是从底层重建的东西。
万亿参数 + 稀疏注意力,如果真成了,会改变大模型的成本曲线。推理成本下降,AI 能用到更多场景,对整个行业是好事。
开源是最大的变量。如果 M3 真的以宽松协议开源,对开源生态的冲击巨大,对开发者也是利好——不用非得付钱才能用顶级模型。
风险:多模态能力是社区反复提到的痛点。如果 M3 在这方面没有显著提升,在需要视觉、音频理解的应用场景里,还是会被 Claude 和 Gemini 压着打。
这两年 AI 圈的趋势:技术进步越来越快,但真正落地到普通人能用的产品还不够多。M3 这次瞄的方向挺实在的——长上下文、高效率、开源、性价比。这几个关键词加在一起,意思就是:让更多人用得上、用得起、用得爽。
5 月底到 6 月初,M3 就会正式发布。
苏米注:当所有人都在追求"快"的时候,有人选择先"做好"——半年后,慢的人反而跑到了前面。这种工程纪律性值得所有 AI 从业者学习。