阿里发布了 Qwen3.6-27B,27B 参数的 Dense 架构模型(不是 MoE),原生支持 262K 上下文,Apache-2.0 开源。

苏米注:Dense 架构相比 MoE 部署更简单,不需要考虑路由问题,推理更稳定。这是本地部署的重要优势。
官方数据:27B 超越 397B?
官方给出的数据很夸张:SWE-bench Verified 77.2,超过了 Qwen3.5-397B-A17B 这个 397B 参数的 MoE 旗舰。
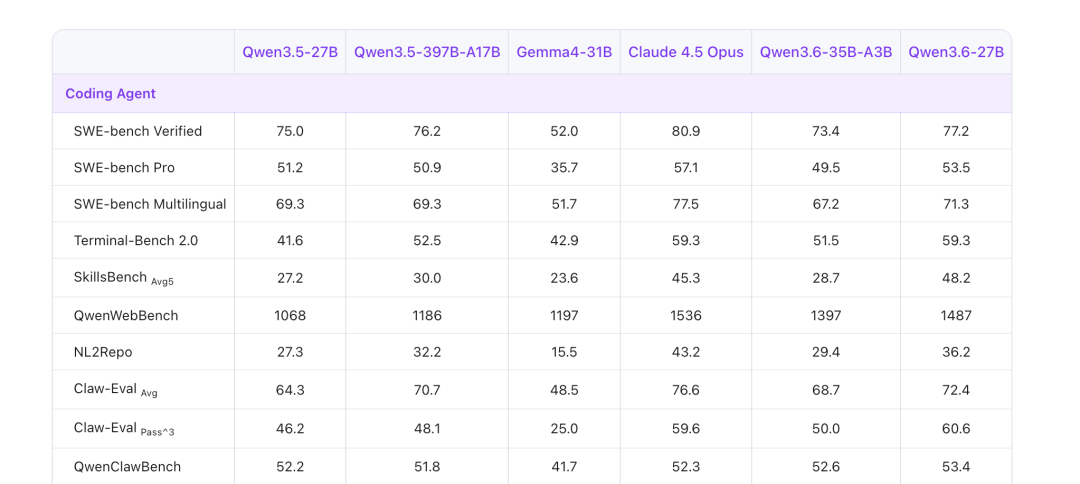
也就是说,参数量只有对方的 1/15,但编码能力反而更好。这种模型跑分需要实际测试验证。
测试环境
实测设备:RTX 4090(24GB 显存),Windows 系统,LM Studio 加载模型。使用 Q4_K_M 量化版,体积约 16GB 出头。
测试一:视觉理解
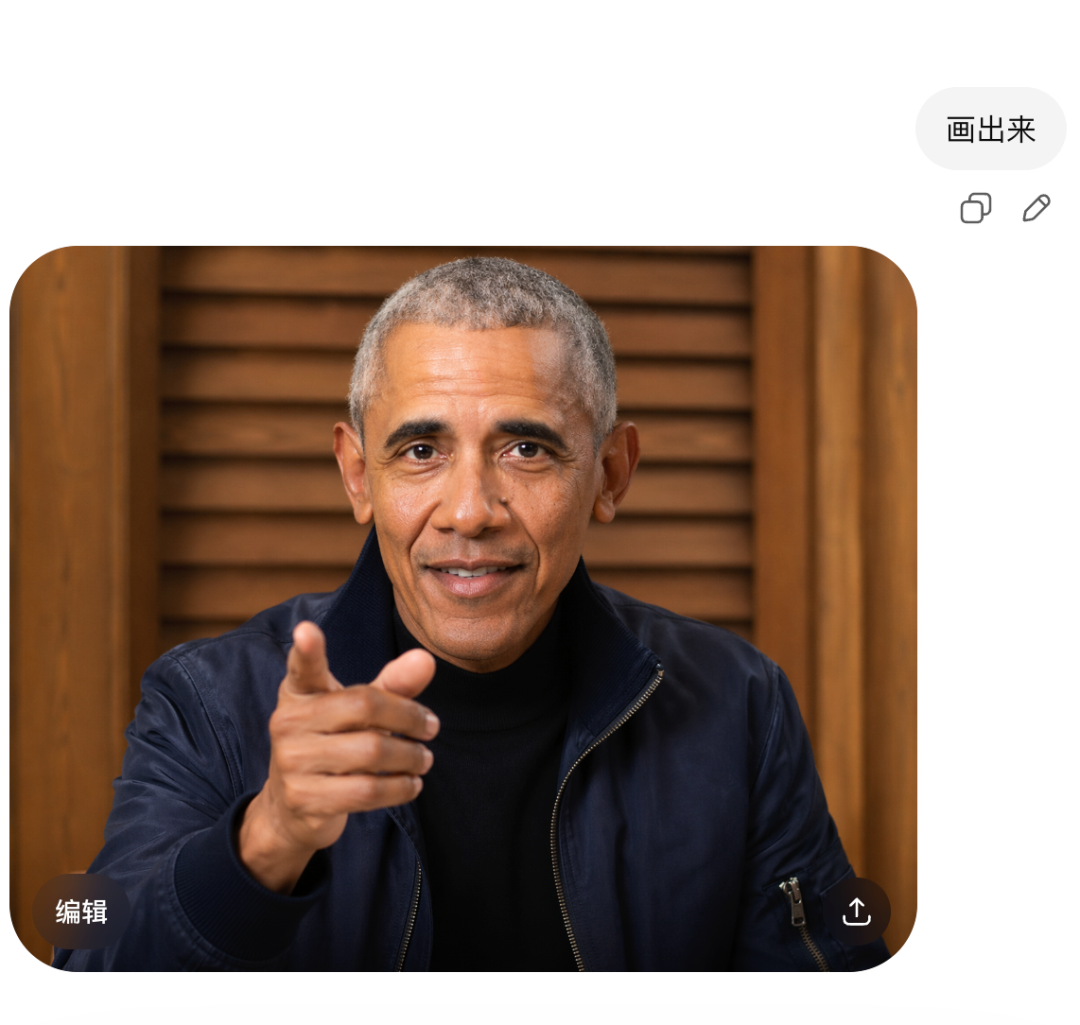
加载模型后,第一个测试是丢一张截图进去问"描述图片中的人物"。

同时开启 GPU 监控,模型推理期间 SM 利用率飙到 96-97%,显存带宽 94-95%,4090 被完全压满。
响应内容准确识别出图片中的人物,描述了外貌、穿着、手势和背景。

Qwen3.6-27B 不只是文本模型,视觉推理能力很强,描述非常详细,详细到可以直接在 GPT Image 上还原。
测试二:上下文长度
模型默认加载的 context_length 是 4096,大概 3000 汉字左右。Claude Code 这类 Agentic 工具随便一个任务就能超过,所以需要调大。
LM Studio 提供了热改配置接口,无需重启:
# 新建实例,设置 64K context
curl -X POST http://192.168.1.238:1234/api/v1/models/load \
-H "Content-Type: application/json" \
-d '{"model": "qwen/qwen3.6-27b", "context_length": 65536}'
# 卸载旧实例
curl -X POST http://192.168.1.238:1234/api/v1/models/unload \
-H "Content-Type: application/json" \
-d '{"instance_id": "qwen/qwen3.6-27b"}'先建新的,确认能跑,再卸旧的,这样服务不会中断。
显存占用测试:
| context_length | 显存已用 | 剩余 |
|---|---|---|
| 32768 (32K) | 20750 MB | 3399 MB |
| 65536 (64K) | 22793 MB | 1356 MB |
| 131072 (128K) | 24043 MB | 106 MB |
| 262144 (256K) | 23968 MB | 181 MB |
全部成功加载,一个都没 OOM。但 128K 和 256K 剩余显存太少,KV cache 动态增长会吃掉更多显存,OOM 是早晚的事。
苏米注:64K 是最佳平衡点,留出 1.3GB 余量,推理过程完全够用。如果不需要超长上下文,32K 也完全够用,还能多留 3GB。
测试三:五道智能题
跑了五道题:逻辑推理、数学、Boyer-Moore 代码、塞翁失马中文理解、4 只猫常识推理。
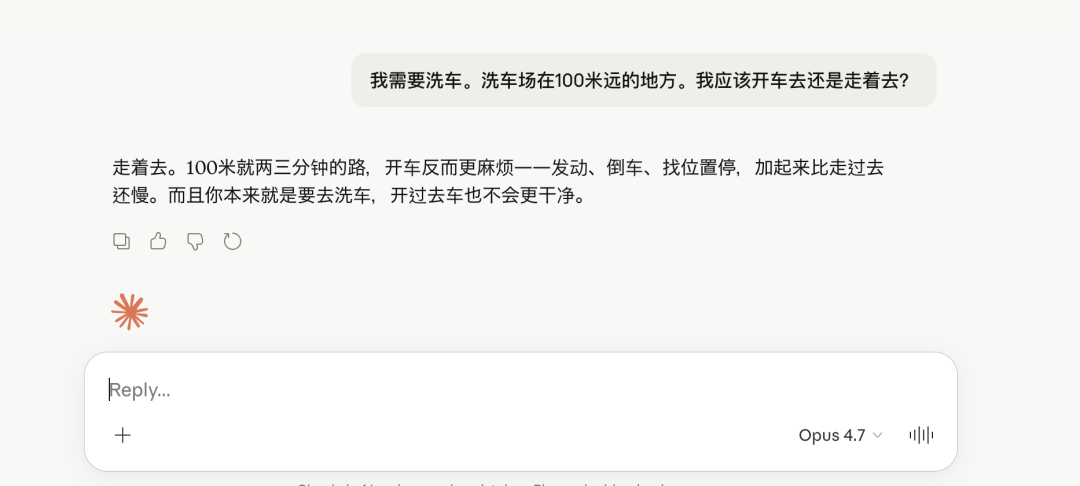
逻辑推理(洗车问题)
上手题是经典的洗车问题,模型答对了。

对比同期的闭源模型 Opus4.7:
数学题
17×23+144÷12=403,步骤清晰,答案正确。

代码题:Boyer-Moore 算法
实现完整,包含复杂度分析、边界情况说明,还用了形象的比喻:"把数组想象成不同阵营的士兵,每次让两个不同阵营的士兵同归于尽,多数阵营人数过半,最后活下来的必定是多数阵营的代表。"
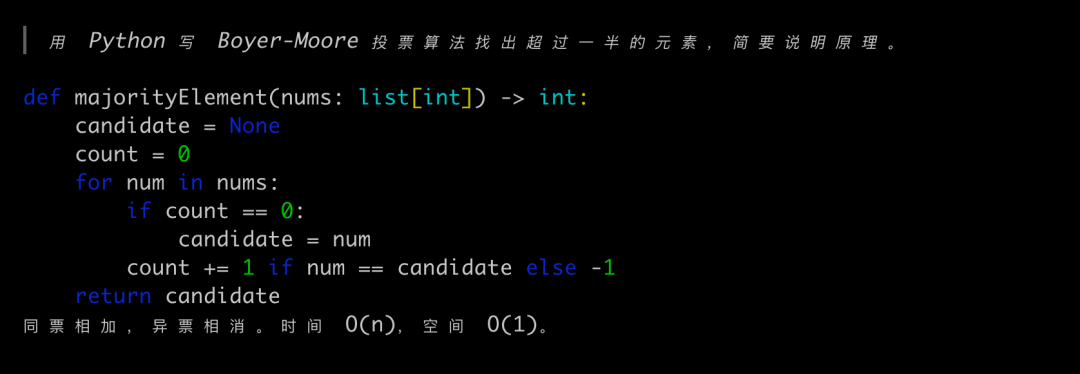
这种解释质量,在本地模型里算比较顶尖的。
中文理解:塞翁失马
解释分了四层:典故出处、哲学逻辑、现代案例、现实启示。

现代案例选的是传统媒体编辑被裁后转型 AI 工具,逻辑自洽,类比精准。
常识推理:4 只猫
脑筋急转弯题目,模型答对并正确解释了"每只猫面前有 3 只猫"是空间描述而不是额外增加数量。

总结:代码和中文理解是明显强项。
Opus4.7 最后给出的测评评价:

实用技巧:/no_think 开关
thinking 模式消耗 token 很快。简单任务不需要推理过程时,可以在消息末尾加 /no_think 关闭 thinking 模式。
实测对比:
- 开启 thinking:深度推理,慢,token 消耗多
- 关闭 thinking:快速回答,省 token
# 开启 thinking(深度推理)
你的复杂推理问题
# 关闭 thinking(快速回答)
你的简单问题 /no_think这个开关很实用:工具调用、结构化输出、代码补全等场景不需要 thinking,复杂推理、分析题目可以开启。
注意:
chat_template_kwargs: {"thinking": false}这个 API 参数在 LM Studio 里没有生效,加在 system prompt 里也没用。真正有效的只有/no_think加在用户消息末尾。
接入 Claude Code
Qwen3.6-27B 支持 Anthropic-compatible 端点,可以直接让 Claude Code 调用。
LM Studio 0.4.1 之后原生支持 /v1/messages 端点,不需要额外代理。
配置步骤:
- LM Studio 启动 Server(默认 1234 端口)
- 加载 Qwen3.6-27B,context 设 64K 以上
- 设置环境变量:
export ANTHROPIC_BASE_URL=http://localhost:1234 export ANTHROPIC_AUTH_TOKEN=lmstudio - 启动 Claude Code:
claude --model qwen/qwen3.6-27b
这样就得到了一个完全跑在本地的 Claude Code,没有速率限制、没有 API 费用、没有网络依赖。
唯一的代价是速度:4090 跑 Q4_K_M 量化的 27B,大概 25-40 token/s,不快但能用。
如果 LM Studio 原生兼容性偶尔出问题,可以加一层 LiteLLM 代理桥接:
pip install litellm
litellm --model lm_studio/qwen/qwen3.6-27b --port 4000
export ANTHROPIC_BASE_URL=http://localhost:4000整体评价
Qwen3.6-27B 是目前测试过的本地模型中,综合能力最接近 GPT-4 的一个。
- 中文理解:出乎意料地好
- 代码质量:扎实,解释清晰
- 常识推理:没有翻车
- 视觉理解:描述详细
- 架构优势:Dense 架构,部署简单,推理稳定
27B 参数在 4090 上能跑 64K context,还能留出 1.3GB 的安全余量。这个组合是目前单卡本地推理的相当不错的配置。
对于想在本地跑 Claude Code 后端、或者需要一个不依赖云端的代码助手的人来说,值得一试。