最近在浏览开源项目时,发现Agent领域的创新方向出现了有趣的分化。
大多数项目还在优化"AI怎么帮我干活"的效率问题,但有个项目MiroFish却问了一个不同的问题——"AI能帮我看清未来吗?
"这个项目在GitHub上已经积累了17000+的Star,核心思路是让成千上万个具备独立人格和记忆的AI智能体,在数字环境中自由交互和演化,通过群体涌现来进行预测推演。
核心定位与功能
MiroFish是一个基于多智能体技术的AI预测引擎,其核心机制可以概括为:

- 输入端:接收种子材料(新闻、政策文件、文本内容等)
- 处理过程:自动构建知识图谱→生成智能体人设和环境参数→并行模拟→生成预测报告
- 交互方式:支持"上帝视角"注入变量观察演化过程,模拟完成后可直接与任意智能体对话
这与传统数据建模的预测方式存在本质差异。传统方法依赖统计回归和历史数据,而MiroFish则通过让具备"思考能力"的AI在虚拟环境中运行,让预测结果从群体交互中自然涌现。
应用场景
项目官方提供的演示案例涵盖多个维度:
- 舆情推演:输入热点事件信息,模拟舆论发酵路径、公众情绪走向、关键转折节点
- 文本衍生:以《红楼梦》前80回为材料,推演后续发展走向(娱乐向应用)
- 金融分析:基于市场信号进行多智能体模拟交易演化
- 政策评估:评估政策出台可能带来的社会连锁反应
这类应用的共同特征是:需要理解复杂系统中的多方参与者行为、信息流动和群体动力学。
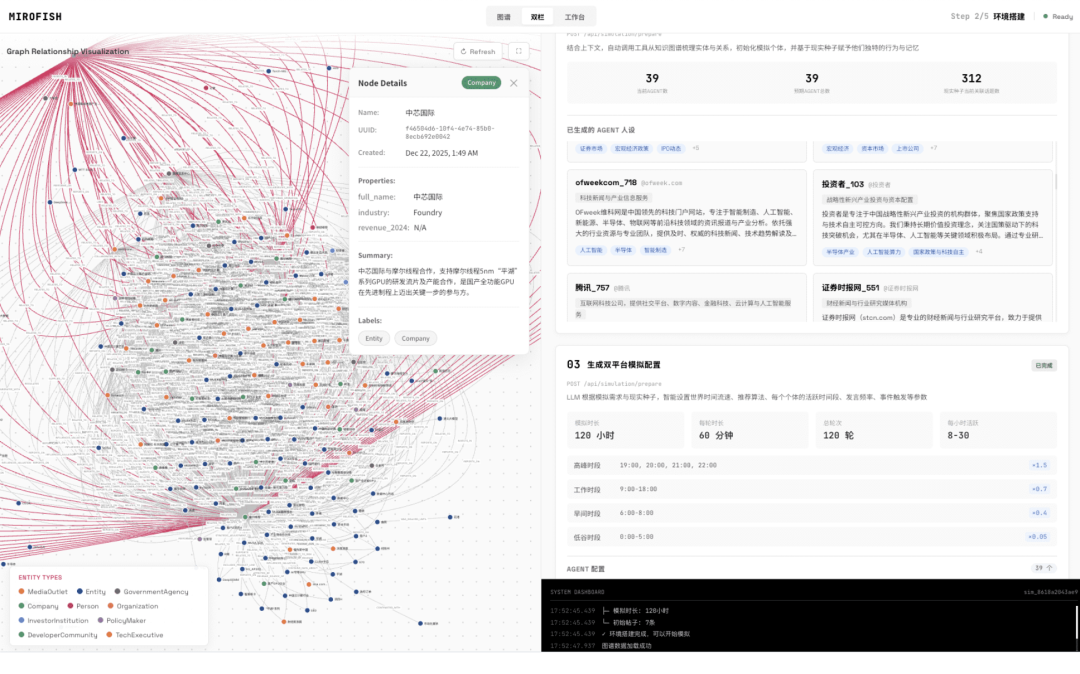
技术架构与部署
从技术栈来看,项目的设计相对轻量:
- 前端:Node.js
- 后端:Python
- LLM支持:兼容OpenAI SDK格式的模型接口,官方推荐使用阿里百炼的qwen-plus
部署流程简化到三行命令:
cp .env.example .env npm run setup:all npm run dev
前端服务运行在localhost:3000,后端API在localhost:5001。同时也支持Docker Compose一键部署,开箱即用的体验相对友好。
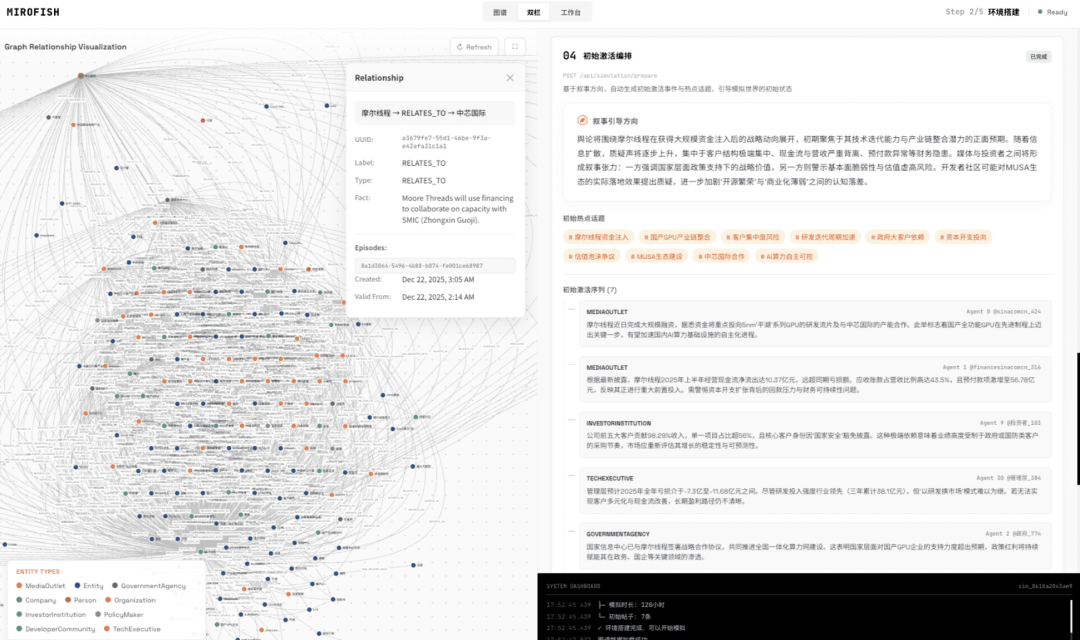
使用考量
在实际使用中需要注意几个要点:
- 成本管理:模拟过程的Token消耗较大,官方建议从小于40轮的模拟开始测试,避免高消耗成本
- 精度验证:项目仍处于早期阶段,模拟结果的精确度和可靠性需要在更多实际场景中进行验证
- 参数调优:智能体的人设生成、环境参数配置等环节的调参空间较大,需要根据具体预测场景进行优化
与同类项目的对比
在Agent应用领域,存在几个不同的技术方向:
| 项目类型 | 代表项目 | 核心定位 | 适配场景 |
| 任务执行Agent | OpenClaw等 | 自动化执行特定工作流 | 代码生成、文件管理、消息发送 |
| Coding Agent | GitHub Copilot等 | 代码级任务自动化 | 软件开发、调试、优化 |
| 群体模拟预测 | MiroFish | 多智能体系统演化预测 | 舆情分析、政策评估、复杂系统模拟 |
MiroFish的独特之处在于,它将重心从"帮助用户完成单一任务"转向"模拟复杂系统的演化过程"。这需要的技术能力不只是任务规划和执行,更需要群体行为建模和动态系统仿真。
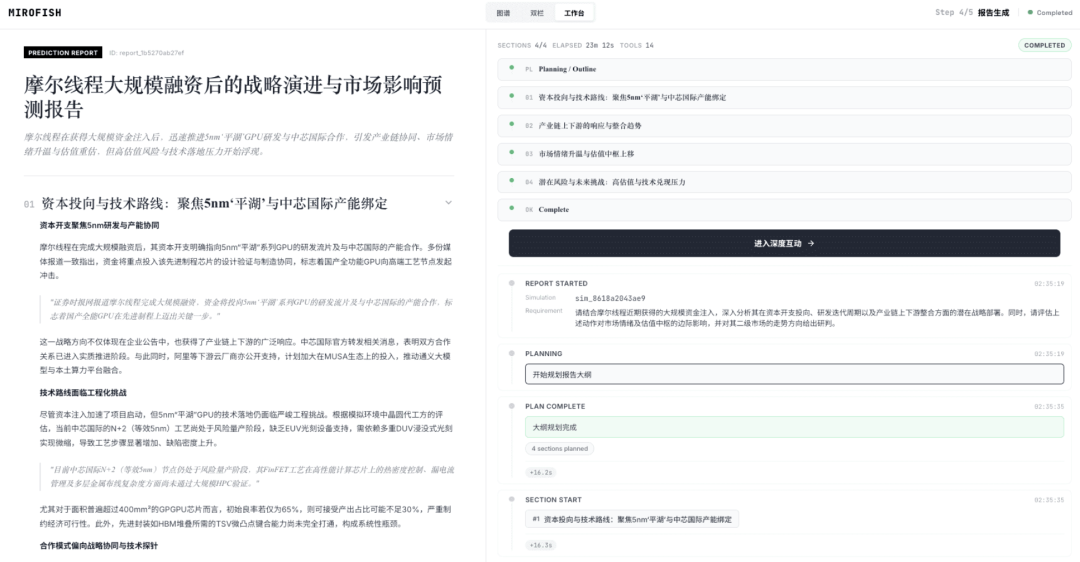
个人总结
这个项目代表了AI应用的一个有趣的演进方向。早期Agent的关注点是"AI能否提高我的工作效率",MiroFish则把问题推进到"AI能否帮我理解复杂系统的未来演化"。这两个问题本质上是同一条路的不同阶段——从执行层的自动化,到认知层的预测和决策支持。
当然,项目还需要更多的实际应用验证。模拟的精确度、可靠性和场景适配性,目前还不足以完全替代专业的预测分析。但作为一个探索性的开源项目,MiroFish提供了一个值得持续关注的思路——如何利用多智能体的群体涌现特性,去理解和预测复杂系统。