2025年6月开源的音频驱动全身视频生成模型OmniAvatar来炸场了!
炸在哪?3 步让照片开口说话,虚拟人制作成本暴跌 92%!
说实话,数字人、虚拟人这类产品咱们见得不少了,但要么制作成本高得吓人,要么就是效果僵硬得像个“木头人”。而OmniAvatar给我的感觉是,它真的把高质量数字人制作的门槛,一下子从专业级拉到了我们普通人都能摸得着的程度。
不废话,先看效果。只需要一张照片 + 一段音频 + 一句简单的指令,就能生成一个表情生动、口型精准、连身体动作都非常自然的数字人。这玩法,可比单纯的文本对话酷多了!
视频加载慢可能是网络原因,可尝试切换网络
OmniAvatar是什么?
简单来说,你可以把它理解成一个“数字人一站式生成器”。
过去我们想做个虚拟形象,得建模、绑骨骼、做动画、再对口型,一套流程下来,又贵又慢。但夸克团队把这个流程简化成了“图像+音频+文本”的傻瓜式操作。

我研究了一下它的工作流,发现它背后是一套很聪明的三阶段生成模型。你不用管复杂的技术细节,只需要知道,你扔给它的各种素材(你的照片、声音、想法),它都能很好地“吃”进去,然后融合成一个高质量的视频吐出来。
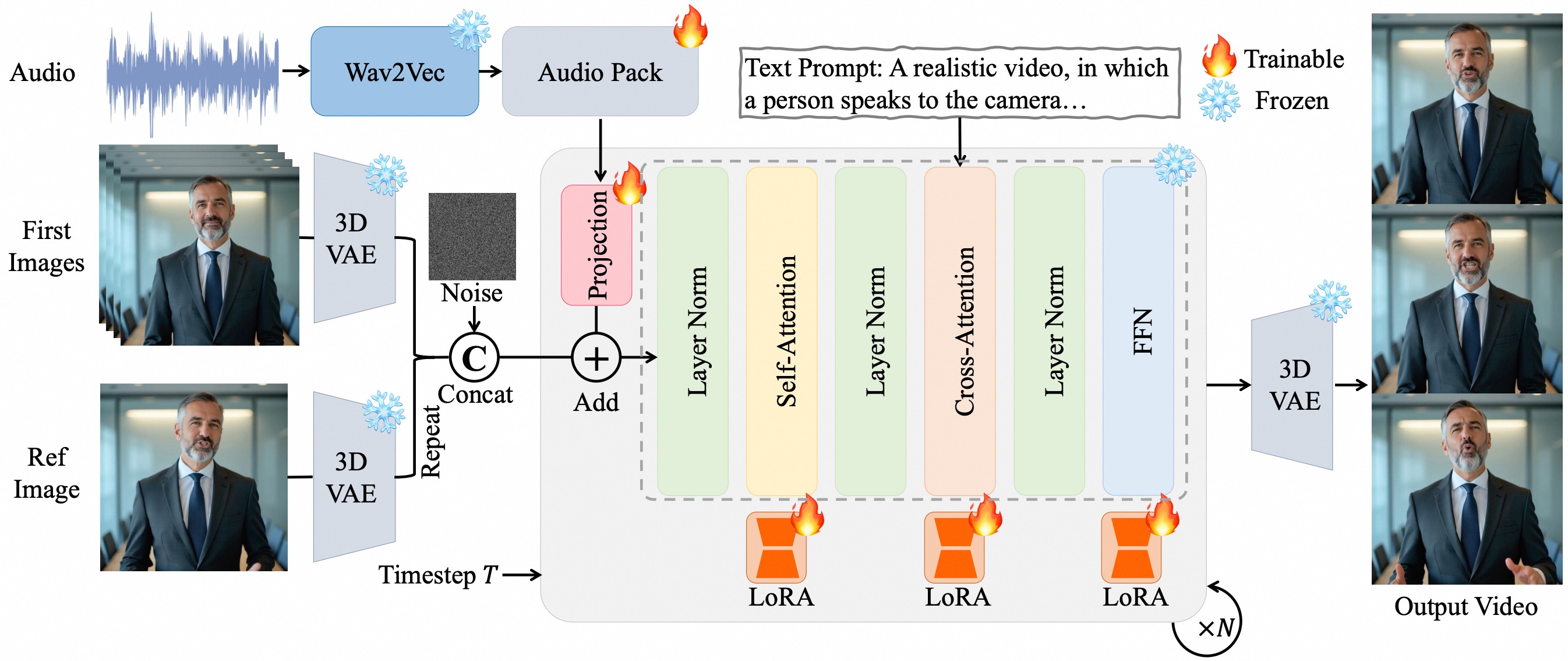
三层驱动
要说OmniAvatar最让我惊艳的地方,就是它对音频的理解能力,简直到了“变态”的级别。
它不像别的模型那样简单地把声音对上口型就完事了,而是把它拆成了三个层次来驱动整个虚拟人:
声音的“波形” → 驱动嘴唇 这个最好理解,就是我们常说的口型同步。但它做得非常精细,能捕捉到发音时嘴唇肌肉的细微变化,官方数据显示口型同步误差比主流模型低了37%,告别了以前那种“腹语式”的尴尬。
话里的“情绪” → 驱动表情 这一点开始变得好玩了!它能从你的语音里解析出情感线索。比如你用开心的语气说话,它生成的虚拟人就会眉眼带笑;如果你是在讲一个悲伤的故事,它甚至会配合着皱眉、叹气。这一下就让虚拟人有了“灵魂”。
说话的“节奏” → 驱动身体 这是最绝的!它还能根据你说话的音调起伏、抑扬顿挫,来驱动虚拟人的手势和身体姿态。比如讲到重点时会做出强调的手势,整体身体动作的流畅度提升了52%。这下,数字人彻底告别“站军姿式”的僵硬播报了。
更值得一提的是,它还用上了LoRA微调技术。用人话讲就是:咱们不用花大价钱从零开始训练模型,制作成本直接“打骨折”,据说能降低60%!这对我们这些想快速尝试新东西的个人或小团队来说,简直是天大的好消息。
官方功能演示,效果真的绝了!
光说不练假把式,我顺着官方给的示例玩了几个功能,效果真的有被震撼到。
用文字控制情绪: 我试着输入“一段悲伤的独白”,生成的虚拟人不仅声音低沉,连肩膀都在微微颤抖,那个代入感一下就上来了。
与场景自然互动: 我又让它“边弹吉他边唱歌”,本以为会很违和,结果它抱吉他的姿势、手指随节拍拨动的动作都相当自然,完全不像AI“演”出来的。
长视频不“翻车”: 以前玩AI生成视频,最怕的就是时间一长,人脸就“变异”了。OmniAvatar在这方面处理得很好,我看了一个5分多钟的视频,人物形象从头到尾都保持得非常稳定,动作衔接丝滑流畅。
多角色对话: 这个功能也很有意思,用音频的左右声道就能分别控制两个虚拟人说话。虽然目前两个角色的区分度还有待优化,但这个思路绝对是未来的方向,想象一下用它来自动生成访谈节目,效率得有多高!
未来场景落地
作为产品经理,我本能地就会想这东西能用在哪。我随便想了几个:
-
知识博主/老师: 以后做视频课程,再也不用自己出镜了。把课程音频稿扔进去,就能生成一个数字分身帮你讲课,还能同步生成多国语言口型,出海都方便了。
-
粉丝应援新玩法: 上传一张你家“爱豆”的照片,配上他的歌,就能生成一段专属的唱跳视频,这可比单纯P图有意思多了。
-
更有温度的客服: 银行、电商的智能客服,不再是冷冰冰的文字,而是一个有表情、有温度的虚拟接待员,用户体验感直接拉满!
-
会议效率神器: 开完冗长的线上会议,直接把录音丢给AI,自动生成一个虚拟主持人,配合手势帮你总结会议要点,简直不要太爽。
本地部署Or在线体验
看得心痒痒的朋友,我也把资源找来了:
代码仓库: https://github.com/Omni-Avatar/OmniAvatar
最后,也得给大家提个醒: 这个模型可不小,整个仓库超过100G,想在自己的电脑上跑起来还是有点压力的。我个人建议,可以先去官方的在线示例网站体验一下效果,有条件的朋友可以直接上云端部署,体验会更流畅。
苏米总结
总的来说,OmniAvatar给我的感觉是,它不仅仅是一个停留在实验室里的炫技项目,更是一个实实在在降低了高质量数字人生成门槛的强大工具。它让“人人都能创造自己的数字分身”这件事,离我们又近了一大步。
从内容创作、社交互动到商业服务,它的出现可能会改变很多行业的玩法。AIGC的世界,每天都有新惊喜,探索的过程真的太有趣了。